

Warum sollte man überhaupt eine Reihe von virtuellen Maschinen bei AWS oder einem anderen Cloud-Anbieter einrichten und anschließend das Hadoop Distributed Filesystem und andere Komponenten des Hadoop Ökosystems installieren? Immerhin bieten viele Cloud-Anbieter solche Komponenten vorgefertigt auf Knopfdruck.
Diese Frage ist leicht zu beantworten: Wer die grundsätzliche Funktionalität und die grundsätzlichen Zusammenhänge kennen lernen will, braucht eine Übungsumgebung.
![]()
Das Big Data Labor zeigt zu Beginn verschiedene Möglichkeiten, eine solche Übungsumgebung zu schaffen:
- Mit virtuellen Maschinen, z.B. mit Virtual Box – siehe auch Infrastruktur für Big-Data-Trainings
- Mit Raspberry Pi
- Oder eben in der Cloud, beispielsweise bei AWS (Amazon).
Wer produktiv arbeiten will, geht anders vor:
- Baut eine produktiven Cluster auf, ähnlich wie im Tutorial mit Raspberry Pi gezeigt
- Oder verwendet die vorgefertigten Komponenten bei einem Cloud-Anbieter.
Zusammenhänge begreift man am besten, indem man den Weg einmal selbst geht, alles aufbaut und untersuchen kann.
Bei AWS erhalten wir die für das Big Data Labor minimal notwendigen Ressourcen auch bis zu einem gewissen Grad kostenlos.
Dieses Tutorial zeigt folgendes:
- Wir setzen ein AWS-Konto auf und bewegen uns dabei möglichst im kostenlosen Rahmen.
- Wir konfigurieren eine erste virtuelle Maschine mit Ubuntu Linux und nehmen sie in Betrieb
- Wir versehen sie mit einer fest zugeordneten IP-Adresse
- Wir vervielfachen diese virtuelle Maschine und sind damit bereit für das nächste Kapitel im Big Data Labor, den Aufbau von HDFS.
Notwendige Vorkenntnisse
Das Tutorial richtet sich an Informatiker mit Grundkenntnissen in Linux. Die Fähigkeit , einen kommandozeilenorientierten Editors wie vi oder nano zu bedienen, wird vorausgesetzt.
Ebenso vorausgesetzt wird das grundlegende Verständnis über den Aufbau von Computern und Netzwerken. IP-Adressen, ssh seien keine Fremdwörter.
Vorbereitung
Es ist praktisch, mit einer ssh-Konsole unter Linux/Mac zu arbeiten und der Einfachheit halber auch gleich diese ersten Einrichtungsschritte mit einem Browser auf einem Linux/Mac Desktop durchzuführen.
Wer mag, kann natürlich auch mit Windows/ssh arbeiten, verzichtet damit auf etwas Komfort.
Wer einen Windows Laptop hat und dennoch mit Linux arbeiten möchte, kann eine einfache virtuelle Maschine einrichten. Dies ist im Tutorial Eine VirtualBox einrichten und klonen beschrieben. Mit einem kleinen Unterschied: statt als Gast das Server Betriebssystem zu installieren, lohnt es sich das Desktop-Betriebssystem zu nehmen. Für Ubuntu ist es hier zu finden: https://www.ubuntu.com/download/desktop
Es reicht, eine virtuelle Maschine aufzubauen, sie muss nicht geklont werden; dieser Schritt aus dem genannten Tutorial braucht nicht durchgeführt zu werden.
Firefox ist auf dem Ubuntu-Desktop vorinstalliert und Terminals lassen sich leicht öffnen: mit Rechtsklick auf den Desktop und Auswahl “Open Terminal” im Kontextmenü. Dann kann man viele Befehle auch mit copy-paste übernehmen. Dazu verwendet man das Kontextmenü, das man mit der rechten Maustaste öffnet.
Dieser Desktop übernimmt die Rolle des mit PI-200 bezeichneten Rechners im Big Data Labor.
AWS Konto anlegen
Falls wir noch kein AWS Konto haben, dann legen wir zuerst eines an. Wir öffnen in einem Browser die Url https://aws.amazon.com/de
AWS ist sehr reif und verändert diese grundlegende Funktionalität nur sehr moderat. Die Darstellungen können jedoch ändern und von denjenigen auf den Screenshots abweichen. Auf dieser Seite wählen wir oben rechts “AWS-Konto erstellen”.
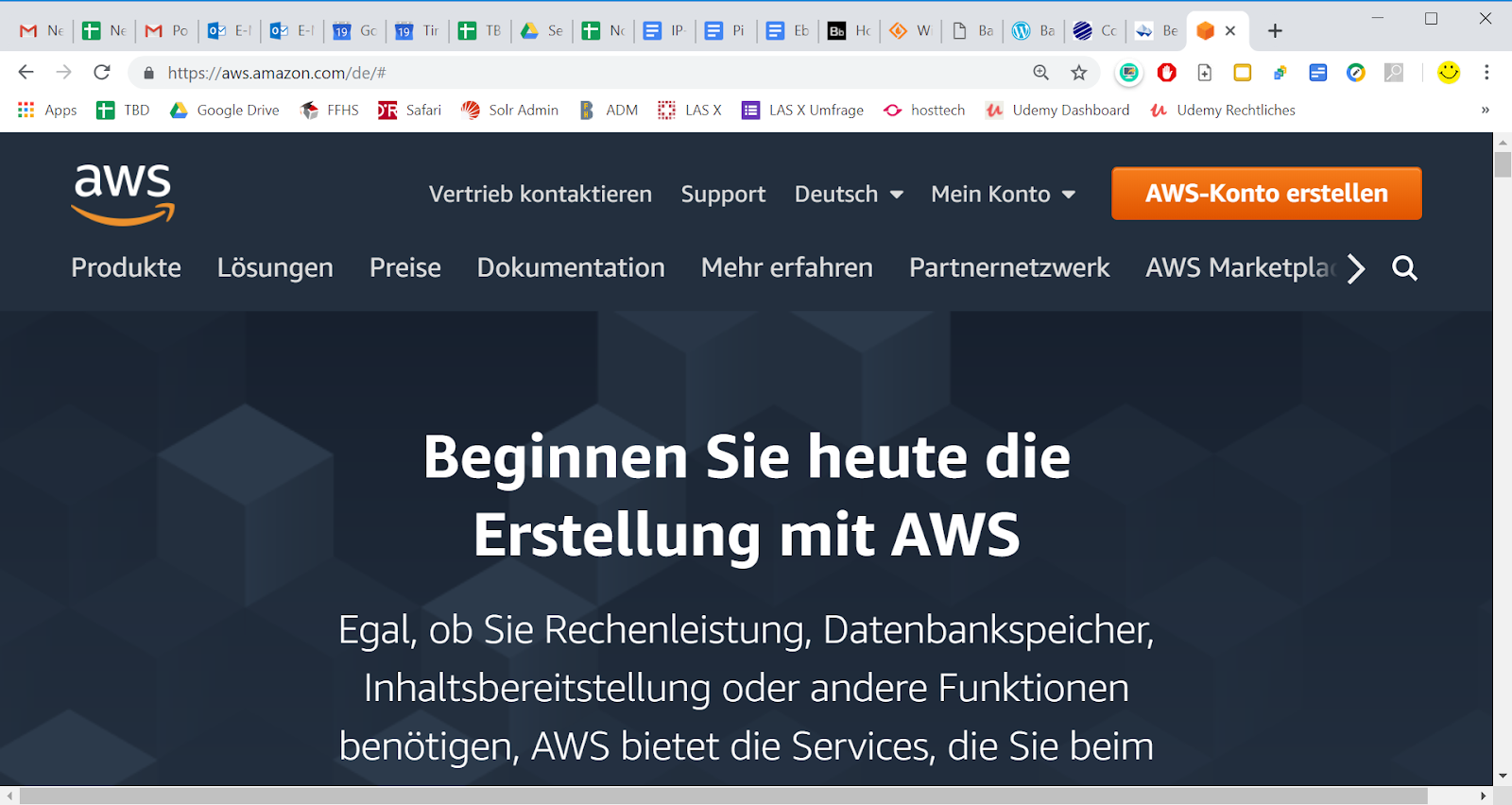
Die Benutzerführung ist intuitiv und wir machen die gewünschten Angaben. Wir nehmen auch zur Kenntnis, wie lange wir auf das kostenlose Kontingent zugreifen dürfen. Dabei müssen wir uns bewusst bleiben, dass dieses auch vor Ablauf der auf der Seite genannten Zeit (hier zwölf Monate) aufgebraucht werden kann.
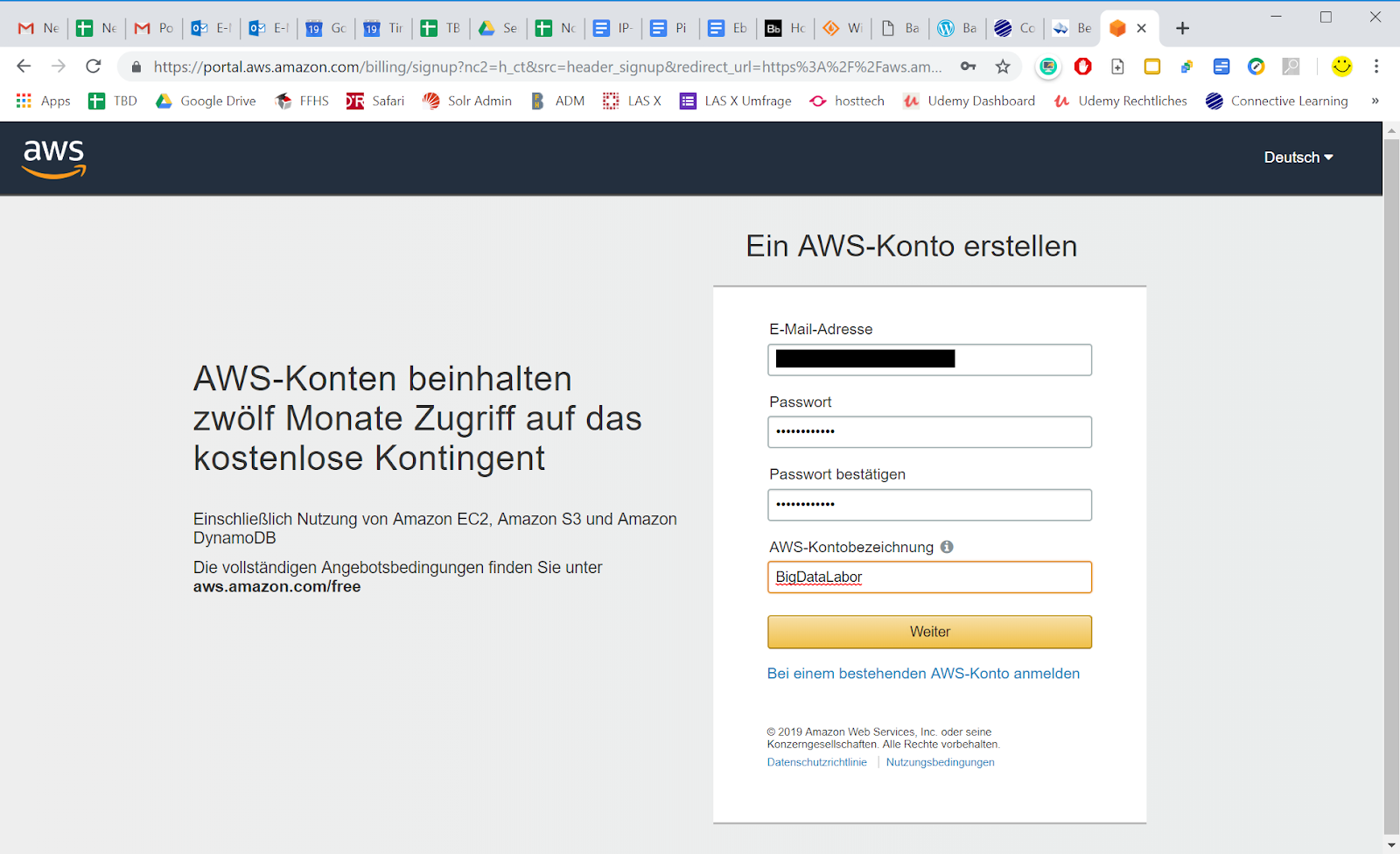
Auf der nächsten Seite wählen wir den Kontotyp aus, Professional oder Privat, je nachdem, wie wir unterwegs sind. Und wir geben einen Namen und die weiteren notwendigen Angaben.

