Chatbots, wie ChatGPT oder Gemini haben das Potential, unsere Arbeit zu optimieren und Prozesse zu automatisieren. Mit Prompts kommunizieren wir mit Chatbots mit natürlicher Sprache. Je präziser unsere Promts sind, desto besser sind die Antworten des Chatbots. Der folgende Artikel zeigt dir, wie du mit Personas und Wiederholungen, zwei wichtigen Prompt-Patterns, den Chatbot effektiv nutzen kannst. Das Beispiel kannst du beliebig durch eigene Anforderungen ersetzen.
Das Persona-Pattern ist eines von vielen wichtigen Prompt Patterns – andere Beispiele sind In-Context-Learning und Chain of Thought.
Personas: Die Zielgruppe definieren
Mit Personas verteilst du Rollen. Du kannst dem Chatbot eine Rolle zuweisen oder auch die Rolle der Leser der generierten Texte definieren. Wir beleuchten den zweiten Fall und definieren das Zielpublikum.
Dieser Artikel vergleicht mit ein- und dieselben Prompts das Verhalten von ChatGPT und Gemini. Der Auftrag ist immer derselbe, die Personas varieren:
- Kinder im dritten Schuljahr, die Python lernen wollen
- Jugendliche ohne Programmierkenntnisse, die Python lernen wollen
- Data Engineers mit Universitätsabschluss, die Python lernen wollen
Die Zielgruppen, also Personas, kannst du beliebig anpassen. Vielleicht ‘Junge Paare, die ihre Hochzeitsreise organisieren wollen’. Die Patterns funktionieren analog.
Der Auftrag an den Chatbot
Ist unser Auftrag zu wenig präzise, dann wird der Chatbot entsprechend diffus antworten. Der Chatbot antwortet immer.
Aus unserem Prompt berechnet er die Antwort basierend auf den statistischen Wahrscheinlichkeiten, die das Large Language Model (LLM) des Chatbots während des meist tagelangen Trainings aus einer Vielzahl von Texten gelernt hat. Entspricht die Antwort in der Form nicht unserer Erwartung, dann müssen wir den Auftrag präziser formulieren.
In unserem Beispiel lautet der Auftrag:
Verbessere den folgenden Satz:
Dazu gehört natürlich auch ein Satz zum Verbessern. Vergessen wir diesen oder ist der Prompt nicht gut formuliert, dann wird der Chatbot dennoch antworten und halt irgendetwas ‘sagen’.
Wir lassen den folgenden Satz verbessern:
Eine Schleife ist eine wiederholte Ausführung ein- und derselben Befehlsfolge.
Du kannst natürlich auch einen anderen Satz verbessern lassen. Es ist wichtig, dass er zur Persona passt, die du definiert hast. Hast du keine Persona definiert, dann wird der Chatbot den Satz auch verbessern, aber halt auf unspezifische Weise.
Beispieldialoge
Im folgenden sehen wir einige Beispieldialoge. Wir setzen ChatGPT und Gemini ein. Der Zugang zu den beiden Bots ist verlinkt:
- ChatGPT ist von OpenAI und du benötigst ein Konto. Oben links im Dialogfenster wirst du sehen welche Version verwendet wird. ChatGPT 3.5 ist kostenlos und ChatGPT kostet eine monatliche Gebühr (zum Zeitpunkt des Verfassen des Artikels sind es ca. 20 € pro Monat).
- Gemini ist der Chatbot von Google. Du benötigst ein Google-Konto. Gemini ist (zum Zeitpunkt des Verfassen des Artikels) kostenlos. Aktuell ist Gemini 1 Pro im Einsatz.
Es gibt auch viele andere Chatbots – diese beiden sind zur Zeit die mächtigsten, die in Mitteleuropa zugänglich sind und die für sich allein stehen. ChatGPT ist ja auch Bestandteil beispielsweise des Bing Copiloten.
Diese Chatbots basieren auf KI-Modellen – genauer auf Large Language Models (LLM). Diese werden aufwändig mit sehr vielen Daten erstellt.
Jedes LLM weist besondere Eigenschaften auf, je nach dem mit welchen Daten und welchem Vorgehen es trainiert wurde.
Die folgenden Dialoge sind Beispiele, um das Persona-Pattern und das Wiederholungs-Pattern zu zeigen. Wenn du die Beispiele nachvollziehst, wirst du jedes Mal eine andere Antwort erhalten – auch das ist eine Eigenschaft von ChatBots.
Vergleiche im folgenden die Antworten der Chatbots mit und ohne Personas und mit der Persona “Kinder im dritten Schuljahr, die Python lernen wollen”. Die Unterschiede sind erstaunlich – ein Klick auf den Thumbnail zeigt das Bild des Dialogs, den ich beim Schreiben des Blogposts mit den Chatbots geführt habe.

