Apache ZooKeeper ist ein kampferprobter Koordinationsdienst für verteilte Computer-Systeme. ZooKeeper wird in unterschiedlichsten Systemen eingesetzt. Als Dienst für Dienste tritt er nicht offen in Erscheinung und ist Vielen unbekannt. ZooKeeper kommt in Systemen zum Einsatz, die im Artikel Realtime Big Data Stream Processing beschrieben werden.
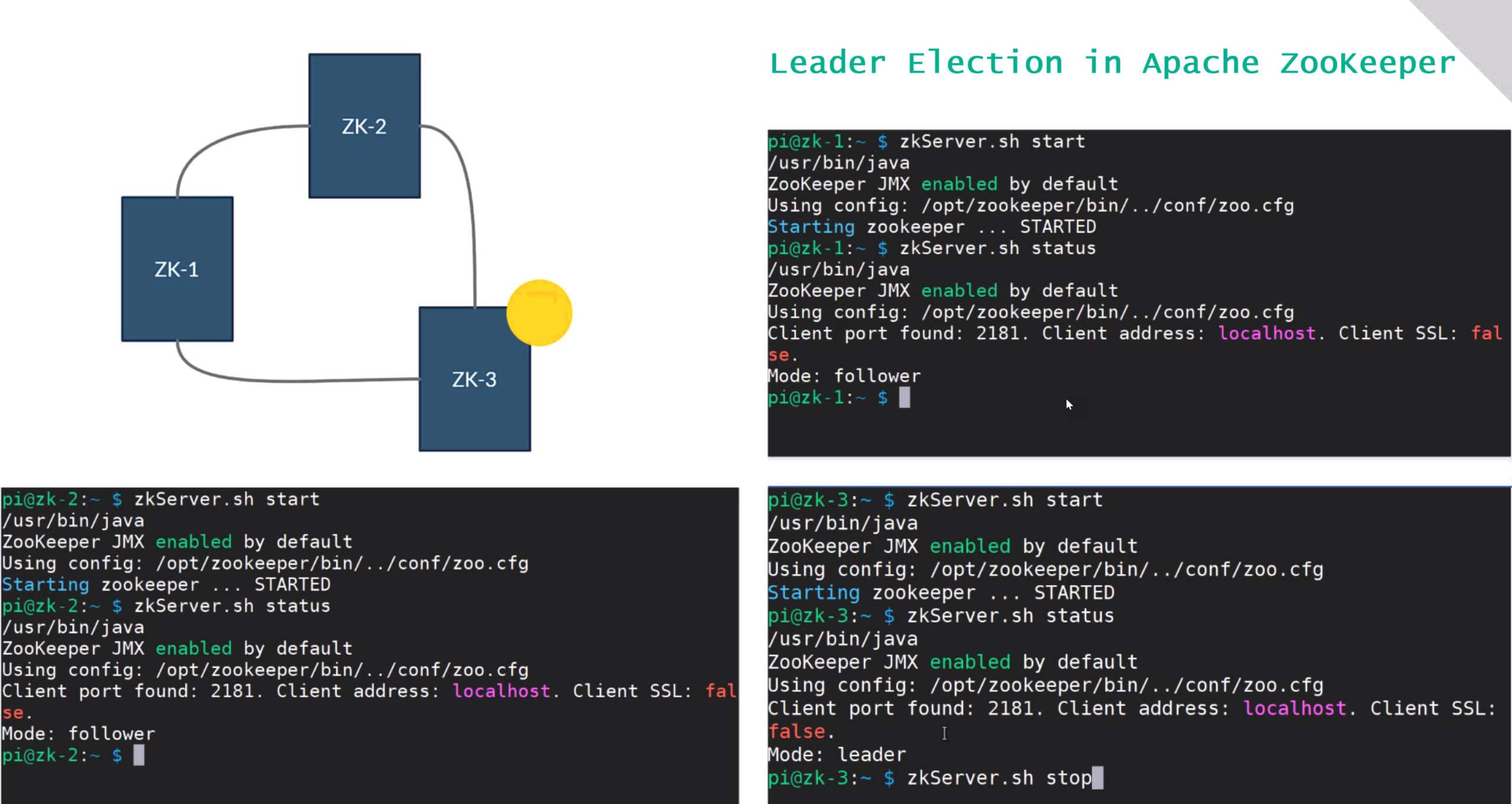
Der Big Data Nugget #1 befasst sich mit ZooKeeper und greift den Aspekt der Leader-Election in einem Peer-to-Peer System heraus. Alle Rechner im Verbund, also alle Nodes im Cluster, sind gleich berechtigt und doch muss einer davon die Rolle des Leaders übernehmen. Hauptaufgabe des Leaders ist es, die Konsistenz der Daten zu gewährleisten. In ZooKeeper kommt dabei das Zab-Protokollzum Einsatz. Das Quiz befasst sich mit den wichtigsten Eigenschaften der Leader-Election bei ZooKeeper. In Bezug auf diese Funktion kann das Zab-Protokoll mit dem Paxos Protokoll verglichen werden. Das Kurzvideo zeigt eine Einleitung und Demo von ZooKeeper.
Die Idee hinter Apache ZooKeeper ist bestechend einfach und bestens geeignet, um Konzepte des verteilten Rechnens kennen zu lernen.
Dieses eBooklet erläutert den Einsatz und die Funktionsweise von Apache Zookeeper auf konzeptioneller Ebene und zeigt so eindrücklich Wege auf, wie verteilte Systeme koordiniert werden können.
Wer mit virtuellen Maschinen arbeiten will, kann unter verschie denen Anbietern auswählen. Gerade im Ausbildungsbereich ist VirtualBox sehr beliebt, weil viele fürs Kennenlernen notwendige Funktionalitäten in der kostenlosen Version erhältlich sind.
Warum sollte man überhaupt eine Reihe von virtuellen Maschinen bei AWS oder einem anderen Cloud-Anbieter einrichten und anschließend das Hadoop Distributed Filesystem und andere Komponenten des Hadoop Ökosystems installieren? Immerhin bieten viele Cloud-Anbieter solche Komponenten vorgefertigt auf Knopfdruck.
Diese Frage ist leicht zu beantworten: Wer die grundsätzliche Funktionalität und die grundsätzlichen Zusammenhänge kennen lernen will, braucht eine Übungsumgebung.
Das Big Data Labor zeigt zu Beginn verschiedene Möglichkeiten, eine solche Übungsumgebung zu schaffen:
Oder eben in der Cloud, beispielsweise bei AWS (Amazon).
Wer produktiv arbeiten will, geht anders vor:
Baut eine produktiven Cluster auf, ähnlich wie im Tutorial mit Raspberry Pi gezeigt
Oder verwendet die vorgefertigten Komponenten bei einem Cloud-Anbieter.
Zusammenhänge begreift man am besten, indem man den Weg einmal selbst geht, alles aufbaut und untersuchen kann.
Bei AWS erhalten wir die für das Big Data Labor minimal notwendigen Ressourcen auch bis zu einem gewissen Grad kostenlos. Dieses Tutorial zeigt folgendes:
Wir setzen ein AWS-Konto auf und bewegen uns dabei möglichst im kostenlosen Rahmen.
Wir konfigurieren eine erste virtuelle Maschine mit Ubuntu Linux und nehmen sie in Betrieb
Wir versehen sie mit einer fest zugeordneten IP-Adresse
Wir vervielfachen diese virtuelle Maschine und sind damit bereit für das nächste Kapitel im Big Data Labor, den Aufbau von HDFS.
Notwendige Vorkenntnisse
Das Tutorial richtet sich an Informatiker mit Grundkenntnissen in Linux. Die Fähigkeit , einen kommandozeilenorientierten Editors wie vi oder nano zu bedienen, wird vorausgesetzt.
Ebenso vorausgesetzt wird das grundlegende Verständnis über den Aufbau von Computern und Netzwerken. IP-Adressen, ssh seien keine Fremdwörter.
Vorbereitung
Es ist praktisch, mit einer ssh-Konsole unter Linux/Mac zu arbeiten und der Einfachheit halber auch gleich diese ersten Einrichtungsschritte mit einem Browser auf einem Linux/Mac Desktop durchzuführen.
