B-Bäume sind mehr als nur eine Datenstruktur – sie sind eine zentrale Komponente zur Optimierung in vielen Datenbanksystemen und spielen eine Schlüsselrolle in der Leistung und Effizienz moderner Datenbankarchitekturen. Diese Strukturen sind geschickt entworfen, um Gleichgewicht und Schnelligkeit in der Datenmanipulation zu gewährleisten. Sie sind das Rückgrat effizienter Indexierungsmechanismen.
In diesem Artikel tauchen wir tief in die Welt der B-Bäume ein, beleuchten die Details ihrer Architektur und Funktionsweise und zeigen, wie sie als Index in einem Datenbanksystem zum Zuge kommen. Beispiele sind relationale Datenbanken, LSM-Datenbanken und andere mehr.
Wenden wir uns als erstes der Frage zu, wie viele relationale und NoSQL-Datenbanken die Daten auf der Festplatte speichern. Gerade in relationalen Datenbanken sind Datenbankseiten, also DB-Pages, ein wichtiges Struktur-Element.
Datenbank Seiten (DB-Page)
Die Daten selbst werden in der Datenbank auf Seiten (Database Pages, DB-Pages) gespeichert. Die Größe der Seite kann im create table oder im create tablespace Statement definiert werden. Üblich sind Größen von 4KB, 8KB, etc 32KB. Eine DB-Page bildet eine Verwaltungseinheit.

Der Header enthält Meta-Information, beispielsweise über Anzahl Zeilen, verfügbaren Platz, Anzahl Löschungen.
Je nach Datenbank-Produkt sind im Header auch IDs und Offsets zu den entsprechenden Zeilen gespeichert – unser Bild zeigt diese Variante.
Die Inhalte einer Zeile liegen nebeneinander – wir untersuchen zeilenbasierte Datenbanken, die zur Zugriffsoptimierung einen Index benötigen.
Wird eine Zeile gelöscht, dann wird sie zuerst geflaggt. Sie belegt weiterhin Platz, bis das DBMS die Seite in sich reorganisiert. Dazu dient der leere Platz.
Die Zeilen sind über die Datenbankseiten hinweg zufällig verteilt und auch innerhalb einer Seite liegen die Zeilen ungeordnet.
Der Index in Form des B-Baumes verhilft zum schnellen Zugriff.
Ursprung und Einsatz von B-Bäumen
Der B-Baum ist eine Weiterentwicklung des Binärbaums. B-Bäume wurden von Rudolf Bayer und Edward M. McCreight in den 1970er Jahren entwickelt. Das Originalpaper veröffentlichten sie im Juli 1970 unter dem Titel “Organisation and Maintenance of Large Ordered Indices”.
Diese Datenstruktur ist darauf ausgelegt, die effiziente Verwaltung und Abfrage großer Datenmengen zu ermöglichen.
Die Namensgebung und die Definition sind nicht eindeutig. B-Bäume werden manchmal auch B+-Bäume oder B*-Bäume genannt. Je nach Autor sind auch die Definitionen leicht unterschiedlich. Wir halten uns hier an die Definition von Bayer und McCreight.
Werfen wir zuerst einen Blick auf die Struktur eines B-Baumes:
Grundstruktur eines B-Baums
Ein B-Baum ist eine hierarchische Baumstruktur, die aus Knoten und Blättern besteht. Die Knoten dienen als Indexeinträge und verweisen auf die Blätter, in denen die tatsächlichen Daten gespeichert sind. Hier sind einige wichtige Merkmale eines B-Baums.
Knoten: Jeder Knoten im B-Baum enthält eine geordnete Liste von Wegweiser-Schlüsseln und Zeigern auf die darunter liegenden Knoten oder Blätter. Die Anzahl der Schlüssel in einem Knoten kann variabel sein, aber sie liegt normalerweise zwischen einem Minimum (z.B. d/2) und einem Maximum (d, wobei d die Ordnung des Baums ist). Ist m die Anzahl vorhandener Schlüssel auf einem Knoten, dann gibt es dazu m+1 Zeiger zu Nachfolgerkonten.
Blätter: Die Blätter des B-Baums enthalten tatsächliche Daten oder Verweise auf Datensätze in einer Datenbank oder einem Dateisystem. Die Blätter sind in einer sortierten Reihenfolge angeordnet und sind über doppelt verkettete Listen miteinander verbunden.
Ordnung des Baums: Die Ordnung eines B-Baums ist die maximale Anzahl von Schlüsseln, die in einem Knoten gespeichert werden können. Sie beeinflusst die Höhe des Baums und somit die Geschwindigkeit von Suchoperationen.

