
Big Data Training
Real Time Big Data – Basics
Starte mit Stream Processing und Stream Analytics
Theorie und Hands-On, selbstgesteuert und online

Geht es dir aktuell auch so, wie vielen anderen Data Engineers, System Architekten, Data Analysten, Programmieren, Projektleitern?
- Du stehst vor der Herausforderung, eine Real Time Data Pipeline zu bauen, und weißt nicht, wo anfangen.
- Du musst entscheiden, ob sich Big Data und Real Time Big Data für dein Projekt lohnen.
- Du möchtest dir zielgerichtet, solides Grundwissen aneignen, um in die Welt der Real Time Verarbeitung großer Datenströme einzusteigen.
- Du hast gesehen, dass es Hunderte von Big Data Tools gibt und versuchst, die Zusammenhänge zu verstehen.
- Du suchst nach typischen Architektur-Mustern für Big-Data Anwendungen.
- Du fragst dich, ob du die Big Data Infrastruktur nicht on premise aufbauen solltest.
- Du möchtest eine Einführung in die Handhabung typischer APIs zur Echtzeitanalyse.
- Du suchst nach sinnvollen Evaluationskriterien für Big Data Tools und insbesondere zur Echtzeitanalyse großer Datenströme.
- Du willst sofort mit einem fundierten Big Data Training anfangen und dieses auf deinem eigenen Laptop absolvieren.
Jetzt ist ein guter Zeitpunkt, um einzutauchen ins Universum der Echtzeitverarbeitung großer Datenströme.
Real-Time Verarbeitung und Big-Data-Analysen sind auf dem Vormarsch,
typische Architekturmuster etablieren sich
und die Tools werden reif für breitgefächerte Anwendungen.
Es gibt zahllose Anwendungsfälle
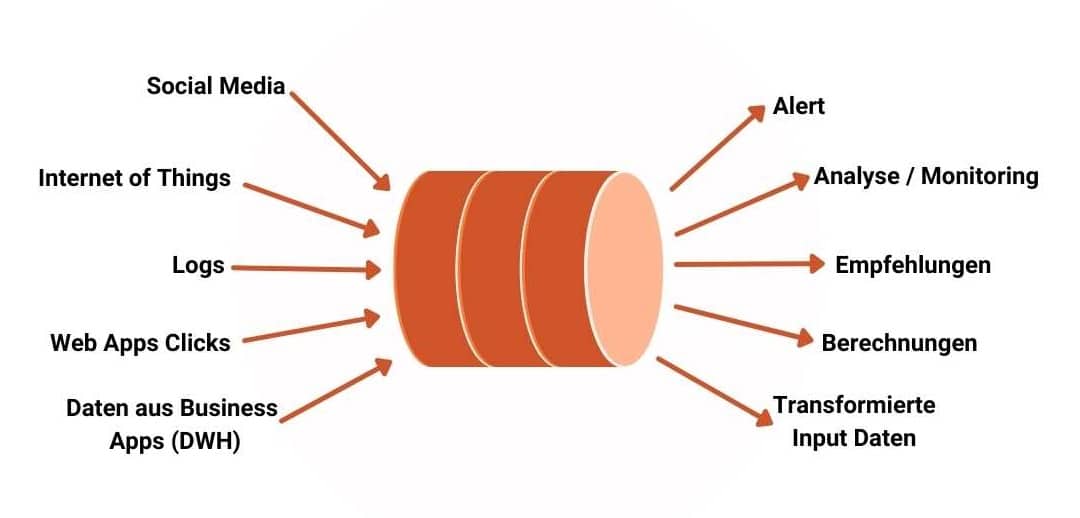
Mit dem richtigen herstellerunabhängigen Schritt-für-Schritt Online-Training, das dir ALLES zeigt, was du brauchst, um erfolgreich mit Real-Time Big Data Technologien durchzustarten, wirst du schon bald mitreden können und gezielt deine Herausforderungen angehen
… um deine eigene Echtzeitanalyse Plattform aufzubauen.
- Für immer mehr Informatikerinnen und Informatiker sind konfrontiert mit der Verarbeitung und Analyse sehr großer Datenmengen.
- Real-Time Big Data wird in wenigen Jahren weit verbreitet sein. Jetzt in diese Welt einzusteigen, eröffnet dir eine Vielzahl an Wahlmöglichkeiten für zukünfigte Projekte.
- Du kannst entscheiden, ob klassische Technologien besser geeignet sind oder, ob es sich für das Vorhaben lohnt, auf verteilte Big-Data-Tools zu setzen.