Beispiel: ChatGPT 4 – ohne Persona
Prompt:
Verbessere den folgenden Satz: Eine Schleife ist eine wiederholte Ausführung ein- und derselben Befehlsfolge.
Antwort (Beispiel):
Eine Schleife stellt die iterative Ausführung eines bestimmten Befehlssatzes dar.
Ob der Satz tatsächlich besser ist oder nur verändert wurde, liegt wohl im Auge des Betrachters.

Beispiel: Gemini – ohne Persona
Prompt:
Verbessere den folgenden Satz: Eine Schleife ist eine wiederholte Ausführung ein- und derselben Befehlsfolge.
Antwort (Beispiel):
“Eine Schleife ist eine Steuerungsanweisung, die eine Befehlsfolge so oft wiederholt, wie es eine bestimmte Bedingung erfordert. Typische Schleifen sind While-Schleifen, For-Schleifen und Do-While-Schleifen. Mit einer Schleife können Sie Befehle wiederholen, ohne sie jedes Mal neu eingeben zu müssen. Stellen Sie sich eine Schleife wie ein Fließband vor, auf dem Befehle immer wieder ausgeführt werden.”
Gemini reichert noch weitere Information an und ergänzt verschiedene Arten von Schleifen.

Beispiel: ChatGPT 3.5 – Zielgruppe: Drittklässler
Werfen wir auch einen Blick auf ChatGPT 3.5:
Prompt:
Verbessere den Satz für Kinder im dritten Schuljahr, die Python lernen wollen: Eine Schleife ist eine wiederholte Ausführung ein- und derselben Befehlsfolge.
Antwort (Beispiel):
“Eine Schleife bedeutet, dass du denselben Befehl oder dieselben Befehle immer wieder ausführst.”
Zielpublikum Drittklässler? Wohl kaum!

Beispiel: ChatGPT 4 – Zielgruppe: Drittklässler
ChatGPT 4 wurde im Vergleich zu ChatGPT 3 mit mehr Daten trainiert, länger trainiert, die Architektur wurde weiter verbessert.
Prompt:
Verbessere den Satz für Kinder im dritten Schuljahr, die Python lernen wollen: Eine Schleife ist eine wiederholte Ausführung ein- und derselben Befehlsfolge.
Antwort (Beispiel):
“Eine Schleife in Python ist wie ein Kreisel, der immer wieder die gleichen Dinge macht. Stell dir vor, du hast einen Roboter, der immer und immer wieder das Gleiche tut, bis du ihm sagst, dass er aufhören soll. So funktioniert eine Schleife. Sie hilft dem Computer, bestimmte Aufgaben viele Male hintereinander zu machen, ohne dass wir jeden Schritt einzeln aufschreiben müssen.”
ChatGPT 4 versteht Drittklässer viel besser als ChatGPT 3.5. Der Unterschied ist sehr deutlich und lässt erahnen, mit welchen Verbesserungen der LLM wir in Zukunft noch rechnen können.