In einem Datenbanksystem werden weit mehr als 4 Schlüssel auf einem Knoten Platz finden. Die Knoten werden so organisiert, dass sie eine Index-Seite belegen.
Einsatz eines B-Baums
Wir illustrieren den Einsatz eines B-Baum-Index mit einem konkreten Beispiel. Dabei gehen wir aus von einer Tabelle mit der Bezeichnung Personen und zwei Spalten PersonenId und Vorname.
Wir lassen uns den Inhalt ausgeben mit select * from Personen und erhalten das folgende Ergebnis:

Ohne order by Klausel wird das Ergebnis unsortiert dargestellt. Das DBMS scannt die DB-Seiten und gibt die Ergebnisse der Reihe nach aus.
Suchen wir jetzt nach dem Vornamen einer bestimmten Person, beispielsweise mit PersonenId=35, dann wird das DBMS ebenfalls die DB-Seiten scannen, bis es die gesuchte Zeile findet. Ist diese nicht vorhanden, dann scannt das DBMS sämtliche DB-Seiten bis zum Ende.
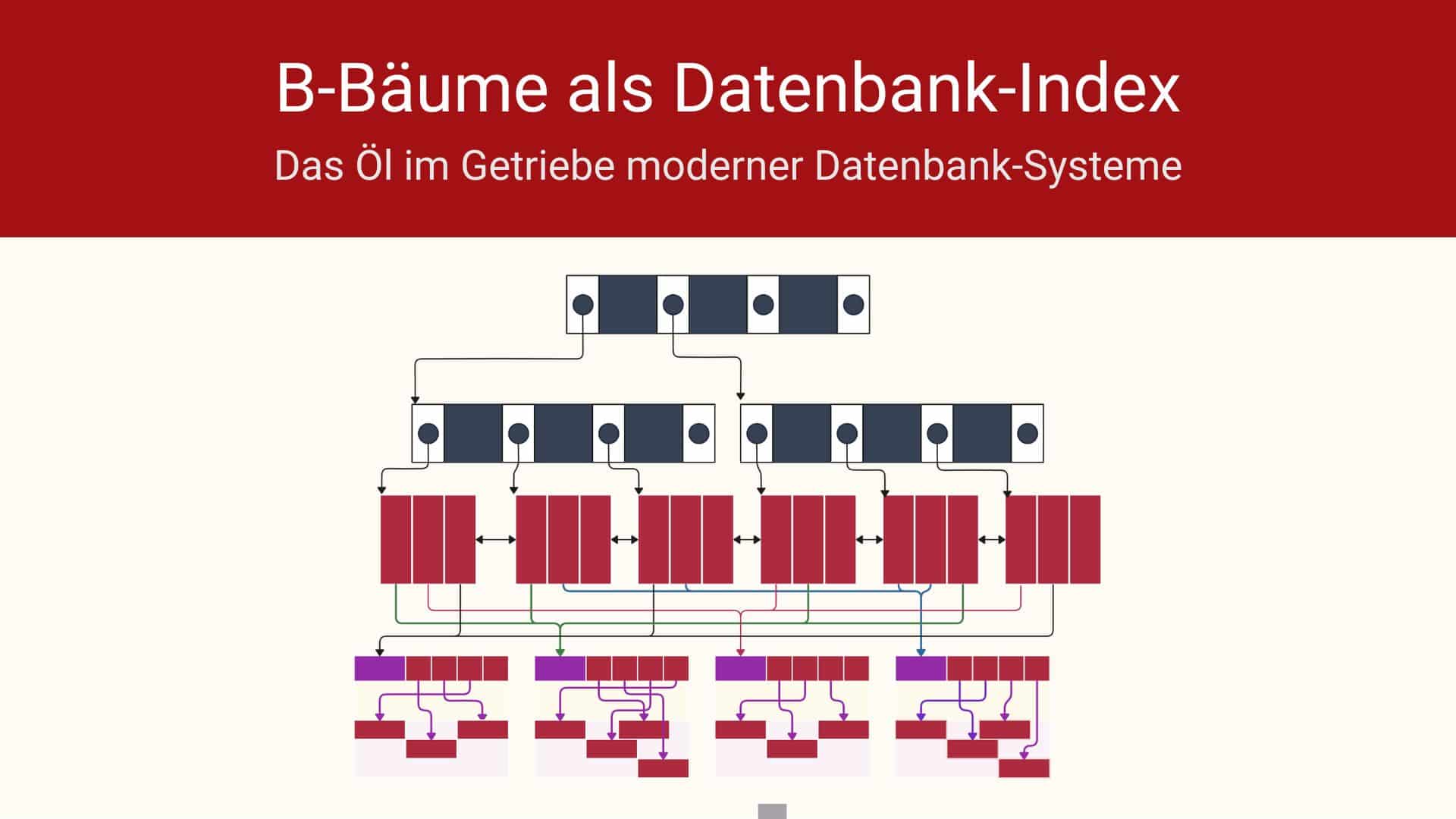
Dieser Full Table Scan ist gerade in großen Tabellen nicht performant. Hier kommen Indizes zum Zug. Das folgende Bild zeigt die schematische Darstellung eines B-Baum-Indexes der Ordnung 3 über die Beispieltabelle:

Die Anordnung der Schlüssel und Zeiger geht Hand in Hand mit dem Suchalgorithmus. Suchen wir in dieser Darstellung nach dem Vornamen der Person mit Id 35.