Wer mag, kann natürlich auch mit Windows/ssh arbeiten, verzichtet damit auf etwas Komfort. Wer einen Windows Laptop hat und dennoch mit Linux arbeiten möchte, kann eine einfache virtuelle Maschine einrichten. Dies ist im Tutorial Eine VirtualBox einrichten und klonen beschrieben. Mit einem kleinen Unterschied: statt als Gast das Server Betriebssystem zu installieren, lohnt es sich das Desktop-Betriebssystem zu nehmen. Für Ubuntu ist es hier zu finden: https://www.ubuntu.com/download/desktop
Es reicht, eine virtuelle Maschine aufzubauen, sie muss nicht geklont werden; dieser Schritt aus dem genannten Tutorial braucht nicht durchgeführt zu werden.
Firefox ist auf dem Ubuntu-Desktop vorinstalliert und Terminals lassen sich leicht öffnen: mit Rechtsklick auf den Desktop und Auswahl “Open Terminal” im Kontextmenü. Dann kann man viele Befehle auch mit copy-paste übernehmen. Dazu verwendet man das Kontextmenü, das man mit der rechten Maustaste öffnet. Dieser Desktop übernimmt die Rolle des mit PI-200 bezeichneten Rechners im Big Data Labor.
AWS Konto anlegen
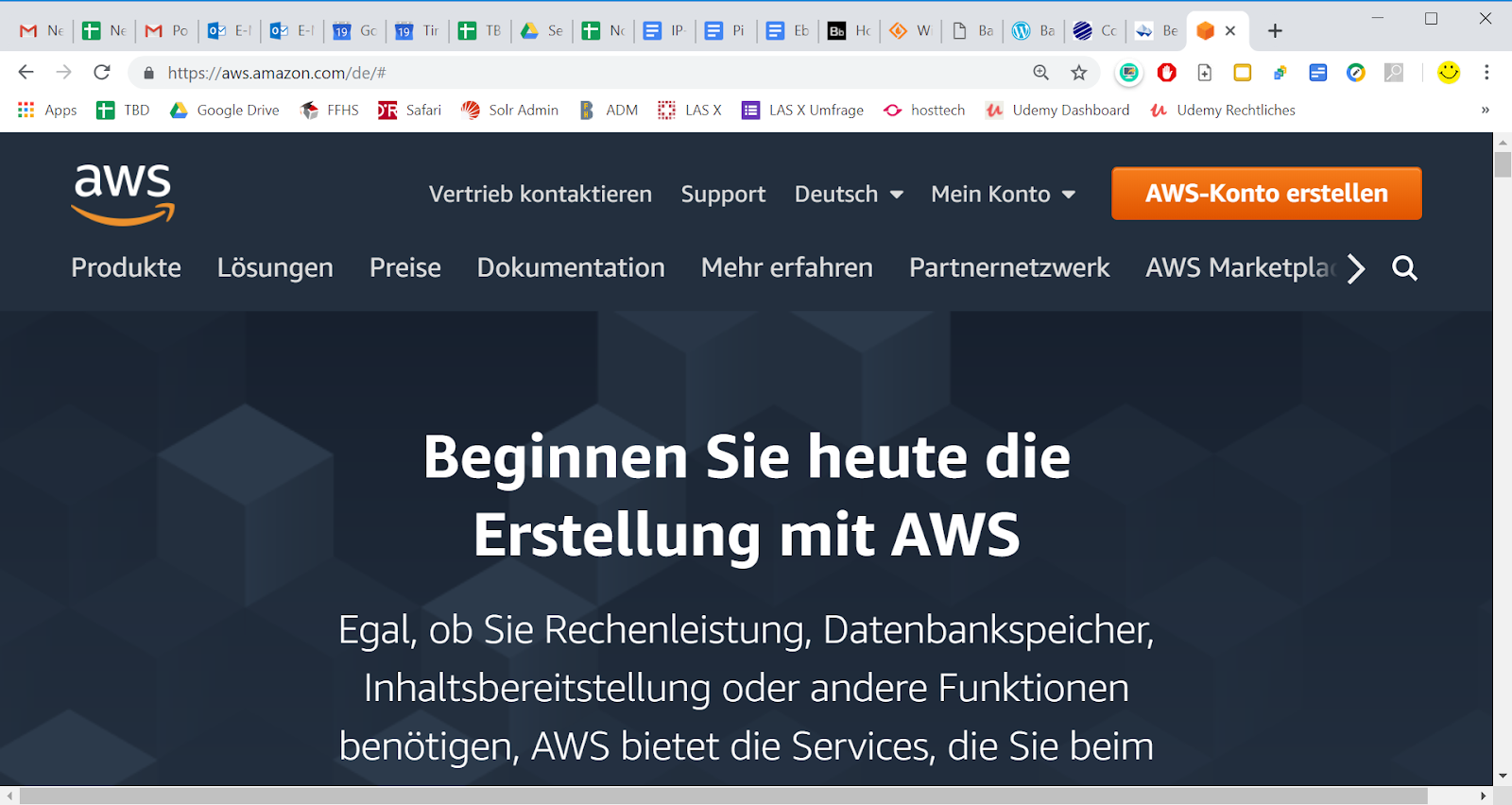
Falls wir noch kein AWS Konto haben, dann legen wir zuerst eines an. Wir öffnen in einem Browser die Url https://aws.amazon.com/de
AWS ist sehr reif und verändert diese grundlegende Funktionalität nur sehr moderat. Die Darstellungen können jedoch ändern und von denjenigen auf den Screenshots abweichen. Auf dieser Seite wählen wir oben rechts “AWS-Konto erstellen”.
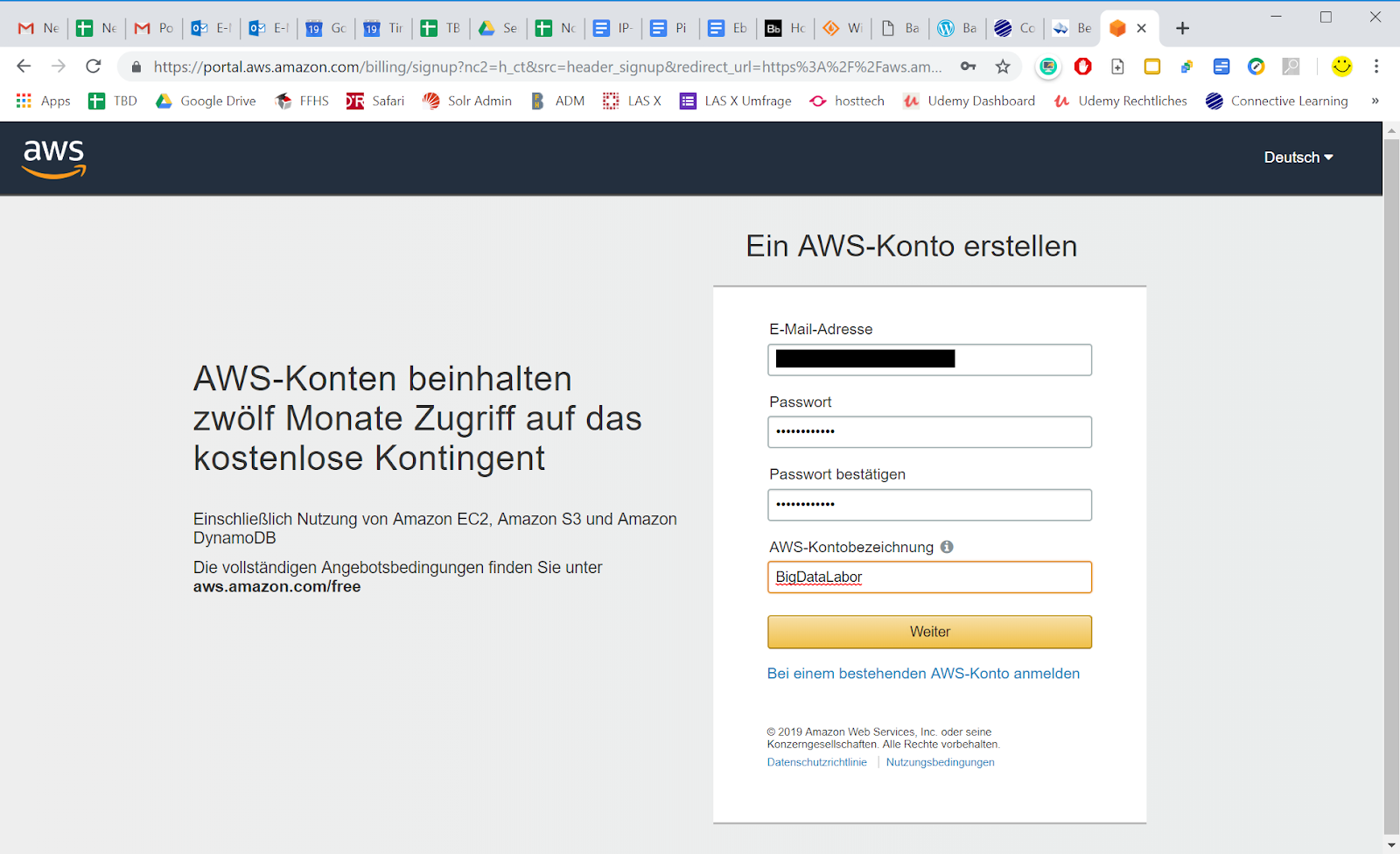
Die Benutzerführung ist intuitiv und wir machen die gewünschten Angaben. Wir nehmen auch zur Kenntnis, wie lange wir auf das kostenlose Kontingent zugreifen dürfen. Dabei müssen wir uns bewusst bleiben, dass dieses auch vor Ablauf der auf der Seite genannten Zeit (hier zwölf Monate) aufgebraucht werden kann.