- Und du kannst qualifiziert abwägen, ob es sich lohnt, die Infrastruktur on premise aufzubauen, oder ob eine Cloud-Lösung besser geeignet ist.
Real Time Big Data – Basics
Das umfassende selbstgesteuerte online Training, um erfolgreich durchzustarten in die Welt der Analyse großer Datenströme.
Am Ende dieses Trainings hast du Folgendes gelernt:
- Du kennst die typische Architektur einer Real Time Big Data Pipeline.
- Du hast mit Apache Kafka, Apache Spark, Apache Cassandra typische Vertreter für Tools in einer Real-Time-Pipeline hands-on kennen gelernt.
- Du hast ein Cluster aufgesetzt, die Tools der Pipeline deployed und eine real-time Analyse mit Hilfe der Python-APIs erstellt.
- Du kennst typische Herausforderungen der verteilten Analyse und Verarbeitung sehr großer Datenströme und kannst die notwendigen Vorkehrungen treffen.
- Du kennst das typische Wording der Big Data Real Time Analytics und kannst die wichtigsten Konzepte erklären und einordnen.
- Du bist bereit, eine eigene Evaluation zu erstellen und einen eigenen PoC durchzuführen.
Das Real-Time Big Data Online Training führt dich Stufe für Stufe in die Tiefen des Wissens über die Echtzeitanalyse großer Datenströme
Stufe 1 - Das Gesamtbild
Du gewinnst einen Gesamtüberblick über eine Real-Time Pipeline:
- Du lernst ein typisches Architekturpattern kennen.
- Du lernst typische Tools und deren Architektur kennen – besonders im Hinblick auf verteiltes Rechnen.
- Du machst erste Hands-On Erfahrungen.
Stufe 1
Stufe 2 – Deep Dive
Du erstellst deine Real-Time Big Data Pipeline
- Du erstellst ein eigenes Cluster in einer verteilten Umgebung.
- Auf dem Cluster deployst du die Tools der Real-Time Pipeline.
- Du erstellst das Monitoring der Tools und lernst das Verhalten der einzelnen Komponenten einschätzen.
- Du erstellst eine End-to-End Real-Time Pipeline mit einer einfachen Visualisierung der Analyse mit Python.
Stufe 2
Stufe 3 – Die Zusammenhänge
In Stufe 3 steigst du tief herab in die Theorie der verteilten Systeme in deiner Pipeline.
Du erfährst, welche Trade-Offs diese Tools eingehen und wie du mit den Trade-Offs umgehst, insbesondere beim Zusammenschalten mehrerer Tools zu einer Pipeline.
Stufe 3
Zusammenfassung Real Time Big Data Basics
Mit dem 3-Stufen Online Training bekommst du eine umfassende Einführung in die Welt der Echtzeitanalyse großer Datenströme. Du lernst eine typische Architektur kennen und machst Hands-On Erfahrungen mit einigen typischen Tools. Nach dem Kurs bist du in der Lage, deine Kenntnisse selbständig zu vertiefen und zukünftige Trends einzuschätzen. Du gehst zielgerichtet vor bei der Evaluation weiterer Tools und kannst passende Kriterien für einen Proof of Concept für deinen Anwendungsfall zusammenzustellen.
Das Training ist 100% online selbstgesteuert. Es umfasst Folgendes:
Stufe 1: Das Gesamtbild
Überblick über Pipeline, sowie typische Tools und Architekturen (Video-Vorträge) (Wert: 500 €)
Konfigurierte virtuelle Maschine (VirtualBox oder Parallels) (Wert: 300 €)
Hands-On Übungen (Video-Demos und Skripte) (Wert: 300 €)
Stufe 2: Deep Dive
Schritt für Schritt Tutorial zum verteilten Deployment der Real-Time Pipeline (Wert: 700 €)
Schritt für Schritt Tutorial für die Event-Time Analyse (Wert: 500 €)
Q&A zu Stufe 2 (Wert: 300€)
Stufe 3: Die Zusammenhänge
Theorie zu verteilten Systemen erläutert anhand der Beispiele der Pipeline aus Stufe 2. (Video-Vorträge) (Wert: 500 €)
Zugang zum Online-Training und allen Updates und Erweiterungen während einem Jahr. (Wert: 300 €)
Gesamtwert des Trainings: 3400 €
Zusätzlich bekommst du dieses interessante Bonuspaket dazu:
Erkunde dein Bonus-Paket
 Bonus 1
Bonus 1
eBook: Cluster aus Virtuellen Maschinen für VirtualBox
Ein Schritt-für-Schritt-Tutorial zum Aufbau einer kleinen Laptop-Cloud
Passend zu Stufe 1 als Einstimmung auf Stufe 2
 Bonus 2
Bonus 2
eBook: Trainings-Cluster mit Raspberry Pi – VirtualBox – AWS
Das beliebte eBook mit drei ausführlichen Anleitungen zum Aufbau eines Trainings-Clusters.