- Wir suchen das Wurzelelement im Memory, ist es nicht vorhanden, lesen wir den entsprechenden Block von der Festplatte.
- Wir fragen den ersten Wegweiser-Schlüssel: Ist 35 < 42? Das trifft zu und so folgen wir dem linken Pointer.
- Wir suchen die entsprechende DB-Seite im Memory, ist sie nicht vorhanden, dann lesen wir sie von der Festplatte ein.
- Hier fragen wir erneut
- Ist 35 < 13 nein – wir fragen den nächsten Wegweiser-Schlüssel im Knoten
- Ist 35 < 22 nein
- Da der nächste Wegweiser-Schlüssel unbelegt ist, folgen wir dem rechten Pointer.
- Damit gelangen wir schon zum Blattknoten, auch diesen suchen wir im Memory. Ist er nicht vorhanden, dann lesen wir diesen von der Festplatte.
- Jetzt traversieren wir diesen Blattknoten, in dem die Elemente sortiert sind, solange der Eintrag im Blattelement <=35 ist.
- Finden wir das gesuchte Element, dann folgen wir dem Pointer in die Datenbankseite. Diese holen wir von der Festplatte und durchsuchen die Liste im Header nach PersonenId=35. Dort finden wir das Offset in der gesuchten Zeile und können jetzt den zugehörenden Vornamen lesen.
Optimierung mit B-Baum Index
Gerade in großen Tabellen wird der Zugriff auf ein bestimmtes Element massiv beschleunigt. Um im Index zum Blattknoten zu gelangen, benötigen wir logd+1(n) Zugriffe, plus einen Zugriff auf die DB-Page. Das ist sehr viel weniger Festplattenzugriffe als ein Full Table Scan, was sich in einem signifikaten Zeitgewinn auszahlt.
Insert und Delete in B-Bäumen
In normalen binären Bäumen beobachten wir, dass sie sehr schnell aus der Balance geraten, wenn Veränderungen vorgenommen werden. Damit verlieren wir die guten Eigenschaften eines Suchbaums, weil es zu nachteilig langen Suchpfaden kommen kann.
B-Bäume sind so konstruiert, dass sie immer balanciert sind und auch so, dass alle Blattknoten dieselbe Tiefe haben.
Der Füllgrad der einzelnen inneren Knoten ermöglicht das. Ein innerer Knoten hat zwischen d/2 und d Einträgen – wobei d die Ordnung ist. Dasselbe gilt für die Blattknoten.
Einfügen eines Elements in einen B-Baum
Diese Flexibilität im Füllgrad ermöglicht es oft, neue Elemente einzufügen, ohne den Baum reorganisieren zu müssen. Wird ein Element eingefügt und einer der Knoten überläuft, dann wird er in zwei Knoten aufgespalten bevor das neue Element wird. Die Aufspaltung in zwei Knoten wird nach oben propagiert. Der übergeordnete Knoten hat vielleicht noch genug Platz für den neuen Wegweiser-Schlüssel. Falls nicht, dann wird auch dieser in zwei Knoten aufgespalten und die Veränderung wird nach oben propagiert.
Löschen eines Elements aus einem B-Baum
Soll ein Element gelöscht werden, dann wird dieses zuerst gesucht. Wird es gefunden, dann kann es in den meisten Fällen einfach aus dem Blattknoten entfernt werden.