Ohne Zahlungsinformationen können wir kein Konto anlegen. Wir werden ein paar Seiten später sehen, wie wir einen Alert einrichten können, um rechtzeitig festzustellen, wenn wir unser Kontingent aufgebraucht haben.
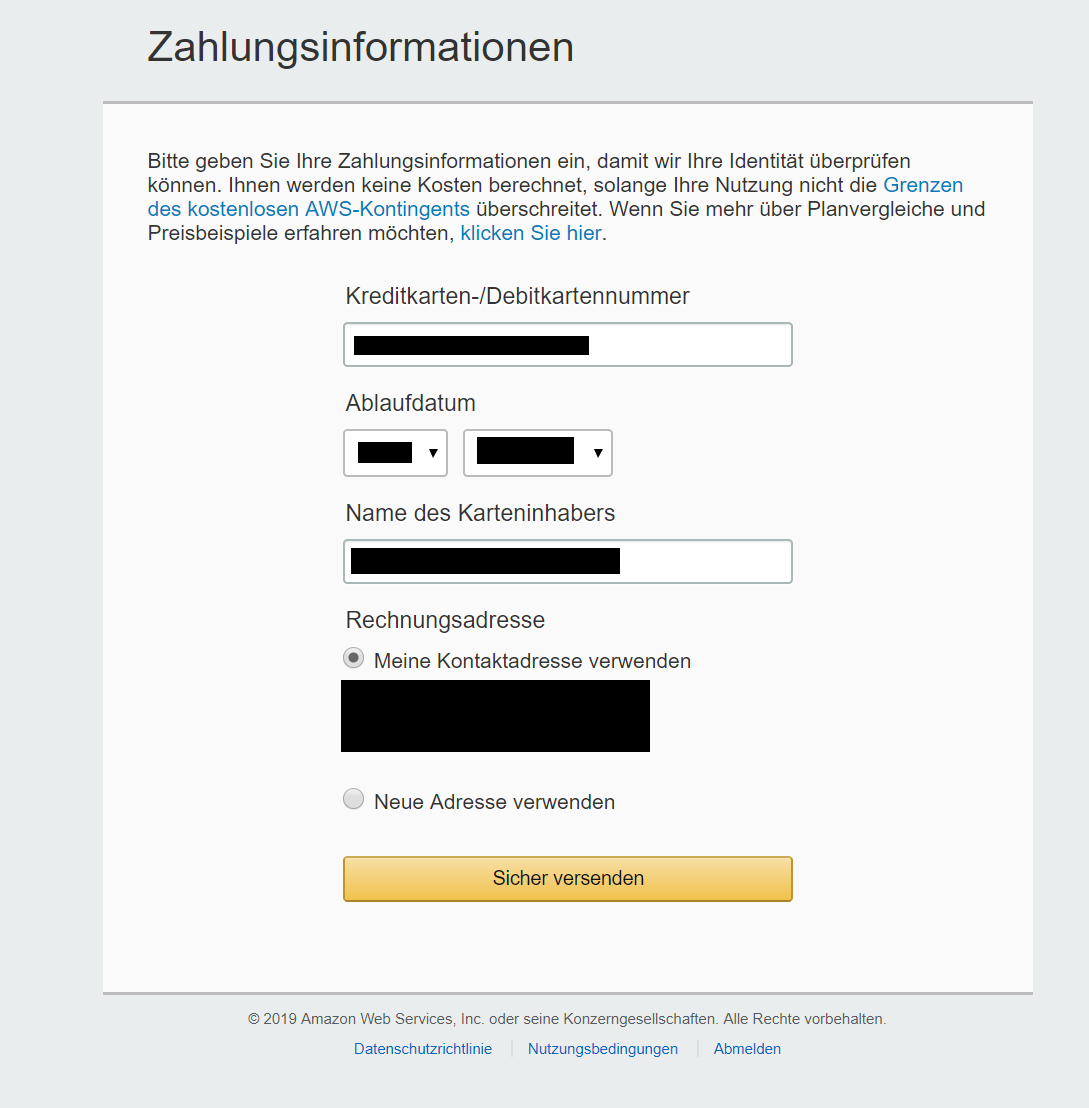
AWS will die Identität bestätigen und insbesondere auch automatisch angelegte Accounts verhindern. Hier wählen wir die Möglichkeit mit SMS. Wir geben das Land und die Telefonnummer an, und schreiben die Zeichenfolge auf der Sicherheitsprüfung ab.

Nachdem wir “Kontaktieren Sie mich” geklickt haben, erhalten wir nahezu sofort eine SMS auf der Telefonnummer. Diese enthält einen Code, den wir abtippen.

Wir klicken auf “Code verifizieren”. Klappt alles wie gewünscht, dann konnte die “Identität” überprüft werden.
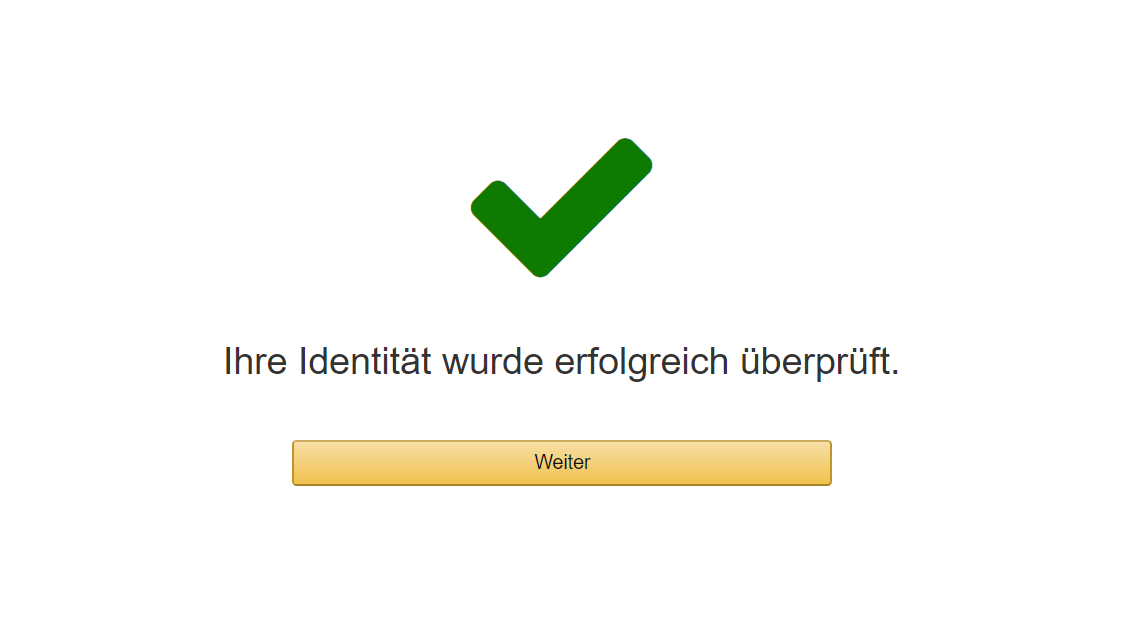
Wir klicken auf “Weiter” und können einen Support Plan wählen. Für das Big Data Labor fangen wir mit dem Kostenlosen Basic Plan an.

Wir wählen den kostenlosen Basic-Plan aus und landen hier.
Ab jetzt steht uns die umfangreiche und sehr ausführlich dokumentierte AWS-Welt zur Verfügung. Nahezu sofort erhalten wir eine E-Mail:

Etwas später trifft eine weitere E-Mail ein:
und gleich noch eine:
Einloggen und Region wählen
Wir müssen uns mit dem neu geschaffenen Konto einloggen. Dazu werden uns ja zahlreiche Möglichkeiten geboten. Beispielsweise indem wir auf die Schaltfläche “Bei der Konsole anmelden” Klicken.

Wir werden nach E-Mail-Adresse und Passwort gefragt und landen auf der Seite der AWS Management-Console.

Für das Big Data Labor brauchen wir einfache virtuelle Maschinen mit Linux-Betriebssystem.
Amazon unterhält viele Rechenzentren rund um den Globus. Voreingestellt ist Ohio und wir wählen zuerst eine andere Region aus. Dazu klicken wir oben rechts auf “Ohio” und wählen im Menu ein uns näher liegendes Rechenzentrum.
Je nach Region sind die Preise leicht verschieden. Wir wollen ja möglichst kostenlos unterwegs sein und sind wohl eher daran interessiert, auszuwählen, wo unsere Daten gelagert werden, auch wenn es im Rahmen des Big Data Labors nur einige wenige Testdaten sind.
Für dieses Tutorial wählen wir EU (Frankfurt) aus.