Beispiel: Gemini- Zielgruppe: Drittklässler
Prompt:
Verbessere den Satz für Kinder im dritten Schuljahr, die Python lernen wollen: Eine Schleife ist eine wiederholte Ausführung ein- und derselben Befehlsfolge.
Antwort (Beispiel):
“Stellt euch vor, ihr müsst 10 Mal hintereinander “Hüpfen” sagen. Das wäre ganz schön langweilig, jedes Mal den Befehl einzeln einzugeben.
Genau dafür gibt es Schleifen in Python!
Mit einer Schleife könnt ihr einem Computer sagen, dass er einen Befehl so oft wiederholen soll, wie ihr es wollt.So könnt ihr ihm zum Beispiel sagen:
- Hüpfe 10 Mal!
- Zeige mir 5 Sterne!
- Male 3 Kreise!
Das ist viel einfacher und schneller, als den Befehl jedes Mal einzeln einzugeben. <p “>Schleifen sind also wie ein Zauberwort, mit dem ihr dem Computer sagen könnt, dass er etwas mehrmals hintereinander tun soll.
So macht das Programmieren gleich viel mehr Spaß!”
Gemini stellt sich eindeutig am besten auf Drittklässler ein!
Erläuterungen des Chatbots ein- und ausschalten
ChatGPT präsentiert uns die bare Antwort – Gemini hingegen erläutert die ‘Überlegungen’. Ich mag nicht von ‘Intelligenz’ reden, denn auch diese ‘Überlegungen’ werden aus dem Modell generiert.
Wir können dieses Verhalten ändern.
ChatGPT soll ‘Überlegungen’ geben:
Wir verändern den Prompt und fordern ChatGPT dazu auf:
Erläutere deine Verbesserungsvorschläge. Gib deinen Erläuterungen die Überschrift: “Erläuterung der Verbesserung”.
Analog fordern wir Gemini auf, uns keine Erläuterungen zu geben.
Gib keine Erklärungen aus.
Schau dir die Beispiele an:

ChatGPT 4 mit Erläuterungen – Zielgruppe: Jugendliche
Prompt:
Verbessere den Satz für Jugendliche ohne Programmierkenntnisse, die Python lernen wollen, erläutere jeweils deine Verbesserungsvorschläge. Gib deinen Erläuterungen die Überschrift “Erläuterung der Verbesserung”:
Eine Schleife ist eine wiederholte Ausführung ein- und derselben Befehlsfolge.
Antwort (Beispiel):
“In Python kannst du mit einer Schleife einen Befehl oder eine Gruppe von Befehlen immer wieder ausführen lassen, ohne sie jedes Mal neu schreiben zu müssen”.
Die Erläuterungen, die ChatGPT generiert, sind im Bild ersichtlich (Klick auf den Thumbnail links).