Auf der nächsten Seite wählen wir den Kontotyp aus, Professional oder Privat, je nachdem, wie wir unterwegs sind. Und wir geben einen Namen und die weiteren notwendigen Angaben.
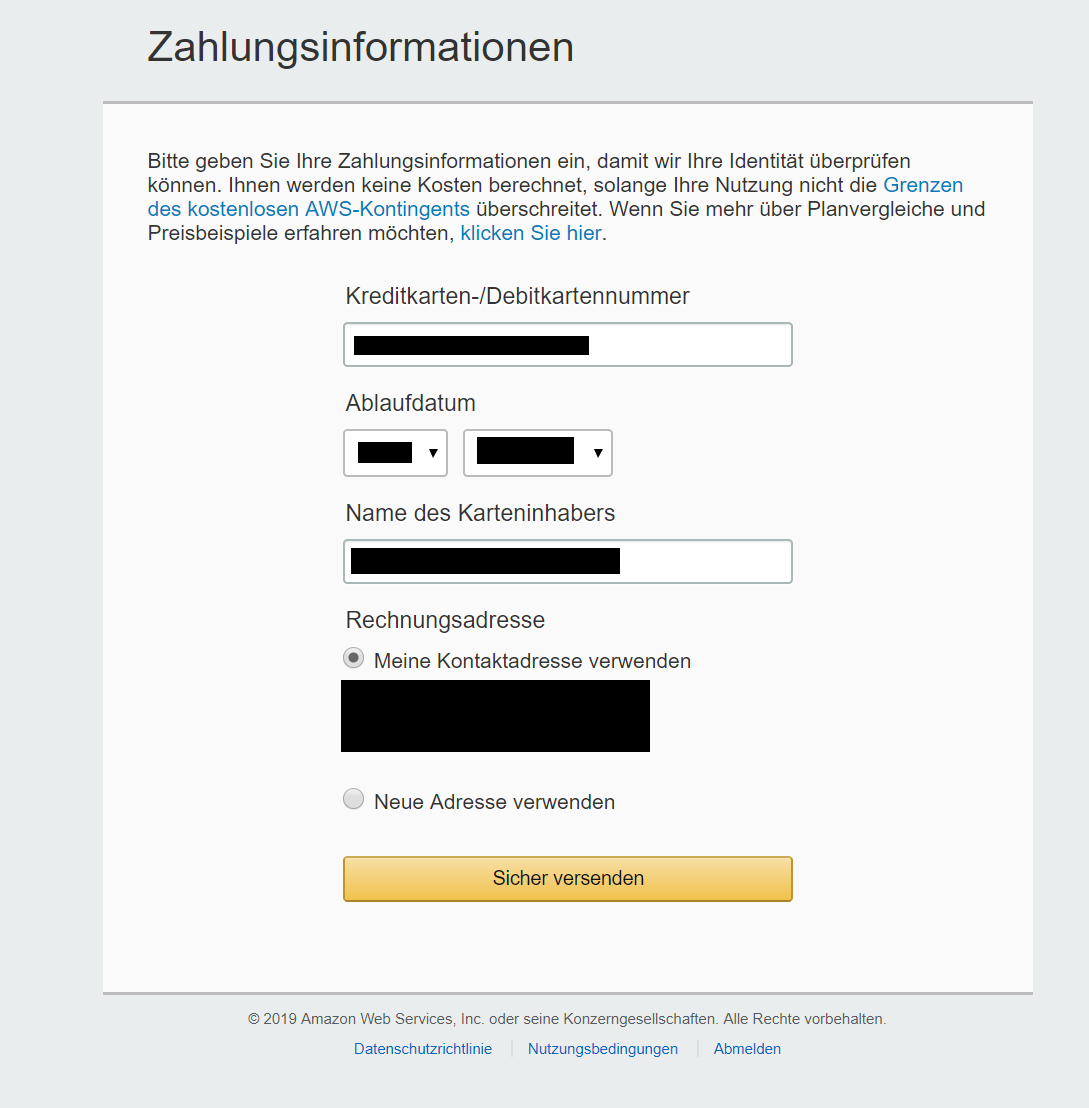
Ohne Zahlungsinformationen können wir kein Konto anlegen. Wir werden ein paar Seiten später sehen, wie wir einen Alert einrichten können, um rechtzeitig festzustellen, wenn wir unser Kontingent aufgebraucht haben.
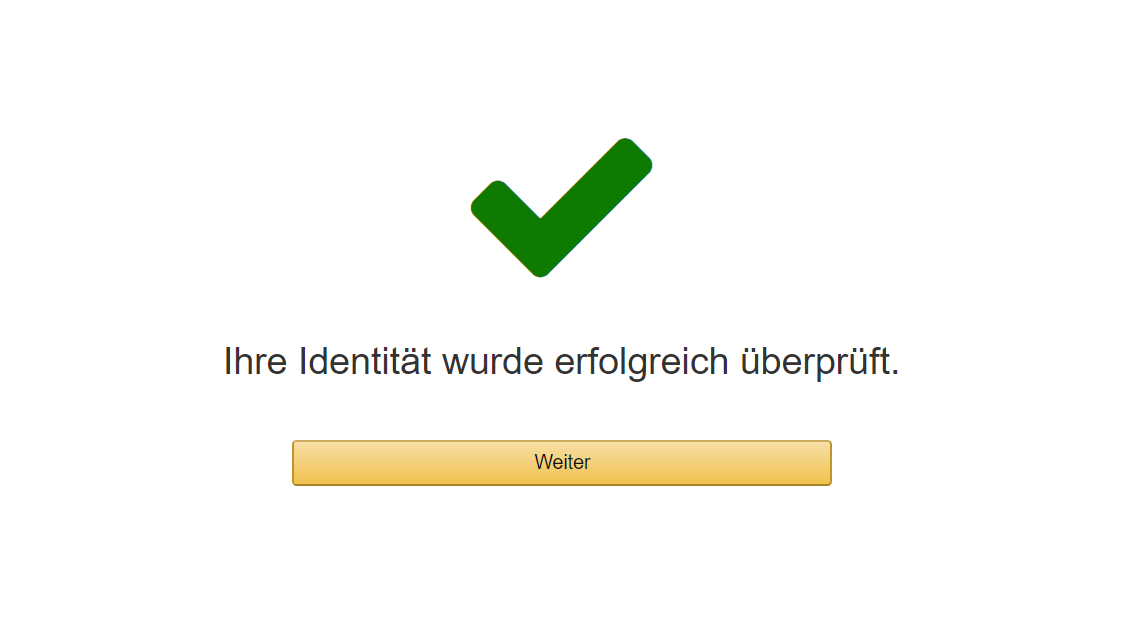
AWS will die Identität bestätigen und insbesondere auch automatisch angelegte Accounts verhindern. Hier wählen wir die Möglichkeit mit SMS. Wir geben das Land und die Telefonnummer an, und schreiben die Zeichenfolge auf der Sicherheitsprüfung ab.
Nachdem wir “Kontaktieren Sie mich” geklickt haben, erhalten wir nahezu sofort eine SMS auf der Telefonnummer. Diese enthält einen Code, den wir abtippen.
Wir klicken auf “Code verifizieren”. Klappt alles wie gewünscht, dann konnte die “Identität” überprüft werden.