Die erste virtuelle Maschine einrichten
Noch auf derselben Seite, also der AWS Management Console, wählen wir jetzt die Option “Virtuelle Maschine starten” aus.
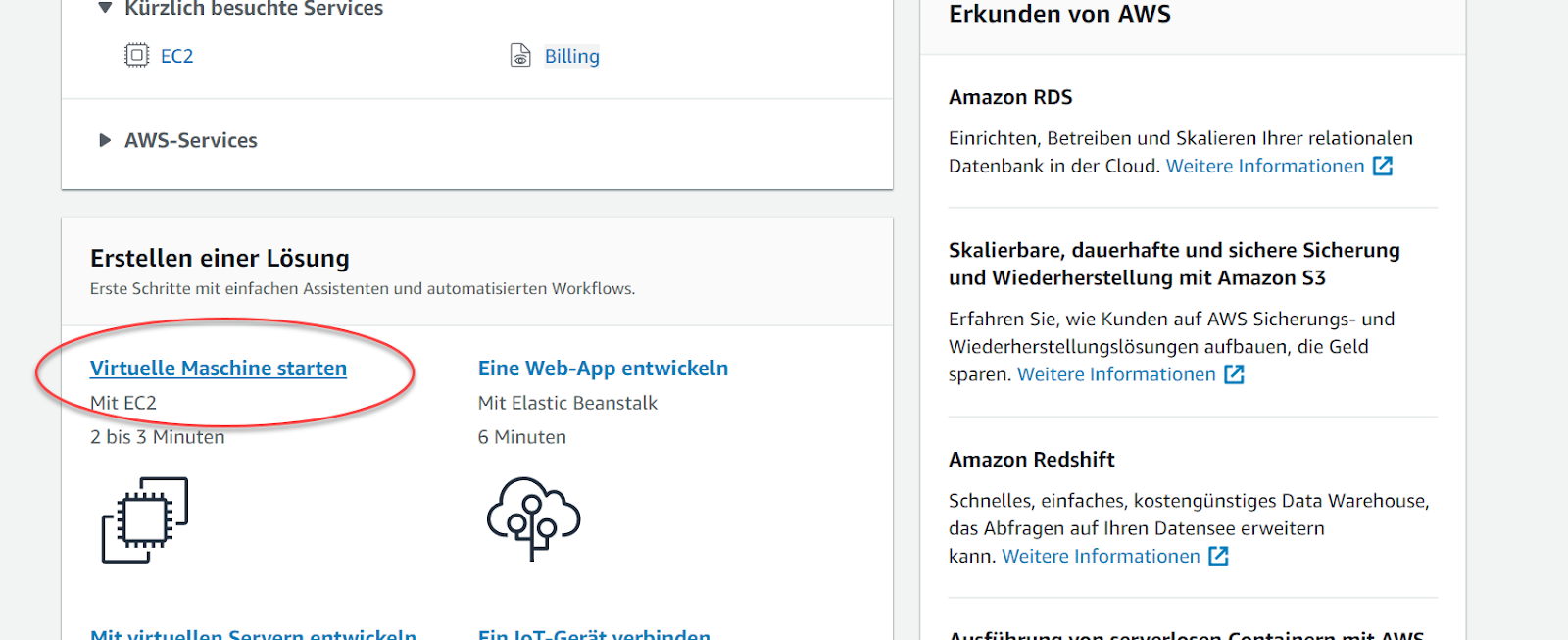
Wir werden jetzt schrittweise geführt. Im ersten Schritt wählen wir ein passendes Image. Wir scrollen etwas nach unten und finden Ubuntu Server 18.04 LTS. Diese Linux-Distribution passt zum Big-Data Labor. Wir klicken auf die dazu gehörende Schaltfläche “Select”
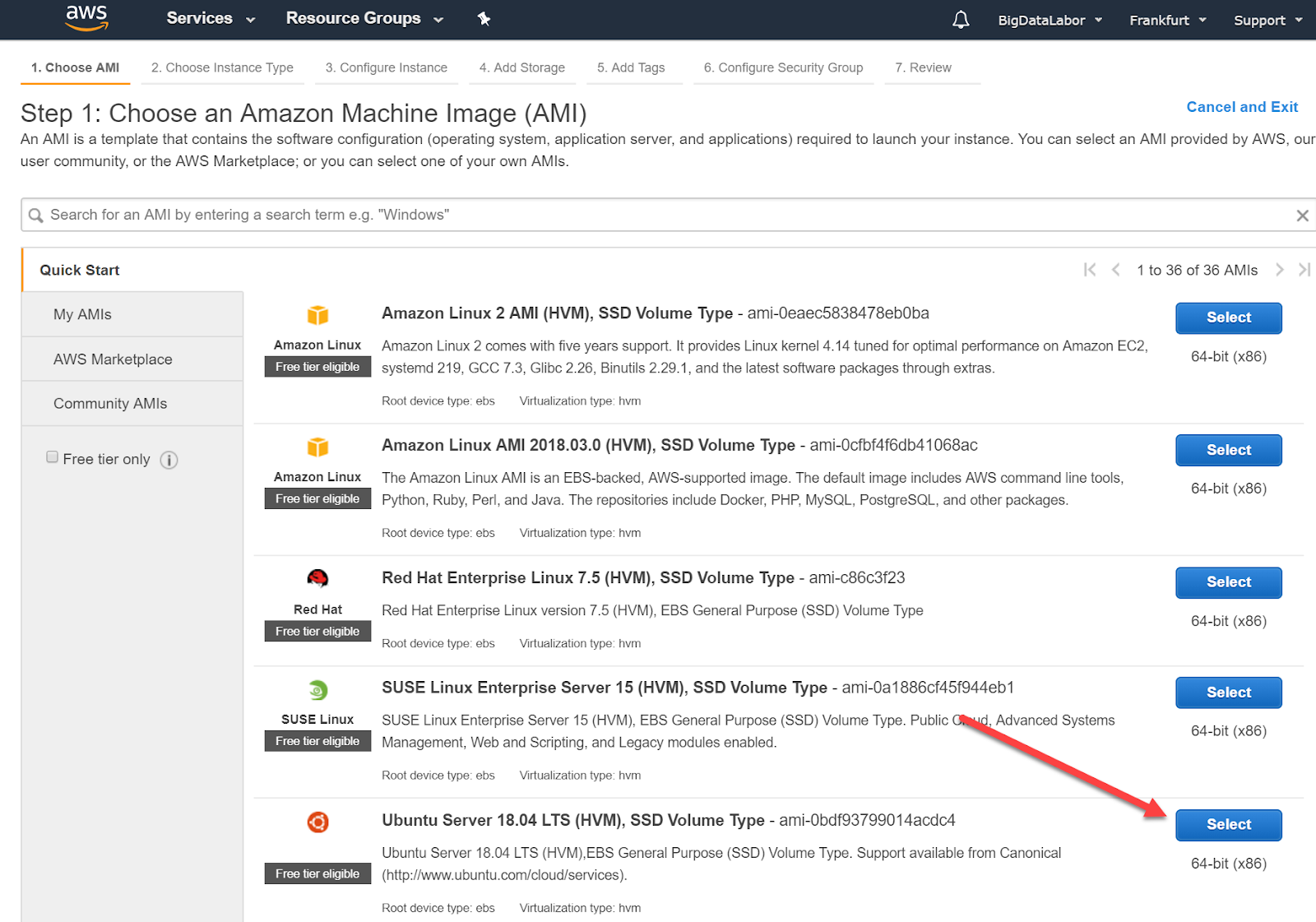
Als nächstes ist der Instanz-Typ zu wählen. Je mehr Ressourcen wir beanspruchen, desto kostspieliger wird der Gebrauch. Das kostenlose Kennenlernpaket enthält zum Zeitpunkt des Erstellens dieses Tutorials auch den Typ t2.micro. Dieser kommt mit 1 GB Memory, entspricht also gerade einem Raspberry Pi. Das Big Data Labor wurde für Raspberry Pi entworfen und wir können also auch mit t2.micro arbeiten.
Wer mehr Geschwindigkeit haben möchte, wählt einen kostenpflichtigen, besser ausgestatteten Instanz-Typ.
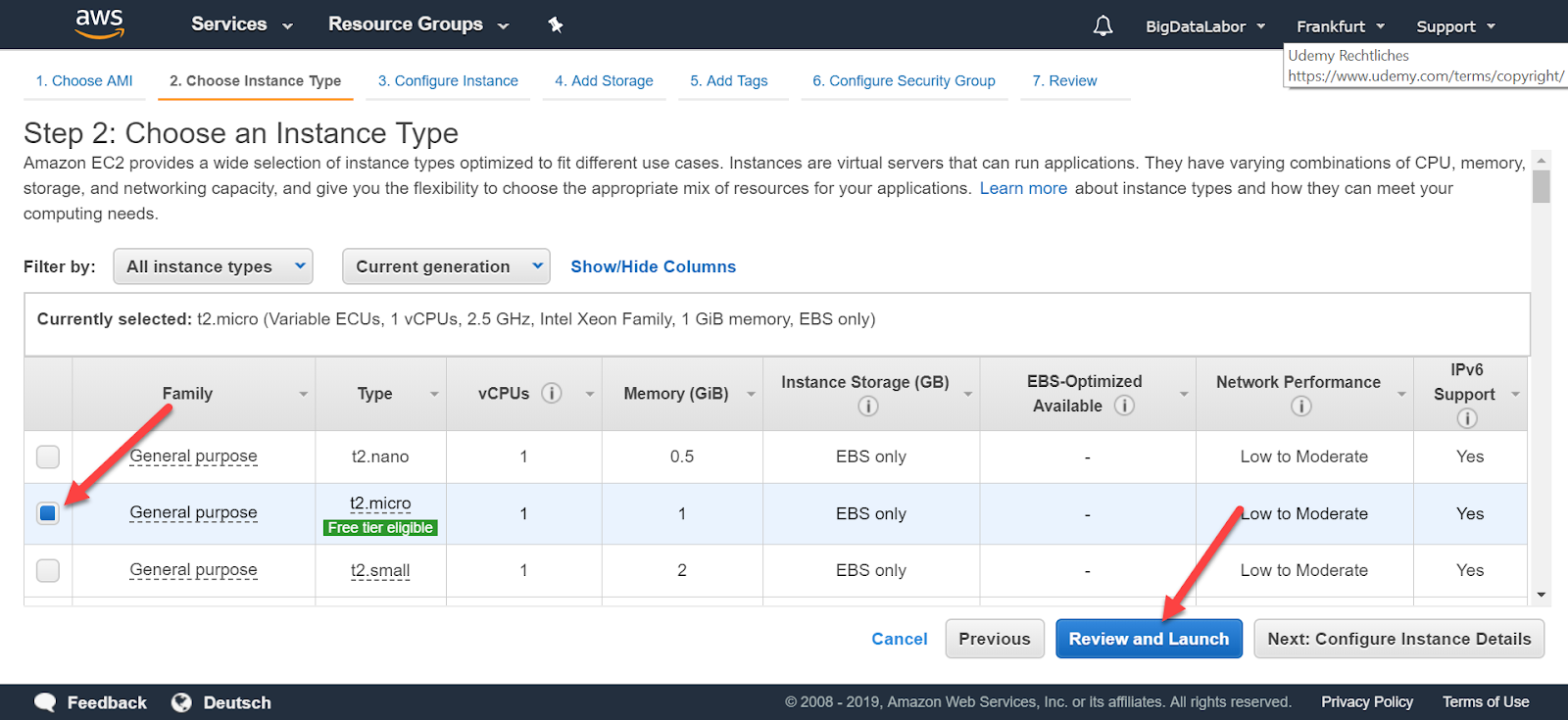
Nach der Wahl des Instanztyp klicken wir “Review and Launch”.
Wir erhalten eine Übersichtsseite mit mehr Angaben. Beispielsweise sehen wir hier, dass dieser Instanz-Typ mit 8 GB SSD Storage kommt. Das reicht für das Big Data Labor – wenn wir bereit sind, hin und wieder den Platz zu bereinigen.
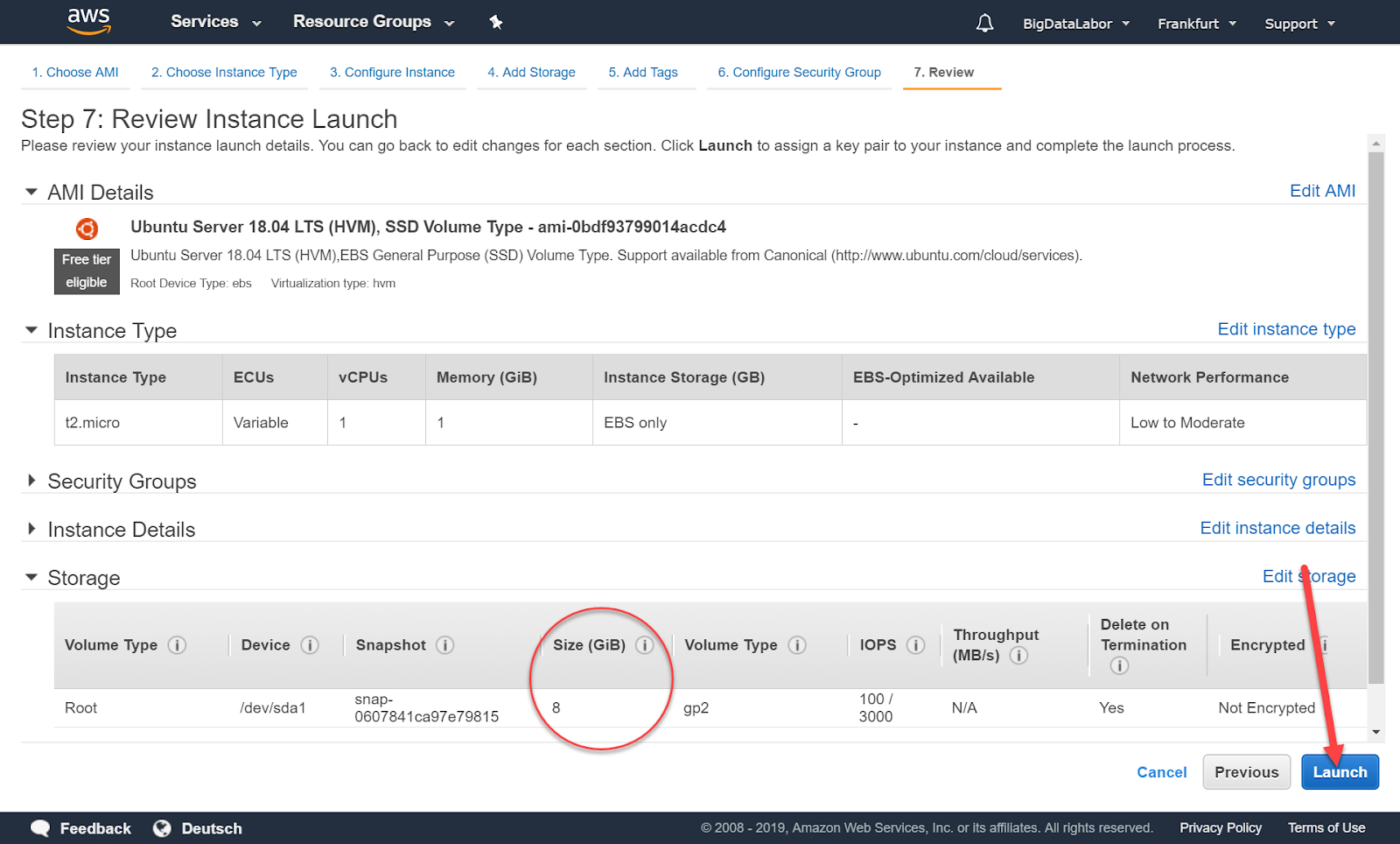
Wir klicken jetzt auf “Launch”.
Das Schlüsselpaar (Key Pair)
Als nächstes werden wir aufgefordert, ein Schlüsselpaar (Key Pair) auszuwählen. Dieses dient dazu, den Datenverkehr zu verschlüsseln und den Zugang zur virtuellen Maschine abzusichern.
Beim ersten Gebrauch von AWS werden wir ein Schlüsselpaar erstellen. Ein Teil (der public Key) bleibt auf dem Server, den anderen Teil (den private Key) laden wir herunter und bewahren ihn sorgfältig auf.
Aus der Auswahlliste wählen wir “Create a new key pair”. Bei jeder weiteren virtuellen Maschine werden wir dieses Key Pair (Schlüsselpaar) dann verwenden.