Passend zu Stufe 2
 Bonus 3
Bonus 3
eBook: Systeme koordinieren mit Apache ZooKeeper
Eine detaillierte Erläuterung zu Apache ZooKeeper, dem Koordinationsservice für verteilte Systeme der selbst ein verteiltes System ist.
Passend zu Stufe 2 als Einstimmung auf Stufe 3
 Bonus 4
Bonus 4
eBook: Real-Time Streaming Pipelines
Architekturen und Konzepte zur Echtzeit-Analyse großer Datenströme am Beispiel von Apache Kafka und Apache Spark.
Passend zu Stufe 3
Du bist hier richtig wenn
- Als Informatikerin oder Informatiker hast du erkannt, dass Big Data Streaming resp. Real-Time Big Data an Stellenwert gewinnt und du möchtest jetzt damit anfangen.
- Du stehst vor der Herausforderung, ein Big Data Projekt zu beginnen, und weißt nicht, wo anfangen.
- Du musst entscheiden, ob sich Big-Data Technologien für dein lohnen und suchst nach den geeigneten Entscheidungskriterien.
- Du suchst nach typischen Architektur-Mustern für Big Data Anwendungen und den für die Realisierung geeigneten Tools.
- Du möchtest verstehen, das es bedeutet, eine Big Data Infrastruktur on-premise aufzubauen, um abzuwägen, ob eine Cloud-Lösung nicht besser geeignet ist.
- Du möchtest eine Real-Time Pipeline bauen und willst einen soliden theoretischen Hintergrund, um qualifizierte Entscheidungen zu fällen.
Surfe weiter, falls einer der folgenden Punkte zutrifft
- Du möchtest in die Informatik einsteigen, und hast gehört, dass Big Data die Zukunft ist.
- Du suchst nach Online-Tutorials, um dich dort durchzuklicken.
- Du hast absolut keine Programmierkenntnisse und hoffst, diese in diesem Training zu erwerben.
- Die Arbeit auf der Command-Line ist für dich ein absolutes No-Go, auf bequeme User-Interfaces kannst du nicht verzichten.
- Du hast noch nie mit Linux zu tun gehabt und willst dich bestimmt nicht damit befassen wollen.
- Du hast noch nie eine Datenanalyse mit SQL erstellt und willst dich nicht mit SQL befassen.
- Du erwartest, in diesem Training, zu lernen, wie man KI-Modelle erstellt.
- Du erwartest, von diesem Training eine Ausbildung als Daten-Analyst erwartest.
Warum ich dir helfen kann
 Nach meinem Studium in Mathematik und Informatik hatte ich immer mit sehr großen Datenmengen zu tun. Beginnend als Programmiererin belegte ich viele verschiedene Rollen.
Nach meinem Studium in Mathematik und Informatik hatte ich immer mit sehr großen Datenmengen zu tun. Beginnend als Programmiererin belegte ich viele verschiedene Rollen.
Komplexe Systeme, Data Engineering und Data Management bilden einen roten Faden in meiner bisherigen beruflichen Laufbahn.
Seit mehr als 20 Jahren unterrichte ich auch mit Herzblut an verschiedenen Schweizer Fachhochschulen in meinen Kerngebieten.
Mit dem Big Data Training helfe ich Informatikerinnen und Informatikern die Lernkurve zu verkürzen beim Einstieg in Big-Data-Technologien.
Ursula Deriu
Du bringst die folgende Infrastruktur mit:
- Für Stufe 1 des Trainings:
- Ein Laptop (Windows oder Mac) mit 16GB RAM und ca. 20 GB freiem Festplattenplatz für Stufe 1 des Trainings
- VirtualBox oder Parallels für die Ausführung des Hands-On-Trainings
- Für Stufe 2 des Trainings benötigst du eine der folgenden Infrastruktur-Optionen
- Ein Laptop (Windows oder Mac) mit 16GB RAM und min. 40 GB freiem Festplattenplatz, oder
- Minimum 5 Raspberry Pi, einen Switch und weiteres Zubehör (wird im Training genau beschrieben), oder
- Einen Account bei einem Cloud Provider, z.B. AWS.