Gemini ohne Erläuterungen – Zielgruppe: Jugendliche
Prompt:
Verbessere den Satz für Jugendliche ohne Programmierkenntnisse, die Python lernen wollen, erläutere jeweils deine Verbesserungsvorschläge. Gib deinen Erläuterungen die Überschrift “Erläuterung der Verbesserung”:
Eine Schleife ist eine wiederholte Ausführung ein- und derselben Befehlsfolge.
Antwort (Beispiel):
“In Python kannst du mit einer Schleife einen Befehl oder eine Gruppe von Befehlen immer wieder ausführen lassen, ohne sie jedes Mal neu schreiben zu müssen”.
Die Erläuterungen, die ChatGPT generiert, sind im Bild ersichtlich (Klick auf den Thumbnail links).
Gemini generiert automatisch Varianten
In meinem Beispiel hat Gemini in einer Variante auch ein Code-Beispiel generiert. Du siehst das Ergebnis mit Klick aufs zweite Bild links.
Prompt-Dialog klar strukturieren
Je klarer wir die Struktur des Dialogs gestalten, umso mehr Möglichkeiten eröffnen sich uns, die Anforderungen noch weiter zu präzisieren.
Wir ergänzen:
- Eine Inhaltliche Überprüfung
- Den Wunsch, mehrere Sätze nacheinander verbessern zu lassen
Der Prompt für ChatGPT sieht wie folgt aus:
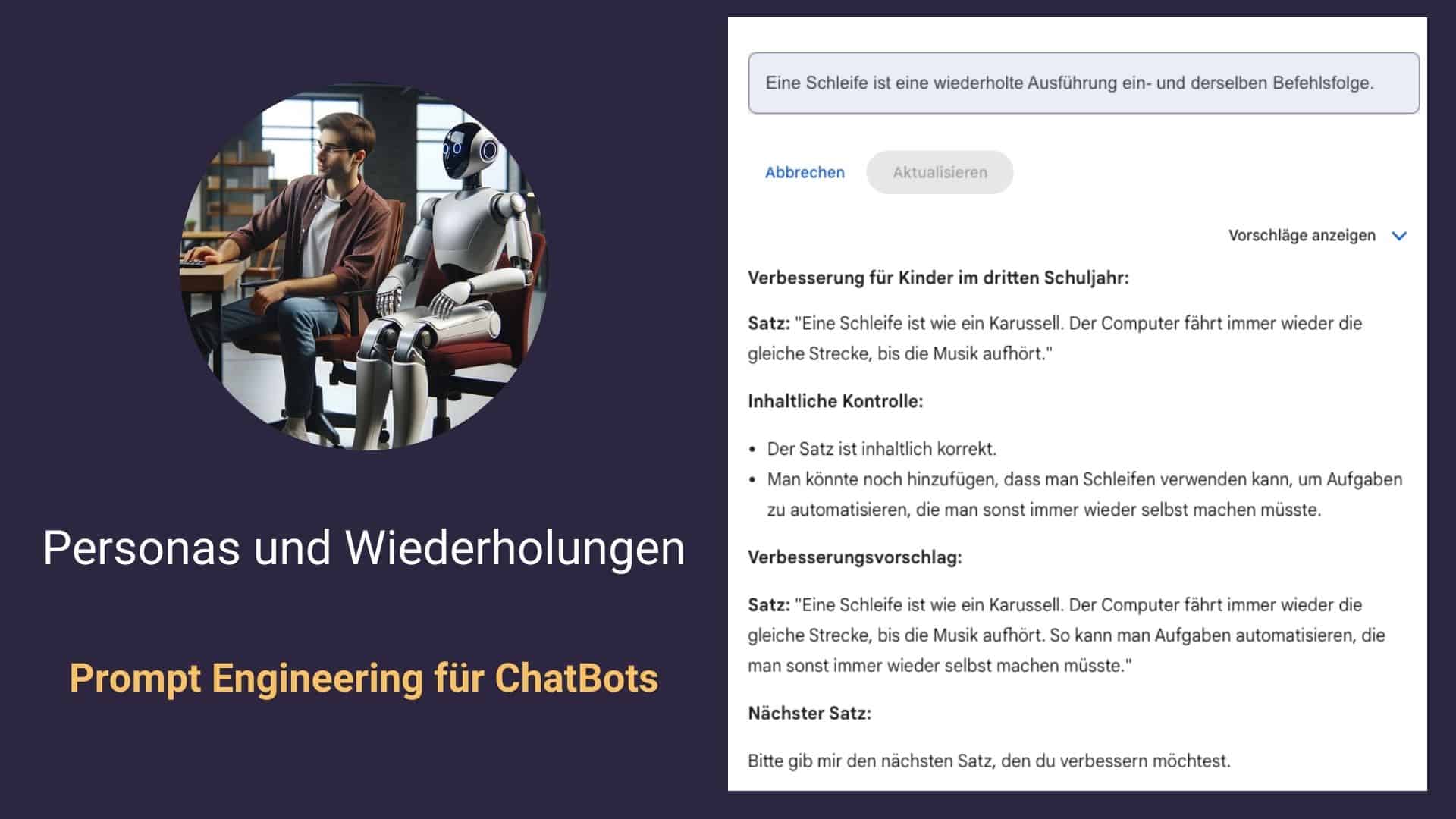
Im folgenden Dialog werde ich einzelne Sätze geben. Tue damit folgendes:
– Verbessere den Satz für Data Engineers mit Universitätsabschluss, die Python lernen wollen.
– Kontrolliere den Satz inhaltlich und gibt inhaltliche Verbesserungsvorschläge.
– Erläutere deine Verbesserungsvorschläge. Gib deinen Erläuterungen die Überschrift: “Erläuterung der Verbesserung”
– Bitte mich um den nächsten Satz.
Wir leiten ein mit: “Ich werde dir einzelne Sätze geben”. Zählen anschließend unsere Anforderungen auf, die enden mit “Bitte mich um den nächsten Satz”.
Es ist fast wie Programmieren im Pseudocode…
Hier die Beispiele – bei Gemini brauchen wir nicht um Erläuterungen zu bitten.

ChatGPT 4 strukturierter Dialog – Zielpublikum Data Engineers
Prompt:
Im folgenden Dialog werde ich einzelne Sätze geben. Tue damit folgendes:
- Verbessere den Satz für Data Engineers mit Universitätsabschluss, die Python lernen wollen.
- Kontrolliere den Satz inhaltlich und gib inhaltliche Verbesserungsvorschläge.
- Erläutere deine Verbesserungsvorschläge. Gib deinen Erläuterungen die Überschrift: “Erläuterung der Verbesserung”
- Bitte mich um den nächsten Satz.
Antwort (Beispiel):
“In der Programmierung ermöglicht eine Schleife die wiederholte Ausführung einer definierten Befehlssequenz, was für Data Engineers, die ihre Fähigkeiten in Python vertiefen möchten, essentiell ist.”
Die Erläuterungen von ChatGPT siehst du mit Klick auf den Thumbnail links.