Wir klicken auf “Weiter” und können einen Support Plan wählen. Für das Big Data Labor fangen wir mit dem Kostenlosen Basic Plan an.
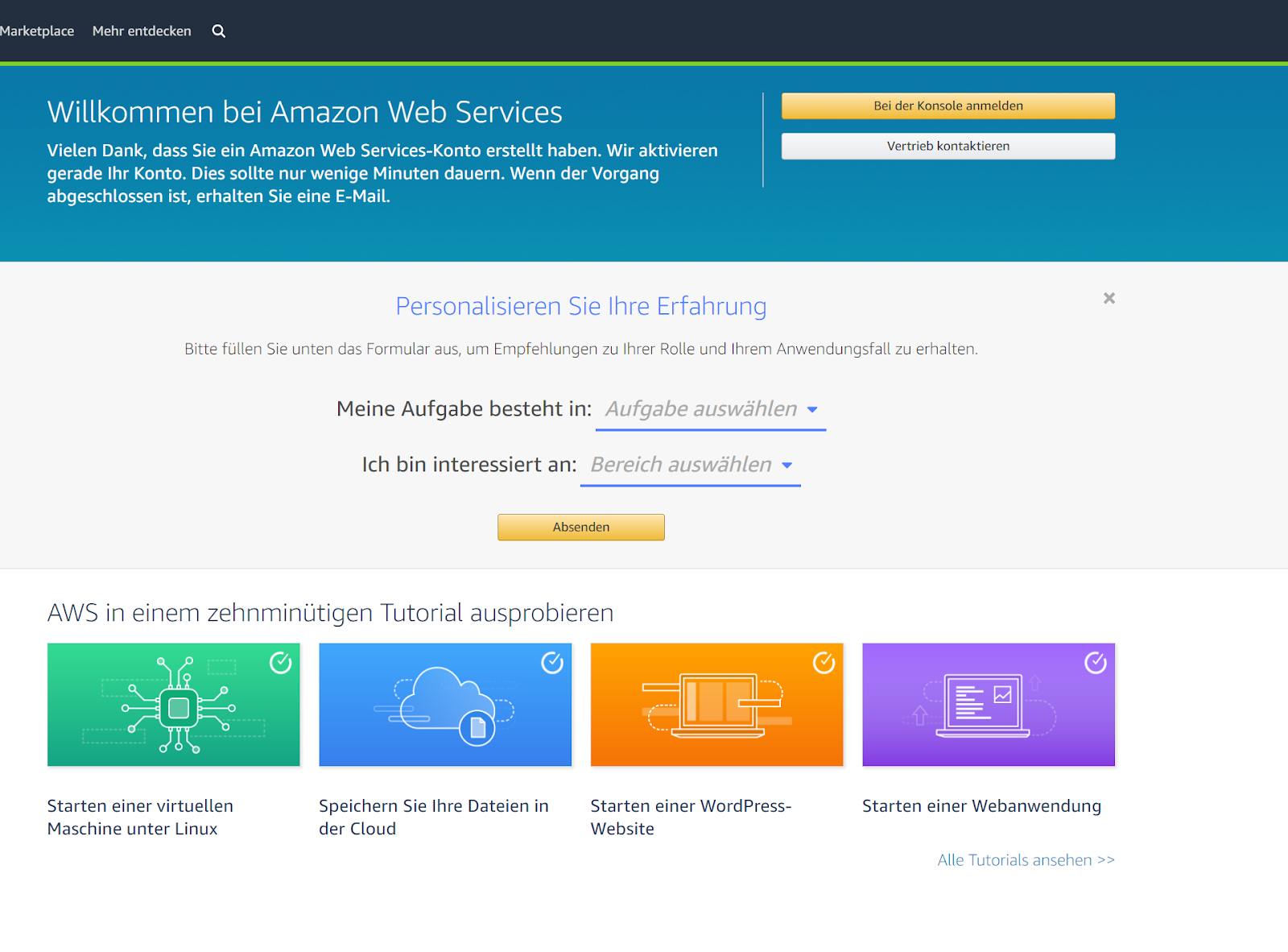
Wir wählen den kostenlosen Basic-Plan aus und landen hier.
Ab jetzt steht uns die umfangreiche und sehr ausführlich dokumentierte AWS-Welt zur Verfügung. Nahezu sofort erhalten wir eine E-Mail:
Etwas später trifft eine weitere E-Mail ein:
und gleich noch eine:
Einloggen und Region wählen
Wir müssen uns mit dem neu geschaffenen Konto einloggen. Dazu werden uns ja zahlreiche Möglichkeiten geboten. Beispielsweise indem wir auf die Schaltfläche “Bei der Konsole anmelden” Klicken.
Wir werden nach E-Mail-Adresse und Passwort gefragt und landen auf der Seite der AWS Management-Console.
Für das Big Data Labor brauchen wir einfache virtuelle Maschinen mit Linux-Betriebssystem. Amazon unterhält viele Rechenzentren rund um den Globus. Voreingestellt ist Ohio und wir wählen zuerst eine andere Region aus. Dazu klicken wir oben rechts auf “Ohio” und wählen im Menu ein uns näher liegendes Rechenzentrum.
Je nach Region sind die Preise leicht verschieden. Wir wollen ja möglichst kostenlos unterwegs sein und sind wohl eher daran interessiert, auszuwählen, wo unsere Daten gelagert werden, auch wenn es im Rahmen des Big Data Labors nur einige wenige Testdaten sind.
Für dieses Tutorial wählen wir EU (Frankfurt) aus.
Die erste virtuelle Maschine einrichten
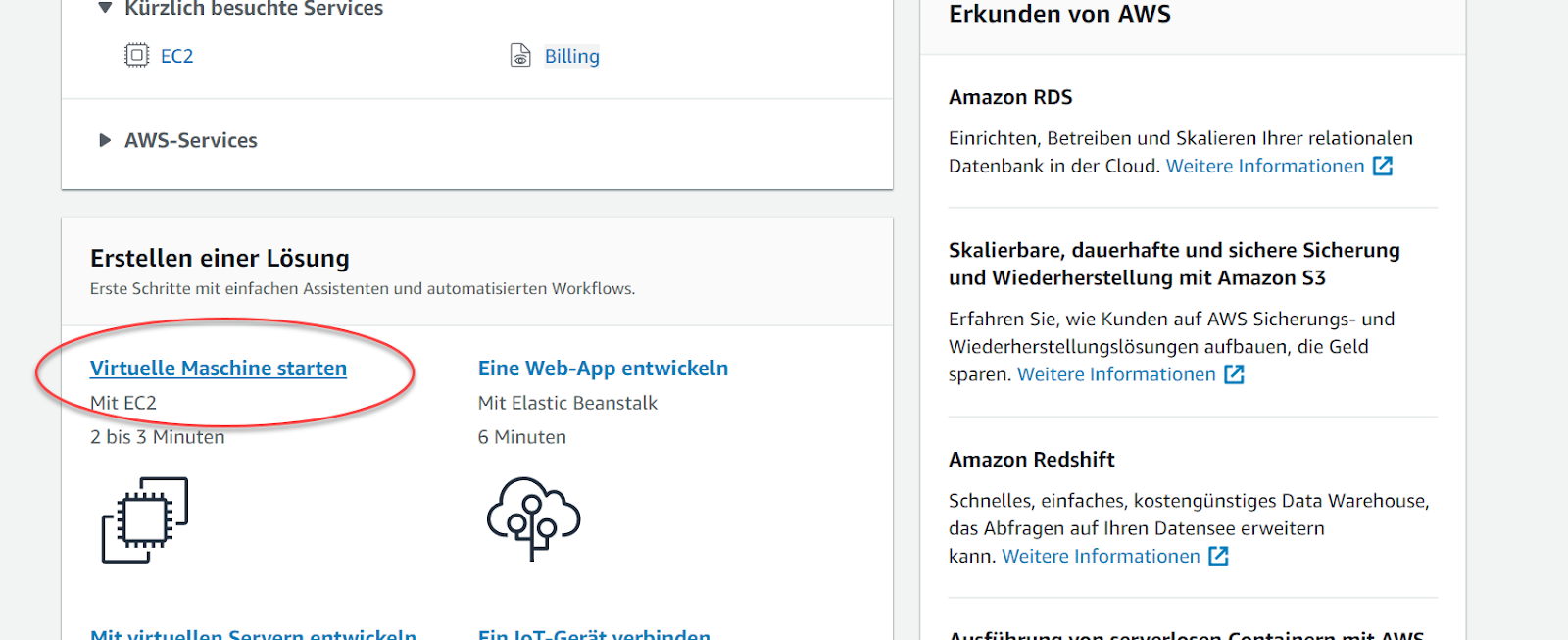
Noch auf derselben Seite, also der AWS Management Console, wählen wir jetzt die Option “Virtuelle Maschine starten” aus.
