“Big Data – das sind doch die 3V?”, oder waren es 4V? Es ist nicht mehr einfach, nachzuvollziehen, woher diese ‘Definition’ ursprünglich stammt. Im September 2012 wurde die Frage gar wissenschaftlich untersucht.
Diesen Anspruch erhebe ich hier nicht. Vielmehr werfe ich einen Blick zurück auf den mehr als 20-jährigen Versuch einer Definition des Begriffs ‘Big Data’ und aktualisiere die Definition.
Inhalt
‘Big Data’: (Versuche von) Definitionen
Was sind Massendaten?
Was bedeutet ‘Big Data = 3V’?
Big Data als Grenze des Machbaren
Der Duden definiert auch
Die Wikipedia-Definition
Fazit
Big Data – 20 Jahre später
Die Parallele zur Baustelle
Koordination ist der Schlüsselpunkt
Die aktualisierte Definition
Kommentar zur Definition
‘Big Data’: (Versuche von) Definitionen
Der Begriff ‘Big Data’ hat sich in den allgemeinen Sprachgebrauch geschlichen, ohne scharf definiert zu sein.
Was sind Massendaten?
Das deutsche Wort ‘Massendaten’ hilft auch nicht weiter. Liegen Daten auf IT-Systemen denn nicht immer in ‘Massen’ vor? Ab wann darf man von einer ‘Masse’ sprechen? Ab wann ist ‘big’ wirklich ‘big’?
Was bedeutet ‘Big Data = 3V’?

Die 3V mit denen ‘Big Data’ oft definiert wird, erwähnte oder prägte Doug Laney schon im Februar 2001 in seinem Paper ‘Application Delivery Strategies’, das er bei Meta Group veröffentlichte.
Die 3V stehen für Volumen, Velocity, Variety.
Gemeint sind: große Datenvolumen, große Query-Volumen, große Mengen an Datenquellen. Doch was bedeutet ‘groß’?
Velocity steht für ‘Geschwindigkeit’ – Daten, die schnell eintreffen, die schnell verarbeitet und analysiert werden sollen, Daten, die schnell wachsen. Doch was bedeutet ‘schnell’.
Variety steht für ‘Vielfalt’ – Daten die in vielfältigen Formaten vorliegen, die aus vielfältigen Quellen stammen. Doch trifft das nicht auf alle ‘Daten’ zu?
Die Definition ‘Big Data = 3V’ ist also nicht weiterführend.
Das hilft auch nichts, wenn weitere V-Wörter zu finden. Für ‘Veracity’, ‘Value’, ‘Variability’ – je nach Autor sind in den vergangenen Jahren noch beliebige ‘V’ dazu gekommen und finden auch Eingang in die Lehrbücher.
Diese Begriffe sind eher vage formulierte Anforderungen an ein Datenverarbeitungssystem, als Definitionen mit technischem Hintergrund.
Big Data als Grenze des Machbaren

Es gibt noch weitere Definitionen: Gualtiery schreibt bei Forrester in 2012 in seinem Blog-Post mit dem Titel ‘Forget about the 3 Vs‘
Big Data sei die Grenze der Fähigkeit einer Firma, alle Daten zu speichern, zu verarbeiten und im Zugriff zu haben, die sie benötigt, um zu handeln, zu entscheiden, Risiken zu minimieren und Kunden zu bedienen.
Big Data wird also als Grenze bezeichnet, etwas tun zu können. Doch was passiert jenseits dieser Grenze? Was müssen die Unternehmen tun, wenn sie an diese Grenze stoßen. Das sagt die Definition nicht und der Blog Post auch nicht.
Es ist eher eine philosophische Betrachtung des Mengenbegriffs:
- Frage: ab welcher Menge sprechen wir von ‘big’ Data.
- Antwort von Gualitieri: Sobald ein Unternehmen mit der Menge seiner Daten nicht mehr zurecht kommt.
Der Duden definiert auch
Selbst der Duden definiert Big Data = Technologien zur Verarbeitung und Auswertung riesiger Datenmengen.
Ab wann eine Datenmenge als ‘riesig’ zu bezeichnen ist, erläutert Duden nicht.