Du benötigst die folgenden Vorkenntnisse:
- Ausbildung resp. Berufserfahrung als Informatikerin oder Informatiker,
- Grundkenntnisse in einer Programmiersprache,
- Python-Kenntnisse sind von Vorteil,
- Grundkenntnisse in SQL sind von Vorteil,
- Kenntnisse der grundlegendsten Linux Commands sind von Vorteil.
7 Tage Geld-zurück-Garantie
Lass mich dir eines vorweg sagen: Das Real Time Big Data Grundlagen-Training ist ein umfangreicher Kurs, der dir als Informatikerin oder Informatiker den Start in die Welt der großen Datenströme erleichtert.
Der Inhalt des Online Trainings könnte auch in einem On-Site Intensiv-Training von 4 Tagen vermittelt werden.
Im Online Training hingegen bestimmst du das Tempo selbst und kannst die Schritte beliebig oft wiederholen.
Solltest du innerhalb von 7 Tagen nach dem Buchen bemerken, dass das Training deinen Erwartungen nicht entspricht, dann meldest du dich bei mir und bekommst dein Geld zurück.
Dein Erfolg ist auch mein Erfolg.
Starte sofort – buche jetzt

Nimm jetzt teil am Real-Time Big Data Grundlagen Training und profitiere vom einmaligen Early-Access Angebot.
So funktioniert das Early Access Angebot:
Du profitierste jetzt vom Early Access Angebot und erhältst sofort Zugang zu Stufe 1 des Trainings und zum Bonus von Stufe 1.
Füllst du den Feedback-Bogen auf der Lernplattform aus und gibst auch ein Testimonial ab, dann wirst du Zugang zu Stufe 2 des Trainings und den Boni zu Stufe 2 erhalten, sobald alles verfügbar ist. Aktuell geplanter Termin: Juni 2022
Füllst du danach wieder einen Feedback-Bogen auf der Lernplattform aus und gibst erneut ein Testimonial ab, dann wirst du Zugang zu Stufe 3 und den Boni zu Stufe 3 erhalten, sobald alles verfügbar ist. Aktuell geplanter Termin: August 2022
Füllst du danach wieder einen Feedback-Bogen auf der Lernplattform aus und gibst erneut ein Testimonial ab, dann erhälst du im Gegenzug Zugang zum Online Training, so lang wie dieses besteht und damit natürlich auch zu allen Anpassungen und Erweiterungen des Trainingsinhalts.
Lass dir dieses einmalige Early-Access Angebot nicht entgehen und Buche das Training jetzt zu einem Drittel des Preises des ganzen Trainings.


€ 497,00
Melde dich noch heute an für Real Time Data Basics
Du erhältst folgendes:
- Sofort Zugriff nach abgeschlossener Buchung auf Stufe 1 des Trainings
- Freischaltung weiterer Stufen nach Feedback und Testimonial und sobald die Stufen fertiggestellt sind


Hast du noch mehr Fragen zu diesem Training?
Dann klick dich durch die folgende FAQ!
An wen richtet sich das Training?
Die Trainings richten sich an
- Data Engineers
- Daten Analysten
- Systemverantwortliche
- Projektleiterinnen und Projektleiter
- Systemarchitekteninnen und Systemarchitekten
- Erfahrene Informatikerinnen und Informatiker im Interesse am Thema
Ist das Training für mich?
Das Training richtet sich an Informatikerinnen und Informatiker, die
- sich für in Real-Time Stream Processing und Analytics interessieren und hinter die Kulissen der APIs blicken möchten;
- die ein Grundverständnis für die Komplexität der verteilten Big-Data-Systeme aufbauen möchten;
- die anhand eines soliden Verständnisses von Konzepten in Real-Time Pipelines in der Lage sein wollen, selbständig Details der Stream Analytics und des Stream Processings zu vertiefen.
Von Vorteil ist es, wenn du
- Grundkenntnisse von Linux mitbringst, insbesondere Bash-Befehle wie ls, mkdir, chown und andere;
- Grundkenntnisse von Python mitbringst;
- Grundkenntnisse von SQL mitbringst;
- oder bereit bist dir während des Trainings diese Kenntnisse anzueignen.
Welches sind die Lernziele?