Jetzt werden wir aufgefordert, dieses Schlüsselpaar zu benennen. Beispielsweise AWSBigDataLaborKey. Und wir klicken anschließend auf “Download Key Pair”.

Eine Datei mit dem Namen AWSBigDataLabor.pem wird jetzt heruntergeladen. Sie enthält den Schlüssel zur virtuellen Maschine.
Wir können für alle virtuellen Maschinen denselben Schlüssel verwenden. Verliert wir den Schlüssel, dann verlieren wir auch den Zugang zu den virtuellen Maschinen. Wir bewahren das Schlüsselpaar also sehr sorgfältig auf und erstellen einen Backup.
Ist das erfolgt, dann klicken wir “Launch Instances” um diese virtuelle Maschine zu starten.

Wir erhalten diese Benachrichtigung. Es dauert einige Minuten, bis diese Instanz gestartet ist.
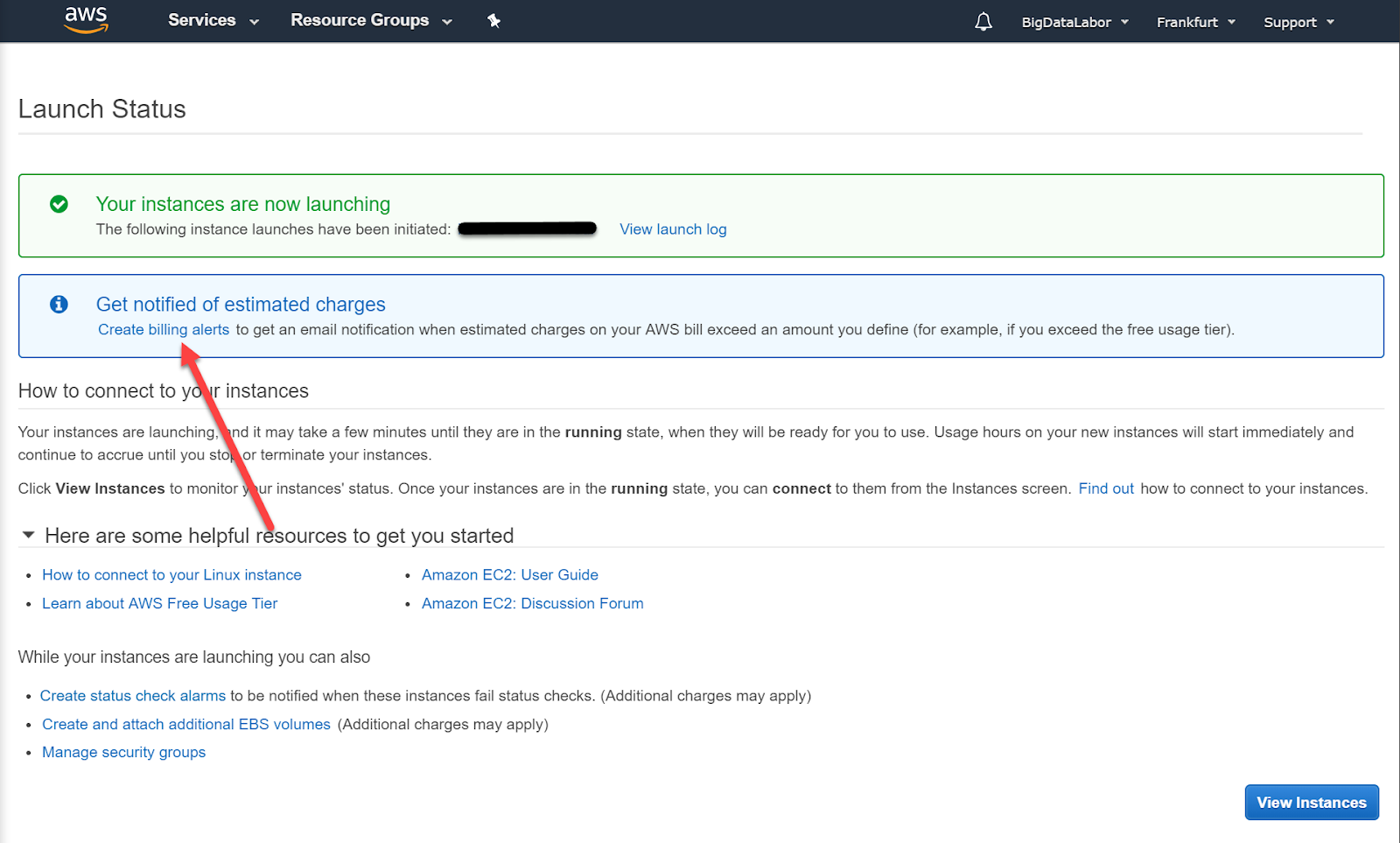
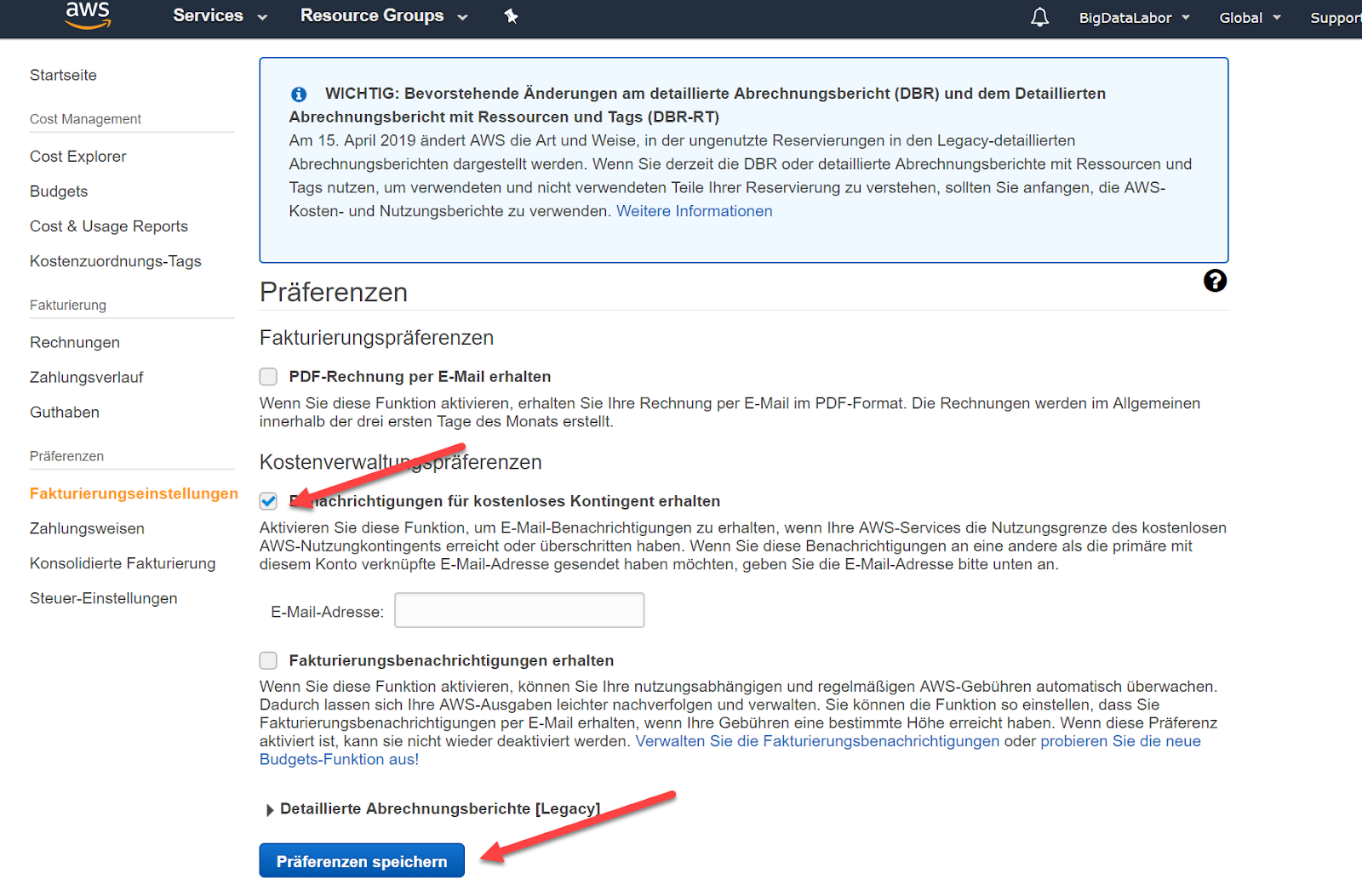
Kosten kontrollieren: einen Billing Alert einrichten
In der Zwischenzeit können wir einen Billing Alert einrichten. So erhalten wir eine E-Mail, wenn die Kosten auf AWS einen gewissen Betrag übersteigen sollte. Auch wenn wir kostenlose Instanzen gewählt haben, können wir einen solchen Alert einrichten. Wir klicken auf den entsprechenden Link. Ein neues Browser-Window wird geöffnet.
Wir wählen mindestens die Option “Benachrichtigungen für kostenloses Kontingent erhalten” an, um benachrichtigt zu werden, sobald das kostenlose Kontingent aufgebraucht ist. Dies speichern wir mit “Präferenzen speichern”.
EC2-Dashboard: Die Instanzen
Wir gehen jetzt zurück auf das Browser-Fenster “Launch Status” und klicken “View Instances”.