Die Wikipedia-Definition
Fragen wir also Wikipedia. Hier werden verschiedene Definitionen angeboten. Beispielsweise diese:
Begriff Big Data [ˈbɪɡ ˈdeɪtə] (von englisch big ‚groß‘ und data ‚Daten‘, deutsch auch Massendaten) steht in engem Zusammenhang mit dem umfassenden Prozess der Datafizierung und bezeichnet Datenmengen, welche beispielsweise zu groß, zu komplex, zu schnelllebig oder zu schwach strukturiert sind, um sie mit manuellen und herkömmlichen Methoden der Datenverarbeitung auszuwerten..
Quelle: Wikipedia
‘Manuell’ ist hoffentlich ironisch gemeint. Und was sind ‘herkömmliche Methoden’?
Fazit
Keine der Definitionen hilft weiter.
Big Data – 20 Jahre später
Der Begriff ‘Big Data’ mit seinen verschiedenen Definitionsversuchen geistert schon seit mehr als 20 Jahren herum. Grund genug, nach Gemeinsamkeiten zu suchen, die Tools und Technologien aufweisen, die als ‘Big Data’ bezeichnet werden.
Eine Gemeinsamkeit drängt sich auf: All diese Tools oder Frameworks sind in der Lage, die Verarbeitung und Analyse der Daten auf mehrere Rechner zu verteilen.
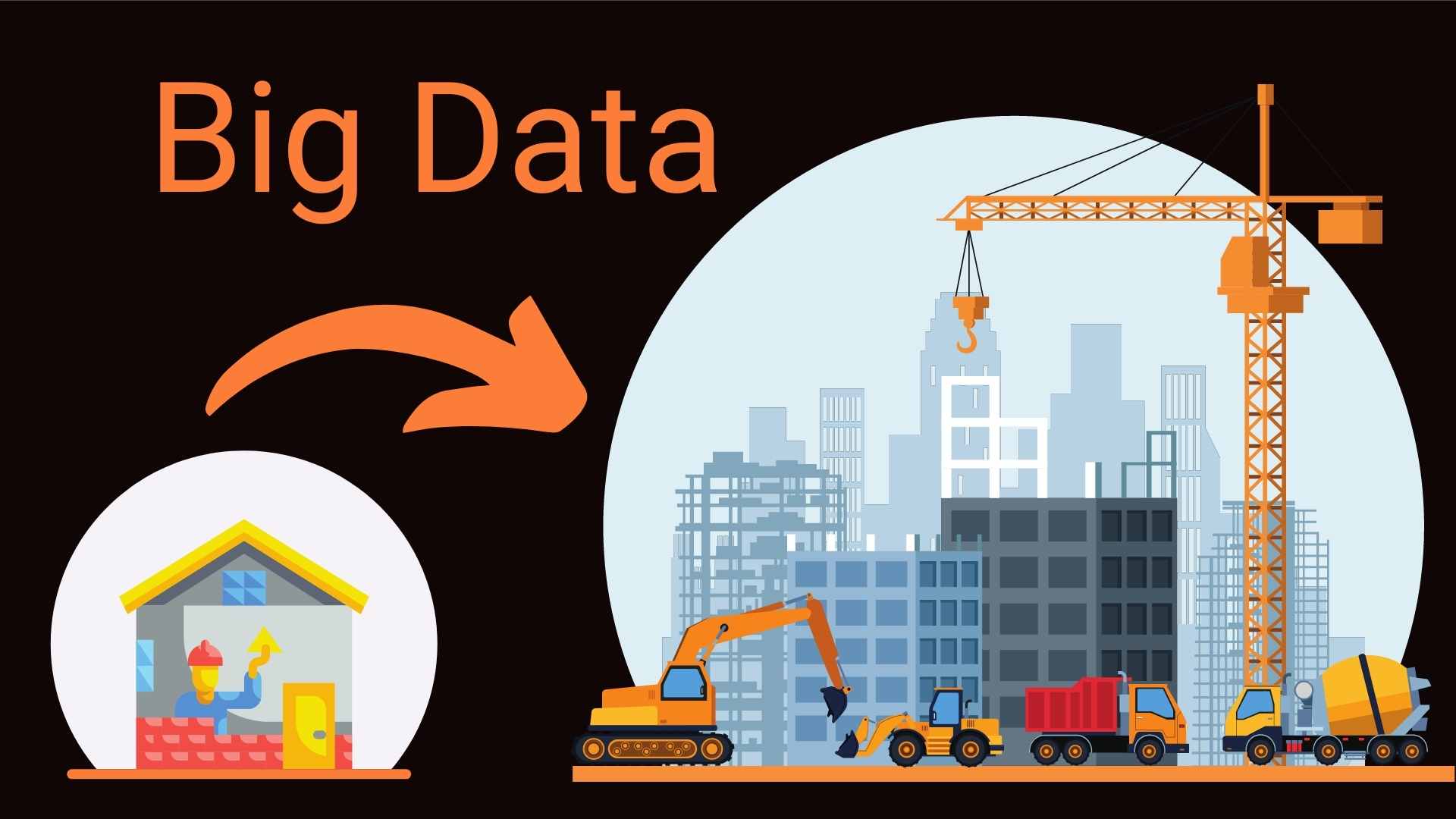
Die Parallele zur Baustelle: Arbeit verteilen
Um die Vorzüge der verteilen Berechnungen zu erläutern, bietet sich die Parallele zur Baustelle an.