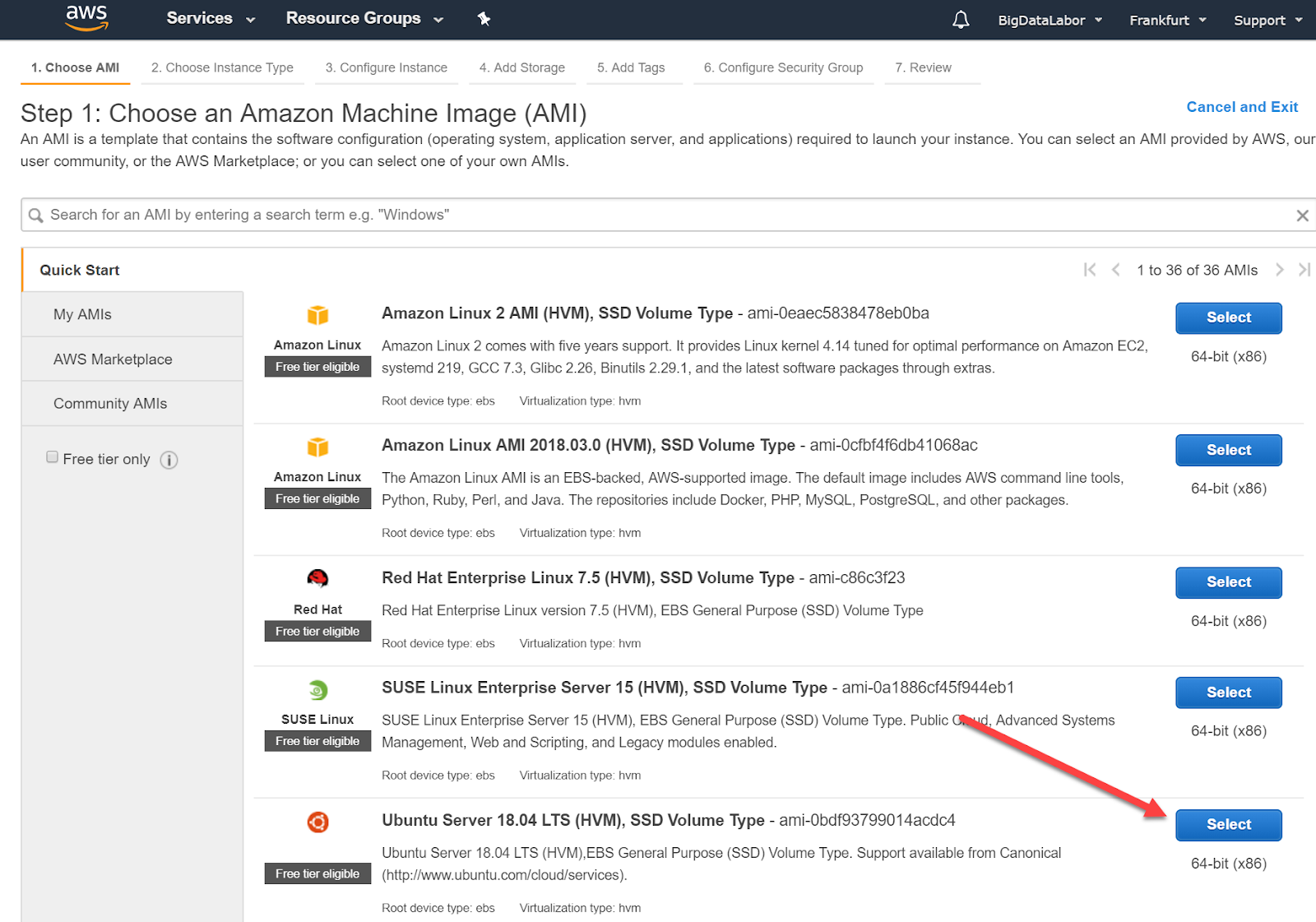
Wir werden jetzt schrittweise geführt. Im ersten Schritt wählen wir ein passendes Image. Wir scrollen etwas nach unten und finden Ubuntu Server 18.04 LTS. Diese Linux-Distribution passt zum Big-Data Labor. Wir klicken auf die dazu gehörende Schaltfläche “Select”
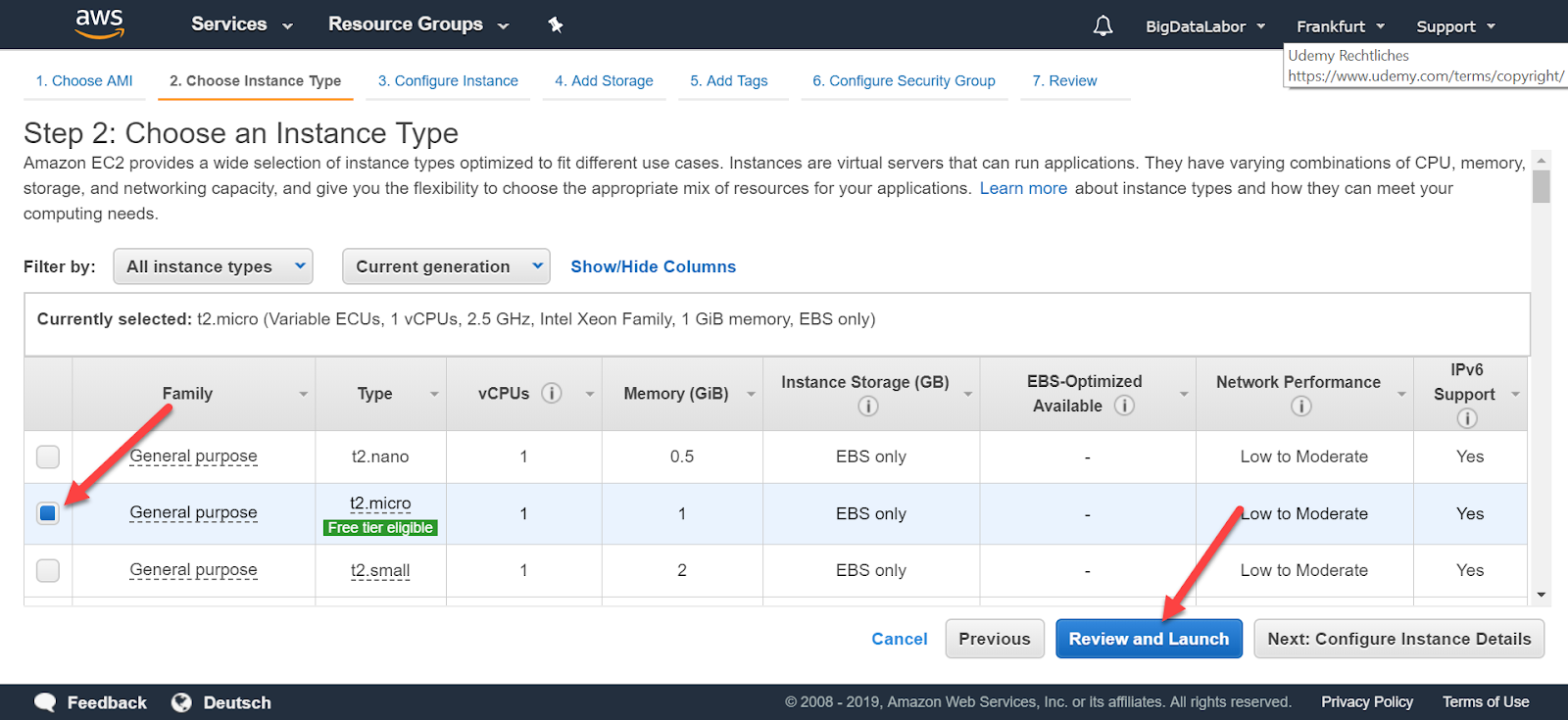
Als nächstes ist der Instanz-Typ zu wählen. Je mehr Ressourcen wir beanspruchen, desto kostspieliger wird der Gebrauch. Das kostenlose Kennenlernpaket enthält zum Zeitpunkt des Erstellens dieses Tutorials auch den Typ t2.micro. Dieser kommt mit 1 GB Memory, entspricht also gerade einem Raspberry Pi. Das Big Data Labor wurde für Raspberry Pi entworfen und wir können also auch mit t2.micro arbeiten.