Wir sehen, dass dies dazu führen kann, dass in den inneren Knoten Wegweiser-Schlüssel stehen können, die in den Blattknoten nicht mehr vorkommen. Sie bleiben so lange stehen, bis reorganisiert werden muss. Das kommt beim Einfügen vor, wie wir oben gesehen haben und es kommt auch beim Löschen vor und zwar dann, wenn in einem inneren Knoten oder in einem Blattknoten weniger als d/2 Elemente verbleiben.
Dann werden von den Nachbarknoten Elemente ausgeliehen. Es gibt verschiedene Algorithmen, wie das genau erreicht werden kann. Üblicherweise werden die Elemente mit dem linken Knoten verschmolzen – gibt es keinen linken Knoten, dann wird der rechte Knoten beigezogen. Diese Wegweiser im übergeordneten Knoten werden nachgeführt. Enthält der verschmolzene Knoten mehr als d Elemente, dann wird er in zwei gleich große Knoten aufgeteilt und die Infos über die neuen Wegweiser werden nach oben weitergegeben.
Dieser variable Füllgrad erlaubt es in vielen Fällen insert und delete-Operationen vorzunehmen, ohne dass gleich der ganze Baum reorganisiert werden muss.
Vorteile von B-Bäumen
Warum überhaupt sind B-Bäume im Data Engineering so wichtig? Hier einige Beispiele:
Effiziente Suche dank B-Tree-Index
Wie auch in binären Bäumen werden in B-Bäumen die Suchanfragen in logarithmischer Zeit verarbeitet. Um präzise zu sein, die maximale Anzahl Zugriffe um den Knoten mit dem gesuchten Element zu finden, beträgt O(log(n)), wobei n die Anzahl Knoten sind. Das ist viel effizienter, als die lineare Suche über alle Datenbankseiten.
Bereichsanfragen dank B-Index
B-Bäume sind ideal für Bereichsanfragen, bei denen Sie Datensätze in einem bestimmten Wertebereich suchen. Das verdanken wir der Eigenschaft, dass die Blätter sortiert sind und in einer doppelt verketteten Liste vorliegen.
Das DBMS such den Startwert in der doppelt verketteten Liste der Blattknoten und traversiert einfach die Blätter, bis der Endwert erreicht ist. Enthalten die Blätter zusätzlich alle Daten, die abgefragt werden, dann erfolgt nicht einmal ein Zugriff auf die Datenbank-Seiten.
Sortierung und Indexierung mit Hilfe von B-Bäumen
Die Tatsache, dass die Blätter alle Datenwerte in sortierter Reihenfolge enthalten, kommt auch beim sortieren der Ergebnisse bei Datenbankabfragen gelegen, natürlich nur dann, wenn das Sortierkriterium dem Indexierungskriterum entspricht.
Beispielanwendung: B-Bäume in der Praxis
Relationale Systeme legen automatisch einen B+-Baum für den Primär-Schlüssel und für alle Fremdschlüssel an. Mit create index können wir über jede Spalte einen zusätzlichen Index legen und damit kritische Suchanfragen – also langsame select-Statements – optimieren.
Hier ein Beispiel: Um die Bedeutung von B-Bäumen in der Praxis zu verdeutlichen, werfen wir einen Blick auf eine typische Anwendung: eine Kundendatenbank.
Stellen wir uns vor, wir haben eine Kundendatenbank mit Hunderttausenden von Kunden, und wir möchten nach Kunden suchen, die in einem bestimmten Postleitzahlenbereich leben. Dank eines B-Baums als Index über der Spalte ‘Postleistzahl’ können wir diese Abfrage in kürzester Zeit durchführen, unabhängig von der Größe der Datenbank.
Der Index-Baum führt uns schnell zu den relevanten Datensätzen, ohne unnötige Daten zu durchsuchen:
Das Datenbanksystem steigt beim Wurzel-Element des Baumes ein und sucht nach dem kleinsten Wert im Postleitzahlenbereich. Das sind O(log n) Operationen. Ab hier profitiert das System davon, dass die Werte des Indexes, also die Postleitzahlen, in den Blattknoten als doppelt verkettete Liste vorliegt. Jetzt werden die Blattknoten gescannt und zwar so lange, bis der höchste Wert des gesuchten Postleitzahlenbereichs überschritten wird.
Fazit
B-Bäume werden gerne als Suchbäume eingesetzt gerade in Datenbanken, die eine Bereichssuche erlauben. Das ist in allen relationalen Datenbanken der Fall und auch in vielen NoSQL-Datenbanken. Zudem erlauben B-Bäume relativ sparsame insert- und delete-Operationen.
Dieser Artikel ist ein Auszug aus dem E-Book “Datenstrukturen für Data Engineers”




