Sollten wir uns “verirrt” haben, dann können wir das EC2-Dashboard auch aus dem Menü heraus wieder öffnen.
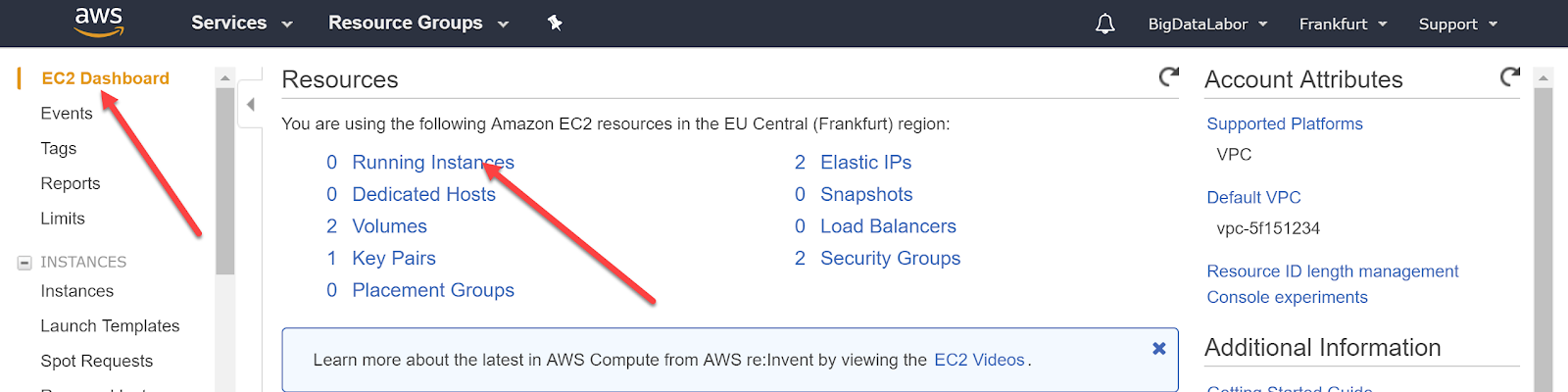
Der Menüpunkt ist gleich oben links. Wir wählen es an und erhalten im Hauptteil der Seite eine Ressourcenübersicht. Dort Klicken wir auf “Running Instances”
Wir erhalten eine Übersicht über alle unseren Instanzen. Mittlerweile dürfte diese erste virtuelle Maschine im Zustand “running” sein.
Ihr ist auch eine öffentliche IP-Adresse zugeordnet.
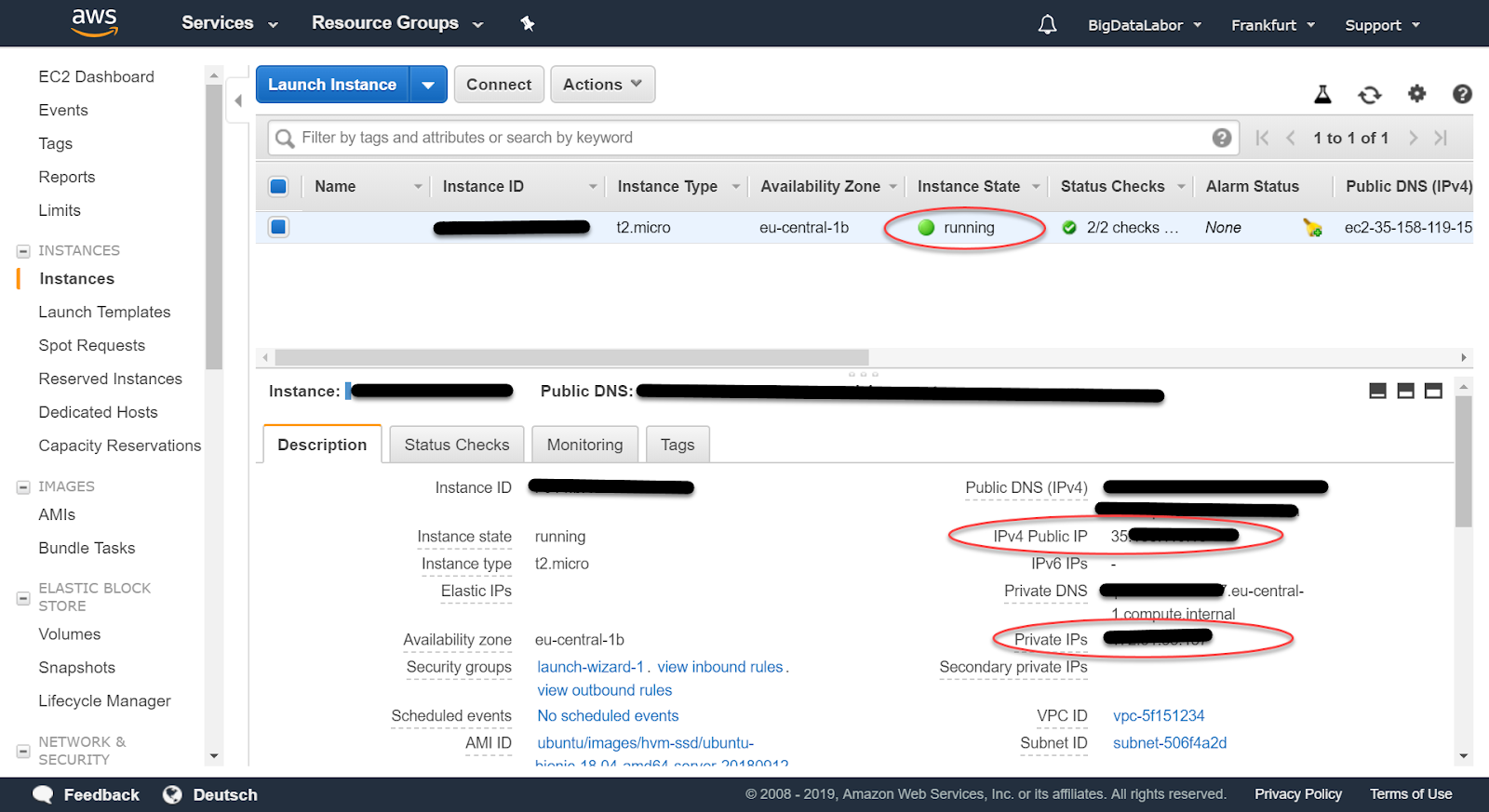
ssh Verbindung aufbauen
Mit dieser öffentlichen (public) IP-Adresse und mit dem Schlüssel können wir jetzt eine ssh-Verbindung zu diesem Server aufbauen.
Auf unserem lokalen Rechner, öffnen wir ein Terminal (z.B. Rechtsklick auf den Ubuntu-Desktop). Mit cd verzweigen wir in das Verzeichnis, indem wir den Schlüssel AWSBigDataLaborKey.pem sicher aufbewahren. Wir haben die Datei ja während der Installation heruntergeladen. Falls wir sie noch nicht verschoben haben, werden wir sie im Download-Verzeichnis finden.
Damit wir den Schlüssel verwenden können, müssen wir einmalig die Berechtigungen verändern:
chmod 400 AWSBigDataLaborKey.pem