Wer mehr Geschwindigkeit haben möchte, wählt einen kostenpflichtigen, besser ausgestatteten Instanz-Typ.
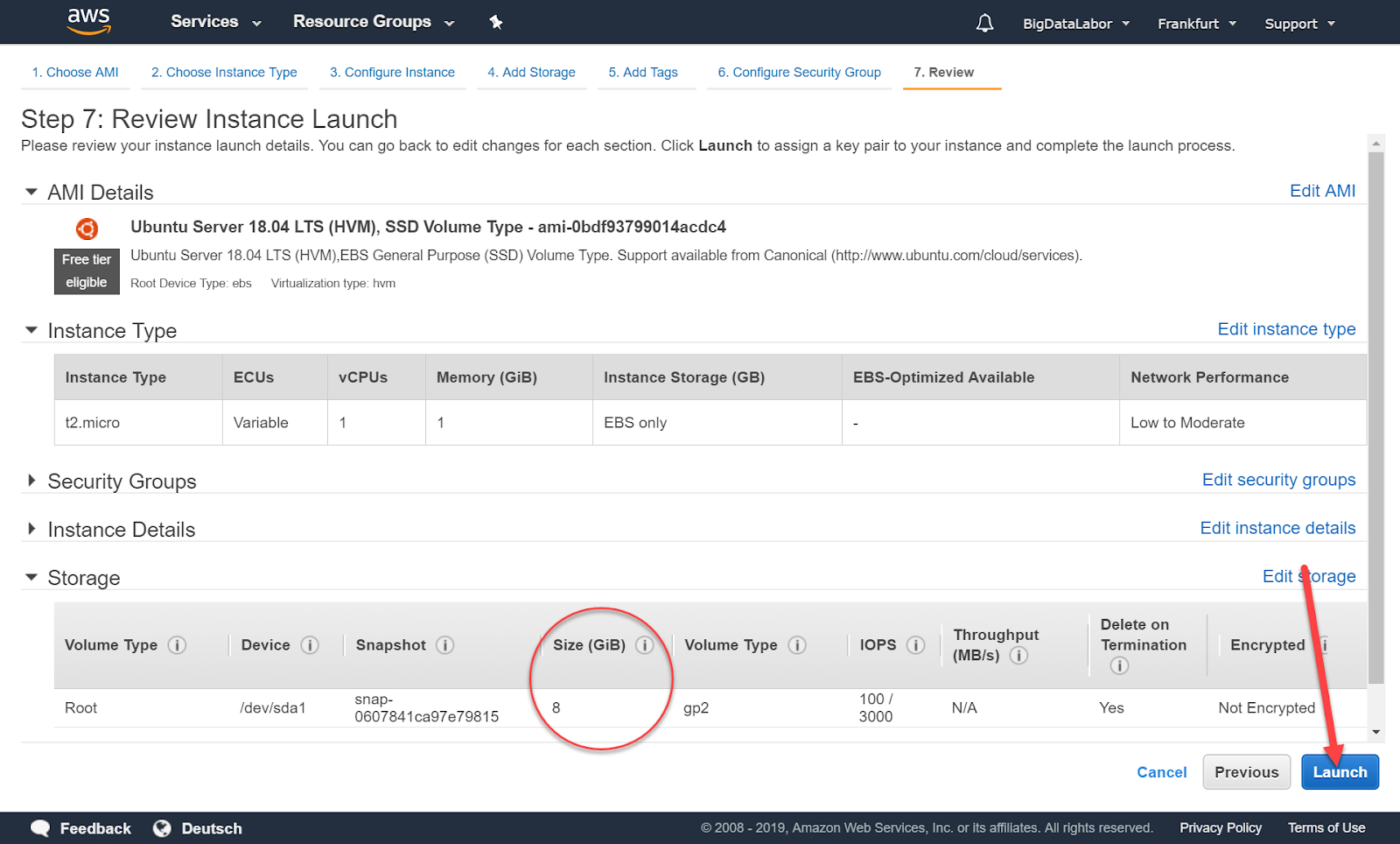
Nach der Wahl des Instanztyp klicken wir “Review and Launch”. Wir erhalten eine Übersichtsseite mit mehr Angaben. Beispielsweise sehen wir hier, dass dieser Instanz-Typ mit 8 GB SSD Storage kommt. Das reicht für das Big Data Labor – wenn wir bereit sind, hin und wieder den Platz zu bereinigen.
Wir klicken jetzt auf “Launch”.
Das Schlüsselpaar (Key Pair)
Als nächstes werden wir aufgefordert, ein Schlüsselpaar (Key Pair) auszuwählen. Dieses dient dazu, den Datenverkehr zu verschlüsseln und den Zugang zur virtuellen Maschine abzusichern. Beim ersten Gebrauch von AWS werden wir ein Schlüsselpaar erstellen. Ein Teil (der public Key) bleibt auf dem Server, den anderen Teil (den private Key) laden wir herunter und bewahren ihn sorgfältig auf.
Aus der Auswahlliste wählen wir “Create a new key pair”. Bei jeder weiteren virtuellen Maschine werden wir dieses Key Pair (Schlüsselpaar) dann verwenden.
Jetzt werden wir aufgefordert, dieses Schlüsselpaar zu benennen. Beispielsweise AWSBigDataLaborKey. Und wir klicken anschließend auf “Download Key Pair”.
Eine Datei mit dem Namen AWSBigDataLabor.pem wird jetzt heruntergeladen. Sie enthält den Schlüssel zur virtuellen Maschine.
Wir können für alle virtuellen Maschinen denselben Schlüssel verwenden. Verliert wir den Schlüssel, dann verlieren wir auch den Zugang zu den virtuellen Maschinen. Wir bewahren das Schlüsselpaar also sehr sorgfältig auf und erstellen einen Backup.
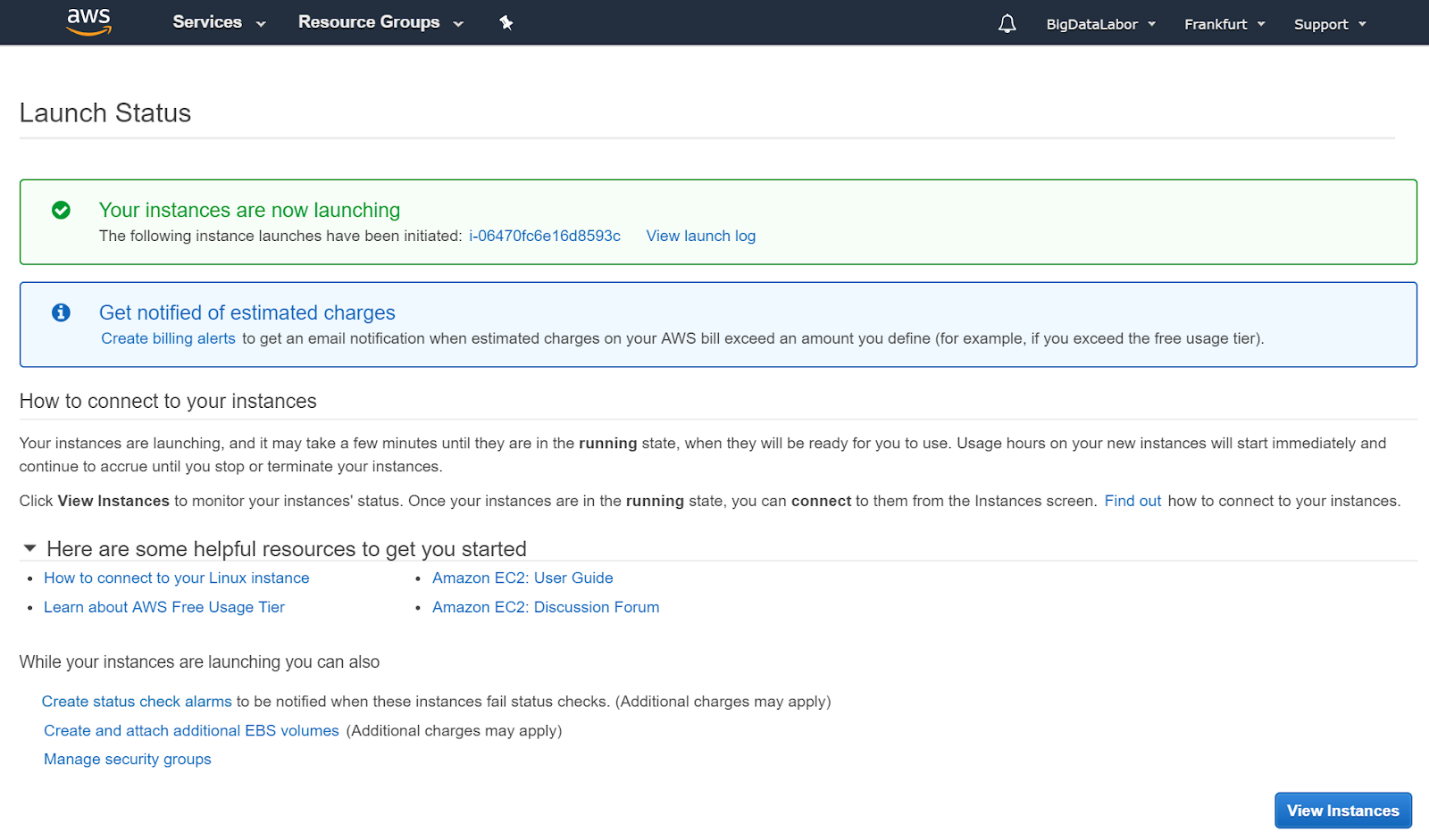
Ist das erfolgt, dann klicken wir “Launch Instances” um diese virtuelle Maschine zu starten.