Gemini strukturierter Dialog – Zielpublikum Data Engineers
Prompt:
Im folgenden Dialog werde ich einzelne Sätze geben. Tue damit folgendes:
- Verbessere den Satz für Data Engineers mit Universitätsabschluss, die Python lernen wollen.
- Kontrolliere den Satz inhaltlich und gib inhaltliche Verbesserungsvorschläge.
- Bitte mich um den nächsten Satz.
Antwort (Beispiel):
“Schleifen ermöglichen die wiederholte Ausführung einer Befehlsfolge, um Daten effizient zu verarbeiten und komplexe Aufgaben zu automatisieren.”
Die Erläuterungen von Gemini siehst du mit Klick auf den Thumbnail links. Gemini liefert auch Verbesserungsvorschläge und begründet sie.
Inhaltliche Überprüfung durch Chatbots
Im letzten prompt haben wir auch eine inhaltliche Überprüfung verlangt. Beide ChatBots waren mit unserem Inhalt zufrieden. Probieren wir das aus mit folgendem Satz:
Python ist eine kompilierte Sprache.
Die Reaktionen der beiden ChatBots. Diese fielen nicht in jedem Anlauf gleich aus. Beide ChatBots verhalten sich vergleichbar. Je nach Anlauf ist die Antwort mehr oder weniger präzise und mehr oder weniger korrekt.
Wie immer: es liegt an uns die generierten Texte inhaltlich zu prüfen. Der Chatbot verfügt über kein belastbares Wissen und berechnet die Texte jedes Mal anders.
Vergleiche die Antworten: Beide sind sehr differenziert. Führt man den Prompt mehrfach aus, dann generieren sowohl ChatGPT 4 als auch Gemini beide Typen Antwort. Unten findest du Beispiele.

ChatGPT 4 mit dem Auftrag zur inhaltlichen Korrektur
Prompt:
Verbessere den folgenden Satz für Data Engineers mit Universitätsabschluss und führe eine inhaltliche Prüfung des Satzes durch: Python ist eine kompilierte Sprache.
Antwort (Beispiel):
Die Aussage “Python ist eine kompilierte Sprache” ist technisch nicht korrekt. Python ist primär eine interpretierte Sprache, was bedeutet, dass Python-Code zur Laufzeit von einem Interpreter ausgeführt wird, anstatt zuerst in Maschinencode kompiliert zu werden. Für Data Engineers mit Universitätsabschluss, die mit technischen Details vertraut sind, könnte der Satz verbessert und korrigiert werden zu:
“Python ist eine interpretierte Hochsprache, die aufgrund ihrer einfachen Syntax und vielfältigen Bibliotheken in der Datenwissenschaft weit verbreitet ist.”

Gemini mit dem Auftrag zur inhaltlichen Korrektur
Prompt:
Verbessere den folgenden Satz für Data Engineers mit Universitätsabschluss und führe eine inhaltliche Prüfung des Satzes durch: Python ist eine kompilierte Sprache.
Antwort (Beispiel):
Der Satz “Python ist eine kompilierte Sprache” ist für Data Engineers mit Universitätsabschluss falsch und irreführend.
Verbesserter Satz:
Python ist teilweise kompiliert und teilweise interpretiert.
Inhaltliche Prüfung:
- Die Aussage “Python ist eine kompilierte Sprache” ist nicht korrekt.
- Die Verwendung des Wortes “kompiliert” impliziert, dass der gesamte Python-Code in Maschinencode übersetzt wird, was nicht der Fall ist.
- Die Aussage könnte zu Missverständnissen bei Data Engineers mit Universitätsabschluss führen, die mit den Interna von Python vertraut sind.
Weitere Punkte und Empfehlungen, die Gemini generiert, findest du mit Klick auf den Thumbnail links.
Fazit
Mit geschickt konstruierten Prompts beeinflussen wir das Verhalten von ChatBots. Personas und Wiederholungen sind zwei Prompt-Patterns, die uns dabei unterstützten,
Die inhaltliche Prüfung der generierten Aussagen liegt immer in unserer eigenen Verantwortung.