Die Teilnehmenden …
- können erläutern, warum für das ausfallfreie Verarbeiten großer Datenbeständen verteilte Systeme eingesetzt werden;
- kennen die Trade-Offs, die verteilte Systeme für die Stream Analytics mit sich bringen;
- kennen die wichtigsten Commit-Protokolle in verteilten Systemen und die Beschränkungen, die sich daraus ergeben;
- kennen die markantesten Architekturen verteilter Systeme;
- können die wichtigsten Open-Source-Frameworks für Stream Processing und Stream Analytics benennen und in Kategorien einteilen;
- kennen Herangehensweisen, wie einzelne Frameworks zu einer produktiven Stream Analytics Pipeline kombiniert werden;
- haben Hands-On-Erfahrungen mit den APIs von Apache Kafka und Apache Spark und kennen die Herausforderungen bei der Implementierung der Exactly-Once-Semantik;
- kennen Windows und Watermarks als wichtige Konzepte bei der Real-Time Analytics;
- können das Vorgehen zur Evaluation einer Pipeline für Ihren spezifischen Use-Case planen und kennen die wichtigsten Fragen, die ihr PoC klären sollte.
Auf welcher Lernplattform findets das Online-Training statt?
Die Lernplattform von Tirsus Online basiert auf der im Bildungswesen weltweit verbreiteten Plattform Moodle. Sie ist hervorragend geeignet für Fernunterricht und für selbstgesteuerte Kurse.

Der Screenshot zeigt ein Beispiel eines der vielen umfassenden Schritt-für-Schritt Tutorials zum Hands-On-Teil.
So fällt es leicht, die komplexen Zusammenhänge und Eigenschaften der Tools in einer Stream Analytics Pipeline zu “be-greifen”.
Welche Infrastruktur benötige ich?
Technische Voraussetzungen
Eine gute Internetverbindung ist Voraussetzung für jedes Online Training.
Für den Zugang zur Lernplattform
Die Tirsus Online Lernplattform basiert auf Moodle, die weltweit an Universitäten und anderen Bildungseinrichtungen im Einsatz ist. Chrome als Webbrowser funktioniert mit Moodle sehr gut.
Für eBooks
Wir liefern die eBooks im PDF-Format. Dieses ist weit verbreitet und kann mit kostenfreien Readern problemlos geöffnet werden.
Die Trainingsinfrastruktur
Als Trainingsinfrastruktur sind die folgenden drei Alternativen geeignet – das Vorgehen wird im Training detailliert beschrieben:
- Variante 1: Die Teilnehmenden bauen eine eigene Big-Data-Stream Analytics Pipeline mit minimalen Ressourcen auf. Als Minimal-Ausstattung sollten auf dem Laptop mit VirtualBox oder Parallels mindestens 5 virtuelle Maschinen gleichzeitig laufen können. Je mehr, desto besser.
- Varaiante 2: Als interessante Alternative kann ein Raspberry Pi Cluster aufgebaut werden. Mit mindestens 5 Raspberry Pi Model 3B kann ein minimales Cluster gebaut werden. Mit einem zusätzlichen Model 4B mit mindestens 2GB RAM kann auch Apache Zeppelin auf Raspberry Pi betrieben werden. Damit können praktische Notebooks zur Datenanalyse erstellt werden.
- Als weitere Alternative können bei einem Cloud Provider, z.B. bei AWS, für die Dauer des Trainings minimale Instanzen (auch hier mindestens 5) gebucht werden. Die dafür anfallenden Kosten kontrollierst Du durch diszipliniertes Ausschalten der Instanzen am Ende einer Trainingssession.
Die Kosten für die Trainingsinfrastruktur ist in der Kursgebühr NICHT INBEGRIFFEN.
Ist das Training tatsächlich deutschsprachig?
Alle Trainingsunterlagen sind in deutscher Sprache verfasst. Das erleichtert den Einstieg in das neue Fachgebiet. Anglizismen und Fachjargon werden nicht ins Deutsche übertragen.
Wann erhalte ich Zugang zur Lernplattform?
Zugang zur Lernplattform
Du erhältst unmittelbar nach dem Buchen des Trainings Zugang zur Online Lernplattform.
Was bedeutet es, Member zu werden?
Die beiden Trainings werden im Tirsus Web Shop als sog. “Memberships” verwaltet. Eine Membership umfasst ein Produkt, das den Zugriff auf die Lernplattform für eine gewisse Zeit gewährt plus weitere Produkte, die im Paket inklusive sind. Mit der Lizenzierung eines solchen Pakets wirst du “Member” des Pakets für die Dauer der Laufzeit des Pakets.