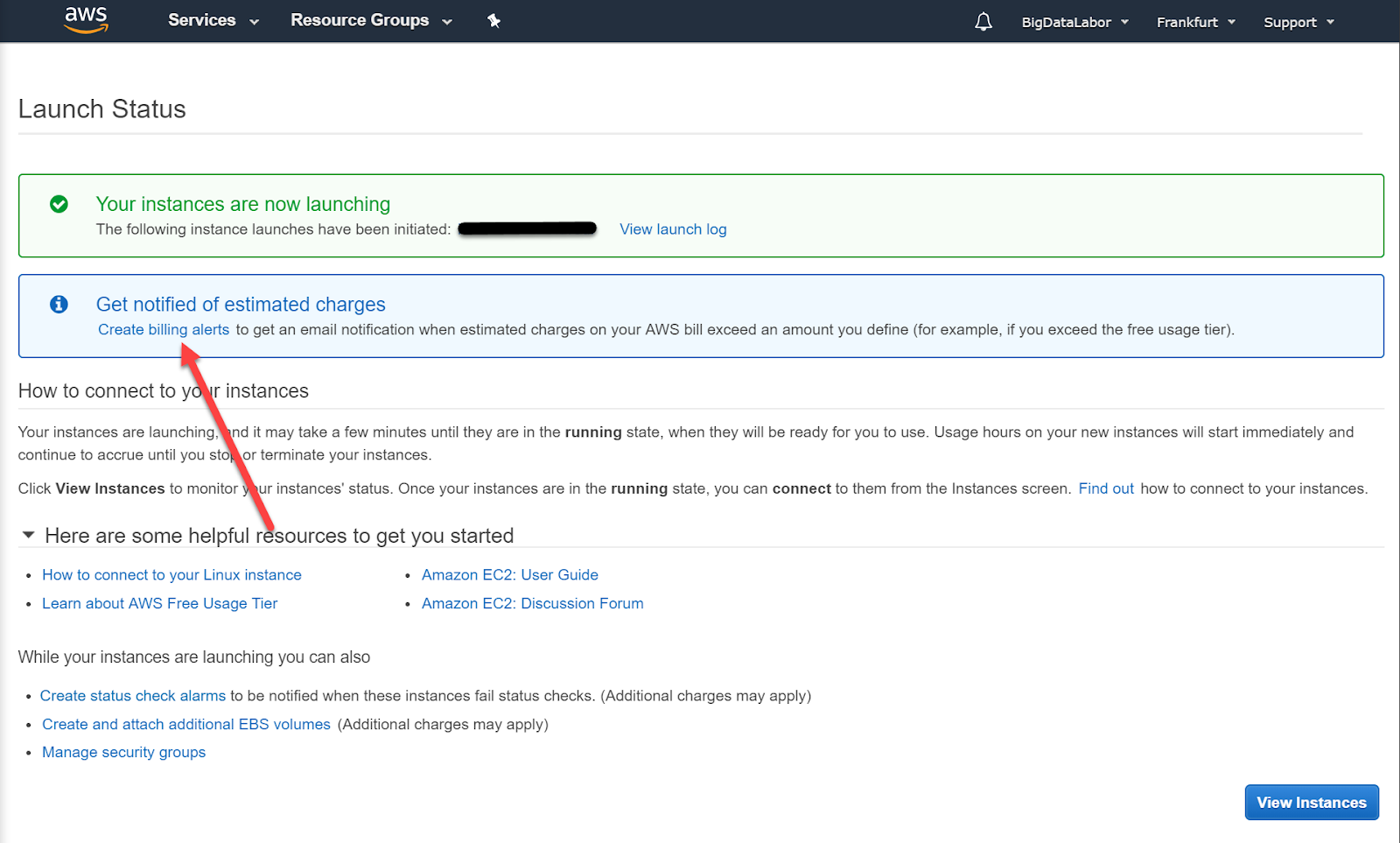
Wir erhalten diese Benachrichtigung. Es dauert einige Minuten, bis diese Instanz gestartet ist.
Kosten kontrollieren: einen Billing Alert einrichten
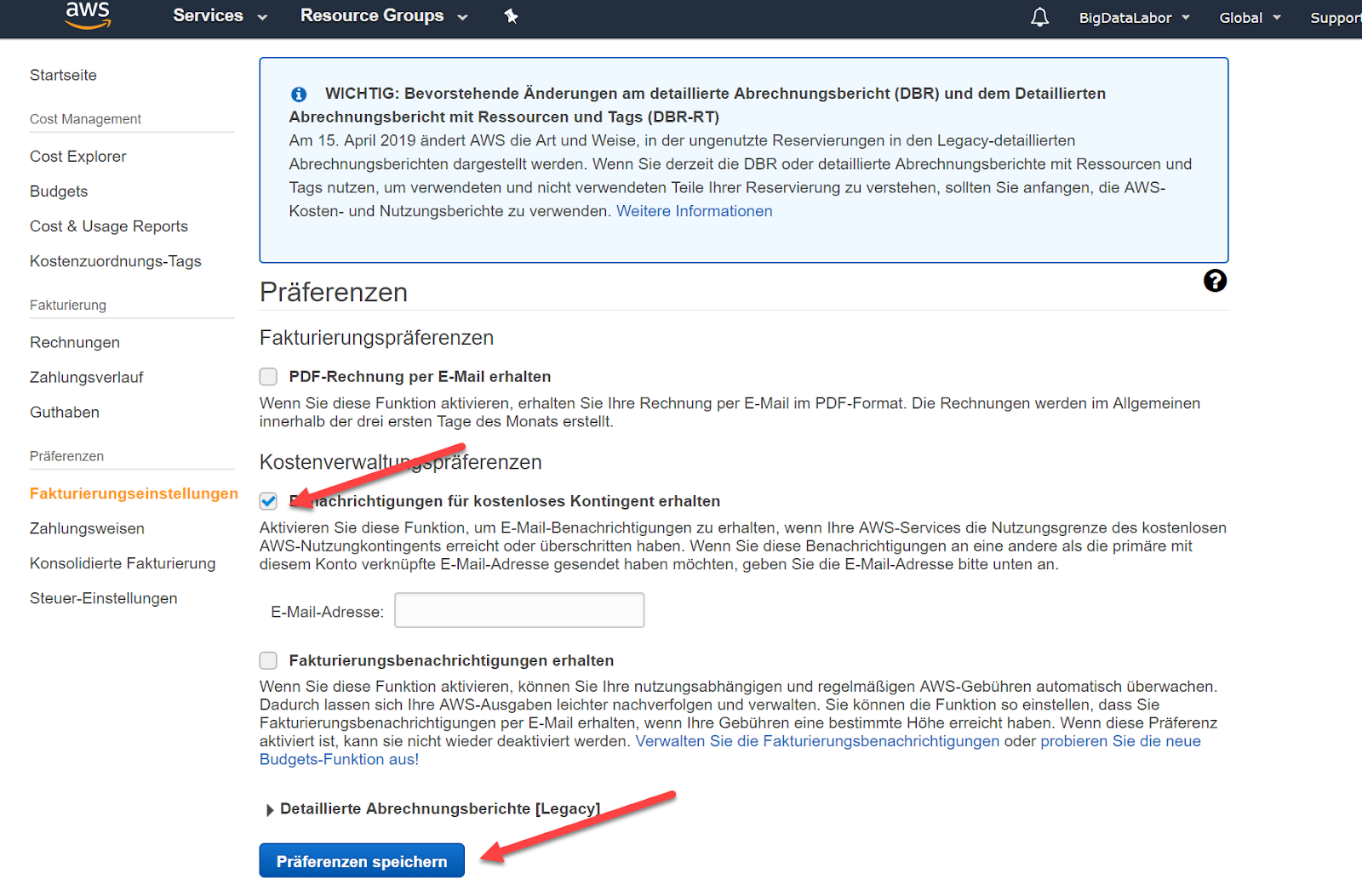
In der Zwischenzeit können wir einen Billing Alert einrichten. So erhalten wir eine E-Mail, wenn die Kosten auf AWS einen gewissen Betrag übersteigen sollte. Auch wenn wir kostenlose Instanzen gewählt haben, können wir einen solchen Alert einrichten. Wir klicken auf den entsprechenden Link. Ein neues Browser-Window wird geöffnet.