Jetzt bauen wir eine ssh-Verbindung zu dieser Instanz auf. Dazu verwenden wir die öffentliche IP-Adresse und den folgenden Befehl
ssh -i (Pfad zum .pem-File} {öffentliche IP-Adresse} -l ubuntu
oder alternativ
ssh -i {Pfand zum .pem-File} ubuntu@{öffentliche IP-Adresse}
Wer nicht Ubuntu installiert hat, sondern eine andere Linux-Distribution vorgezogen hat, wird hier an Stelle von “ubuntu”, den Standard-Usernamen dieser Distribution eingeben.
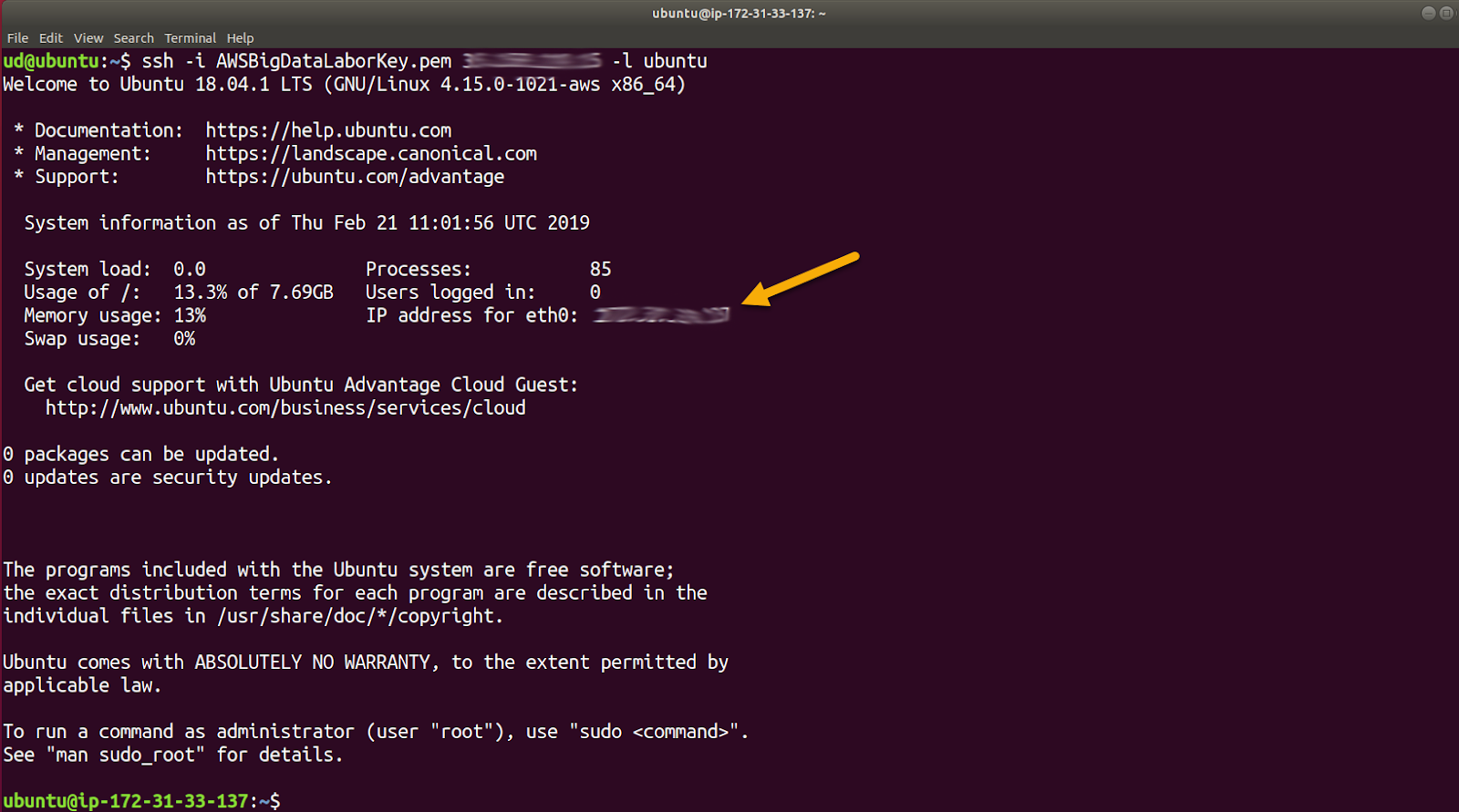
Wie gewohnt bestätigen wir die Frage nach dem Fingerprint mit yes.
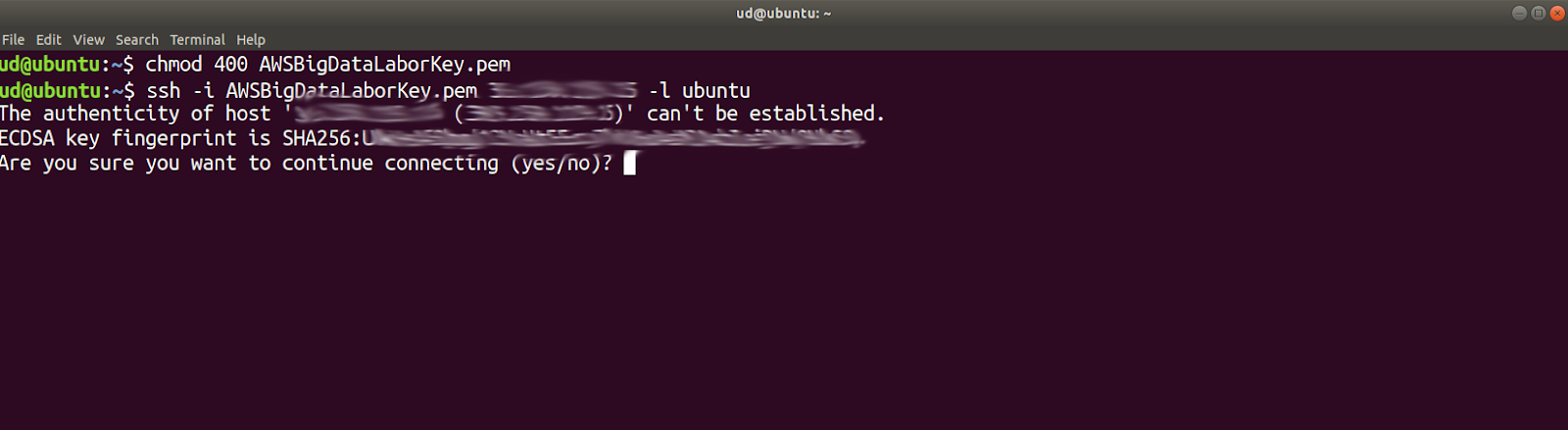
Jetzt erhalten wir die Begrüßungsinformation, die auch nochmals die private IP-Adresse enthält. Wir befinden uns jetzt in einer gewohnten Ubuntu-Umgebung und können beginnen, den Cluster aufzubauen.
Instanz stoppen und neu starten
Auch wenn wir ein kostenloses Kontingent erhalten haben, sollten wir uns von Anfang an daran gewöhnen, nicht verwendete Instanzen zu stoppen. Laufzeit ist ein Kostenfaktor bei AWS.
Dazu gehen wir auf das EC2-Dashboard, wählen die Instanz aus, klicken auf “Action”, wählen den Menüpunkt “Instance State” und dann den Untermenüpunkt “Stop”.
Diese Instanz können wir später wieder starten. Wählen wir stattdessen “Terminate”, dann wird die Instanz heruntergefahren und später gelöscht.

Das Stoppen kann einige Sekunden dauern. Sobald die Aktion ausgeführt ist, wird der neue Zustand auf der Konsole angezeigt.

Mit “Start” können wir die Instanz wieder starten.
Public und Private IP Adressen

Die Graphik veranschaulicht das Zusammenspiel der öffentlichen (public) und privaten IP-Adressen.
Rechts ist das LAN bei uns im Haus dargestellt, mit dem Laptop der wireless oder Kabelgebunden mit dem Router verbunden ist. Dieser stellt die Verbindung zum Internet her, vernetzt alle Rechner bei uns im Haus und schirmt mit der Firewall unerwünschten Besuch aus dem Internet ab.
Auch das Rechenzentrum bei AWS hat eine Firewall, um unerwünschten Traffic aus dem Internet abzuschirmen. Wir wollen aber auf unsere virtuelle Maschine zugreifen und dazu brauchen wir eine IP-Adresse. Mit der öffentlichen IP-Adresse finden wir den Weg zu unserer virtuellen Maschine. Im Bild beispielsweise mit PI-202 benannt.
Wir wollen unsere virtuellen Maschinen miteinander vernetzen. Es wäre sehr umständlich, dies mit den öffentlichen IP-Adressen zu tun, denn dazu müsste der gesamte Datenverkehr immer über das öffentliche Internet laufen.
Viel effizienter ist es, das LAN bei AWS selbst zu verwenden. Und in diesem LAN haben die virtuellen Maschinen eine private IP-Adresse.
Elastic IP Adresse zuordnen
Unternehmen wir nichts, dann erhält die Instanz mit jedem Start eine neue öffentliche und eine neue private IP-Adresse.
Permanent zugeordnete IP-Adressen heissen bei AWS elastic IPs und können kostenpflichtig sein. Hier ein Link zur Information: https://aws.amazon.com/de/ec2/pricing/on-demand/
Und ein Einblick zum Zeitpunkt der Erstellung des Tutorials:

Eine Elastic-IP-Adresse ist pro Instanz also kostenlos.
Wir erstellen also eine elastische IP-Adresse. Dazu scrollen wir links in der AWS Management Konsole etwas nach unten und klicken die Option “Elastic IPs”
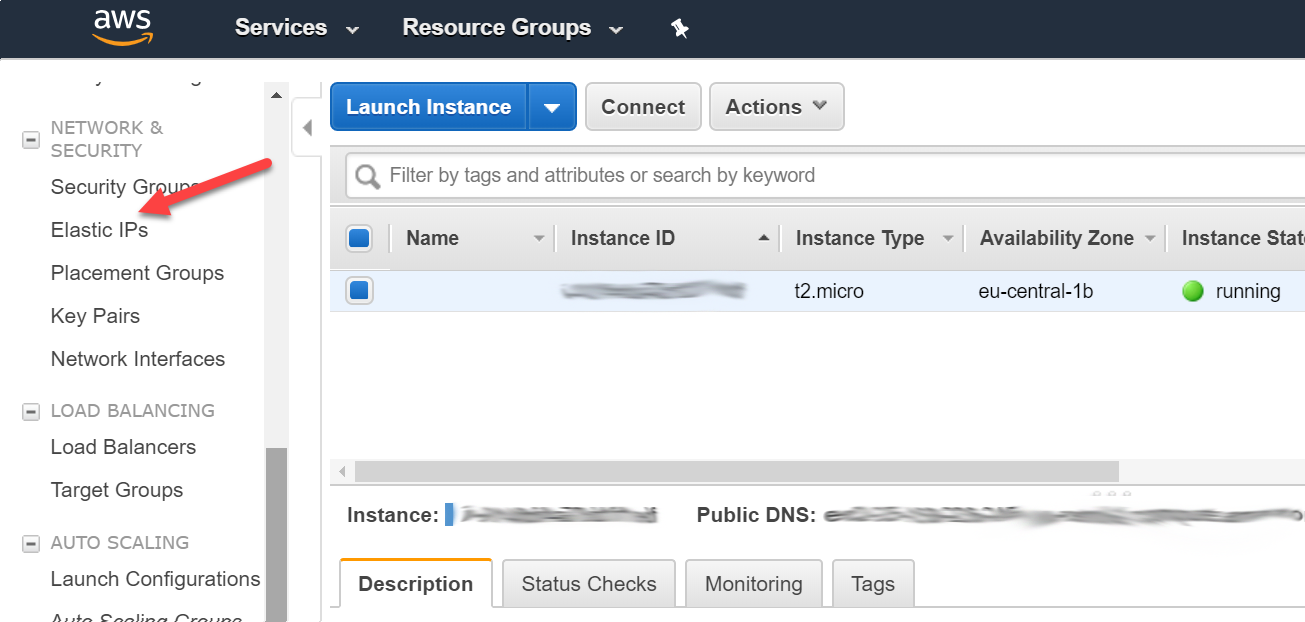
Wir erhalten die Information, dass wir für diese Region (also Frankfurt) keine Elastic IP-Adresse hätten. Wir klicken auf “Allocate new address”, um eine zu erstellen.

Oder alternativ:
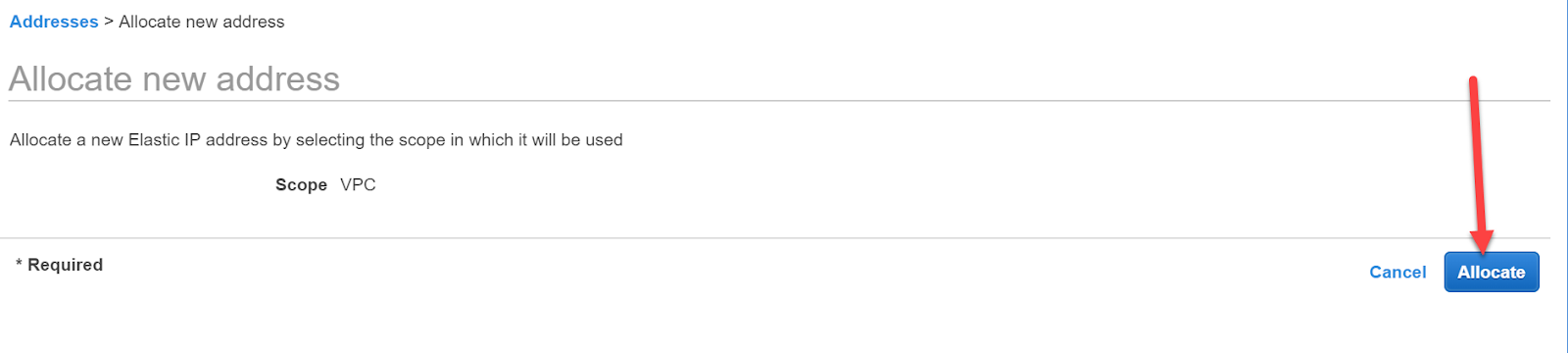
Im EC2-Dashboard, klicken wir auf unsere Instanz und im Actions-Menu auf Manage IP Addresses

Wir erhalten eine Übersicht über die IP-Adressen der Instanz und die Möglichkeit, eine elastische IP-Adresse zuzuordnen.
Wir klicken auf diese Option:
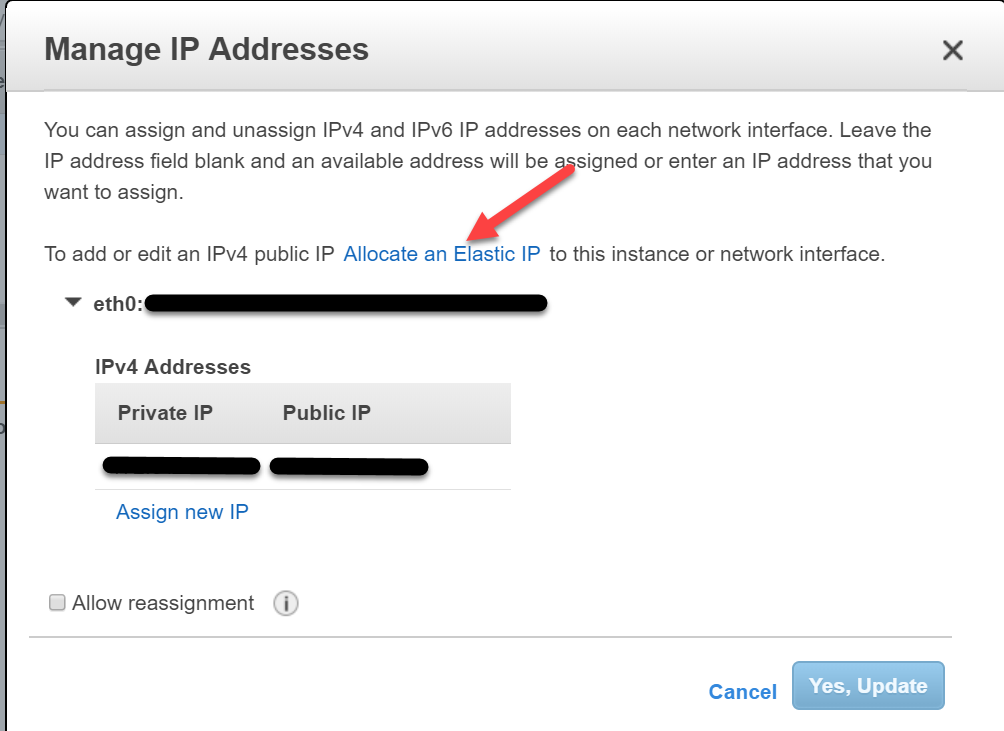
Auf der folgenden Seite, klicken wir auf Allocate.
Wir erhalten die neue IP-Adresse mitgeteilt und merken uns diese, bevor wir auf “Close” klicken.

Wir werden zurück auf die Übersicht der Elastic IP-Adressen geführt und sehen, dort diese IP-Adresse als erste in einer Liste.

Wir selektieren die Adresse und klicken auf Action. Mit dem Menu-Punkt “Associate address” können wir diese IP-Adresse jetzt einer Instanz zuordnen.

Auf der folgenden Seite können wir die Instanz wählen und auch die private IP-Adresse. Wir treffen eine Auswahl für beides und klicken auf “Associate”.
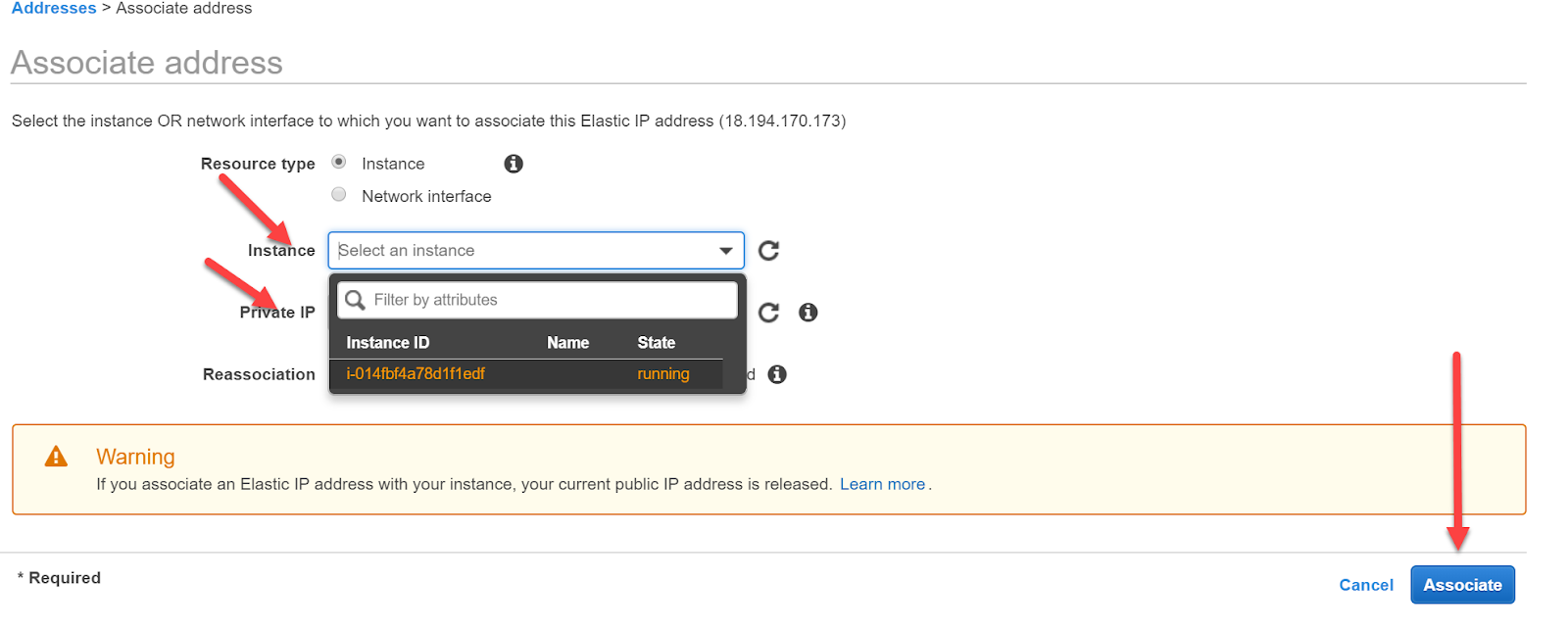
Dann erhalten wir eine Bestätigung, die wir mit “Close” schließen.
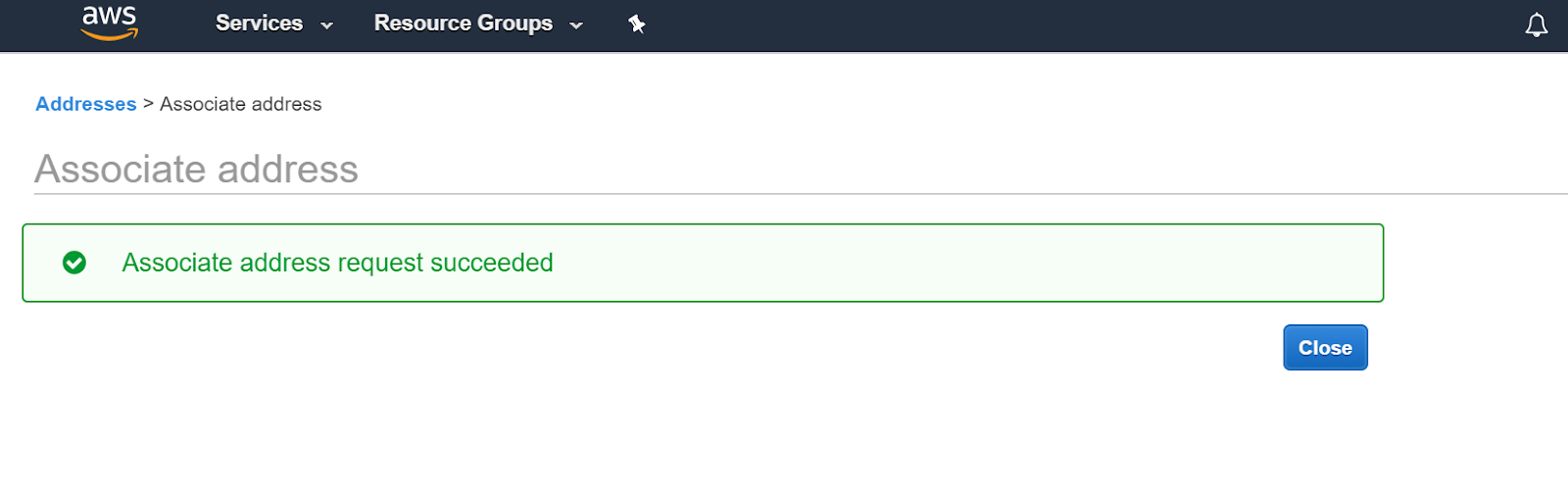
Wir verzweigen zurück aufs EC2 Dashboard und sehen, dass die neue Elastic IP Adresse unserer Instanz zugeordnet wurde.
Jetzt können wir die Probe aufs Exempel machen und mit ssh einloggen und dabei die Elastic IP Adresse angeben.
Weitere Instanzen allozieren
Jetzt, wo wir die erste Instanz erstellt haben, können wir diese vervielfachen, um anschließend unseren Cluster aufzubauen.
Wir klicken auf Actions und wählen “Launch More Like This”.
Jetzt werden wir aufgefordert, uns um die Security zu kümmern und eine neue Security Group einzurichten.