Baut ein Mann allein ein Haus, dann kommt das den von Wikipedia erwähnten ‘herkömmlichen’ Methoden gleich.
Soll der Hausbau beschleunigt werden, dann gibt es zwei Möglichkeiten:
Einen kräftigeren Mann einstellen oder auch diesen mit besseren Maschinen ausstatten. Das kommt der vertikalen Skalierung (scale up) gleich, wie sie bei den herkömmtlichen Methoden der Datenverarbeitung praktiziert wird: Wir beschaffen einfach einen größeren Rechner mit mehr RAM, besserer CPU, größerer Festplatte.
Die zweite Methode zur Beschleunigung des Hausbaus: Wir setzen viele Bauarbeiter ein. Das entspricht der horizontalen Skalierung (scale out), wie sie in der Big-Data-Welt zu beobachten ist: Die Rechenlast wird auf mehrere Server verteilt und koordiniert.
Koordination ist der Schlüsselpunkt
- Die Arbeiten müssen in einer sinnvollen Reihenfolge ausgeführt werden: Das Dach kann erst gebaut werden, wenn das Gebäude steht, vorher ist es sinnlos.
- Was muss unternommen werden, wenn einer der Bauarbeiter ausfällt? Wer muss etwas unternehmen? Gibt es einen Bauführer, des das koordiniert? oder sind es die verbliebenen Arbeiter, die selbst koordinieren? Muss ein Ersatzarbeiter einspringen? Falls ja, womit fährt er weiter?
Was wir aus dem täglichen Arbeitsleben kennen, wurde übertragen auf Big-Data-Systeme. So wie es viele Ansätze gibt zur Organisation von Arbeit, zum Aufteilen einer Aufgabe auf mehrere Personen, zur Koordination der Personen, so gibt es viele Protokolle zur Koordination der Rechner im Cluster.
Statt noch immer größere Rechner zu beschaffen, wie bei den ‘herkömmlichen Methoden’ werden mehr Rechner beschafft, zu einem Cluster vernetzt, und die Arbeit wird auf mehrere Rechner aufgeteilt.
Daraus ergeben sich eine lange Liste an Herausforderungen an die Datenverarbeitung und Analyse. Und durch diese unterscheidet sich ‘Big Data’ von den ‘herkömmlichen Methoden’ der Datenverarbeitung.
Big Data – eine aktualisierte Definition
Der Begriff ‘Big Data’ bezeichnet Methoden zur Speicherung, Abfrage, Verarbeitung und Analyse von Daten mit Hilfe von verteilten und horizontal skalierbaren Systemen.
Kommentar zur Definition
Diese Definition löst sich von der Größe der Daten, denn die verteilten Methoden funktionieren bestens auch für überschaubare Datenmengen, für Daten die in einem fixen Format, und Daten, die sehr langsam oder auch nur einer Quelle eintreffen.
Und hier das große ABER:
Diese Tools und Frameworks skalieren bis zu nahezu beliebigen Größen, Mengen, Varietät an Formaten und zwar deswegen, weil sie die Arbeit in ein Cluster von Rechnern verteilen.




