Damit können wir steuern, welche Ports auf unseren Instanzen offen sind, und von welchen IP-Adressen aus darauf zugegriffen werden kann. Eine Regel ist bereits vorhanden: wir können mit ssh von allen IP-Adressen aus auf diese Instanz zugreifen. Wir haben ja den ssh-Zugang mit dem Schlüsselpaar gesichert. Falls wir sicher sind, immer mit derselben IP-Adresse ins Internet zu gehen, dann können wir hier eine zusätzliche Regel definieren und diese IP-Adresse angeben.
Anschließend klicken wir auf Launch
Wir werden aufgefordert, ein Schlüsselpaar zu wählen und sollen bestätigen, dass wir das zugehörende .pem-File besitzen. Jetzt klicken wir auf Launch Instances

Diese Nachricht kennen wir schon und wir bestätigen sie mit “View Instances”
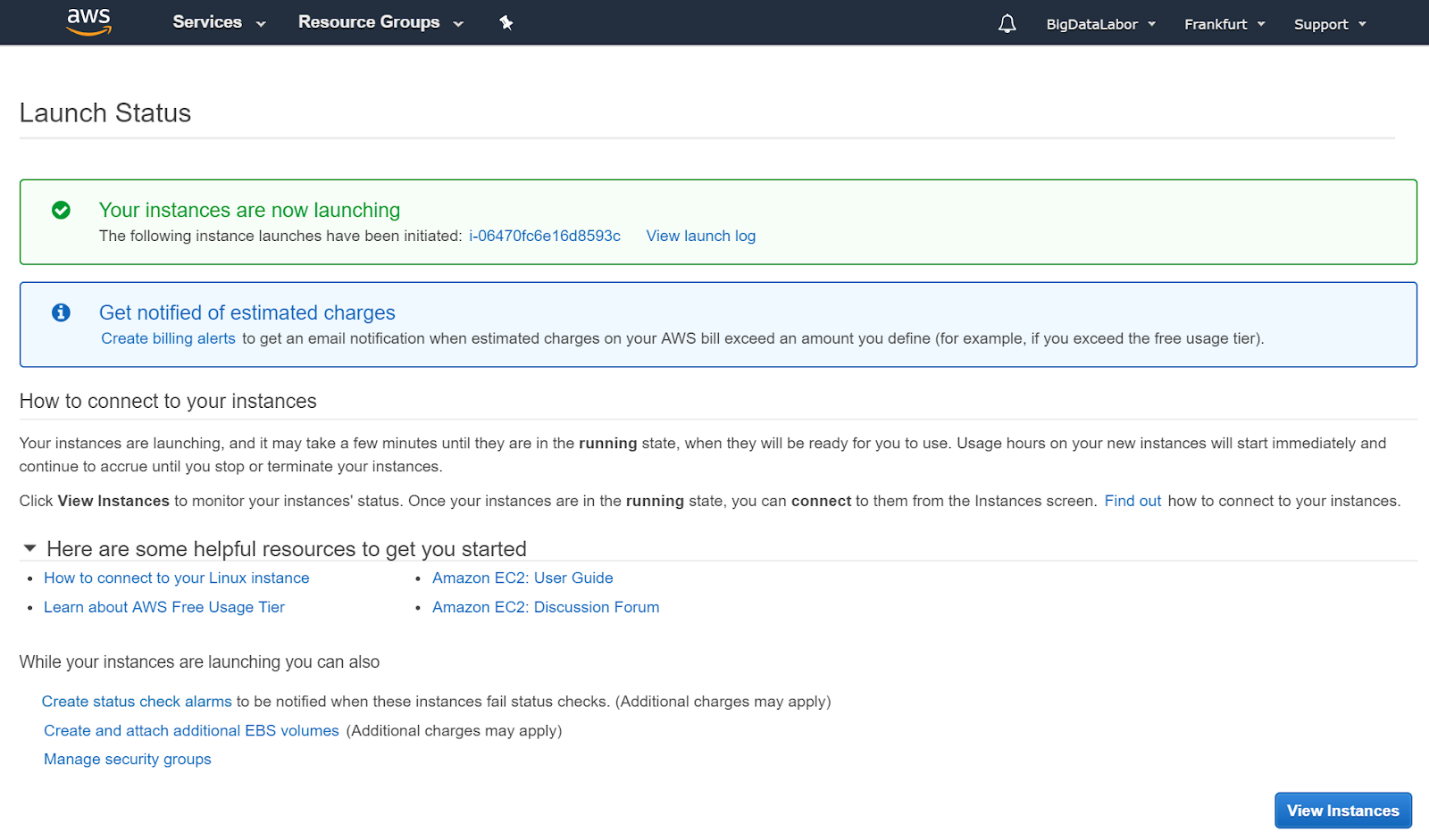
Wir sehen jetzt, dass eine weitere Instanz angelegt wird und bereiten gleich die passende Elastic IP Address dafür vor und ordnen sie auch gleich der neuen Instanz zu.
So erstellen wir vorerst insgesamt fünf Instanzen.
Hostnamen für das Big Data Labor vorbereiten
Im nächsten Schritt definieren wir die Hostnamen und “stellen” die einzelnen Server einander vor.
Dazu erstellen wir die folgende Liste
| Public IP Address | Private IP Address | Hostname |
| pi-201 | ||
| pi-202 | ||
| pi-203 | ||
| pi-204 | ||
| pi-205 |
In der Tabelle tragen wir die Paare von öffentlichen (public) und privaten IP-Adressen ein. Diese können wir in der EC2-Konsole ablesen und der Reihe nach in die Tabelle schreiben.
Wir loggen jetzt der Reihe nach in die virtuellen Maschinen auf AWS ein. Dazu verwenden wir die öffentliche IP-Adresse gemäss der ausgefüllten Liste.
Auf jeder virtuellen Maschine verändern wir die beiden Files
- /etc/hostname
- /etc/hosts
Dazu verwenden wir unseren Lieblingseditor, beispielsweise vi oder nano.
sudo vi /etc/hostname
Auf der ersten Zeile steht der Hostname, den AWS vergeben hat. Wir löschen die Zeile und fügen den Hostnamen ein, den wir in der Liste oben ablesen. Also z.B.
pi-201
Und wir speichern das File.
Das Big-Data Labor wird sich auf diese Hostnamen beziehen. Wer andere Hostnamen haben möchte, fügt noch eine weitere Spalte in die Liste ein und erhält so eine Übersetzungsliste für das Big Data Labor.
Jetzt editieren wir die das zweite File:
sudo vi /etc/hosts
Wir fügen die folgenden Zeilen an:
Private-IP-Adresse-von-pi-201 pi-201
Private-IP-Adresse-von-pi-202 pi-202
Private-IP-Adresse-von-pi-203 pi-203
Private-IP-Adresse-von-pi-204 pi-204
Private-IP-Adresse-von-pi-205 pi-205
und wir speichern das File.
Das könnte beispielsweise so aussehen:
127.0.0.1 localhost
192.168.2.201 PI-201
192.168.2.202 PI-202
192.168.2.203 PI-203
192.168.2.204 PI-204
192.168.2.205 PI-205
Die erste Spalte in der Liste muss die privaten IP-Adressen enthalten. Diese werden anders lauten, also im Beispiel dargestellt.
Damit die Änderungen aktiv werden, starten wir die Instanz neu
sudo shutdown -r now
Der Prompt sollte jetzt sein:
ubuntu@pi-201:
Falls wir auf dem gewohnten Weg in pi-201 einloggen.
Schlussbemerkungen
Das freie AWS-Kontingent beinhaltet eine gewisse Stundenzahl pro Monat für T2.Micro-Instanzen. Wenn jetzt zwei Instanzen jeweils gleichzeitig eine Stunde lang laufen, dann zählt AWS dafür zwei Stunden.
Wir können die Instanzen auch wie folgt herunterfahren:
sudo shutdown -h now
Zum Neustarten verwenden wir die EC2-Konsole, wie oben aufgeführt.
Damit haben wir dieselben Voraussetzungen für das Big Data Labor geschaffen, wie auch im Tutorial für VirtualBox und für Raspberry Pi beschrieben.
Im ersten Tutorial zum Big Data Labor werden wir Apache Hadoop kennen lernen.
Bildnachweis
Alle Bilder sind Screenshots von AWS / Amazon mit Ausnahme des Bildes im Kapitel Public und Private IP Adressen. Bei diesem handelt sich um eine eigene Darstellung.