Wir wählen mindestens die Option “Benachrichtigungen für kostenloses Kontingent erhalten” an, um benachrichtigt zu werden, sobald das kostenlose Kontingent aufgebraucht ist. Dies speichern wir mit “Präferenzen speichern”.
EC2-Dashboard: Die Instanzen
Wir gehen jetzt zurück auf das Browser-Fenster “Launch Status” und klicken “View Instances”.
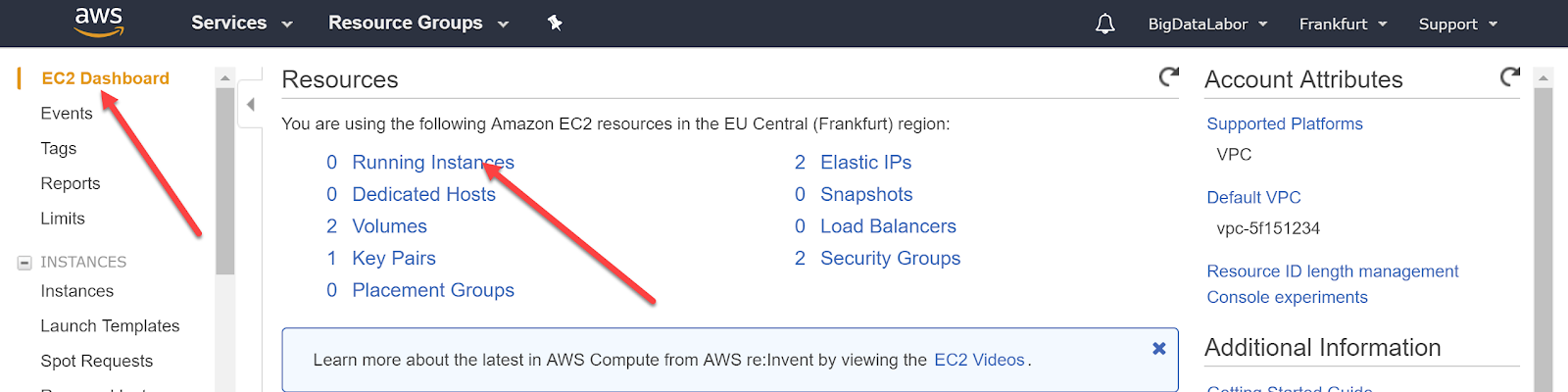
Sollten wir uns “verirrt” haben, dann können wir das EC2-Dashboard auch aus dem Menü heraus wieder öffnen.
Der Menüpunkt ist gleich oben links. Wir wählen es an und erhalten im Hauptteil der Seite eine Ressourcenübersicht. Dort Klicken wir auf “Running Instances”
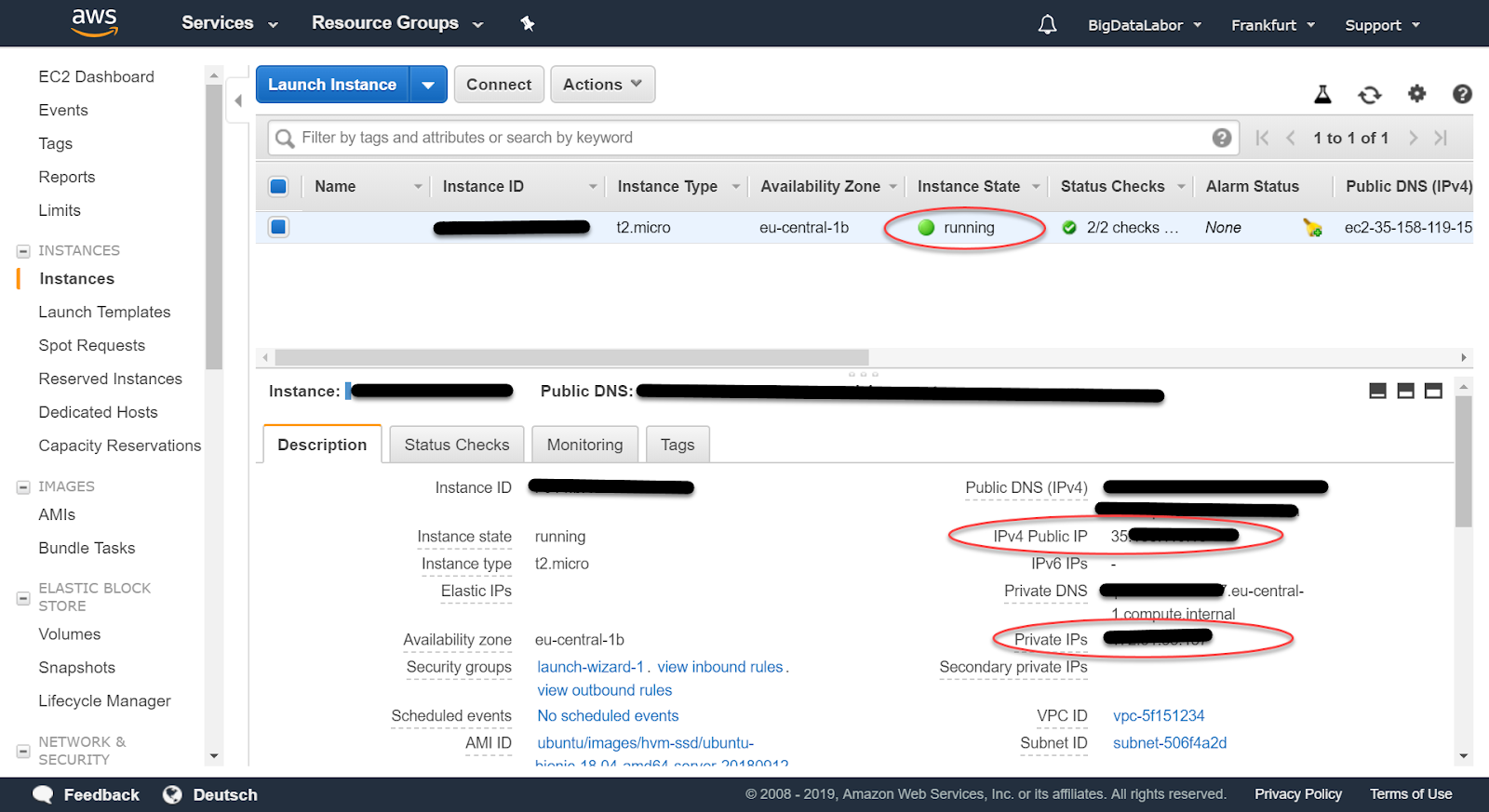
Wir erhalten eine Übersicht über alle unseren Instanzen. Mittlerweile dürfte diese erste virtuelle Maschine im Zustand “running” sein. Ihr ist auch eine öffentliche IP-Adresse zugeordnet.
ssh Verbindung aufbauen
Mit dieser öffentlichen (public) IP-Adresse und mit dem Schlüssel können wir jetzt eine ssh-Verbindung zu diesem Server aufbauen.
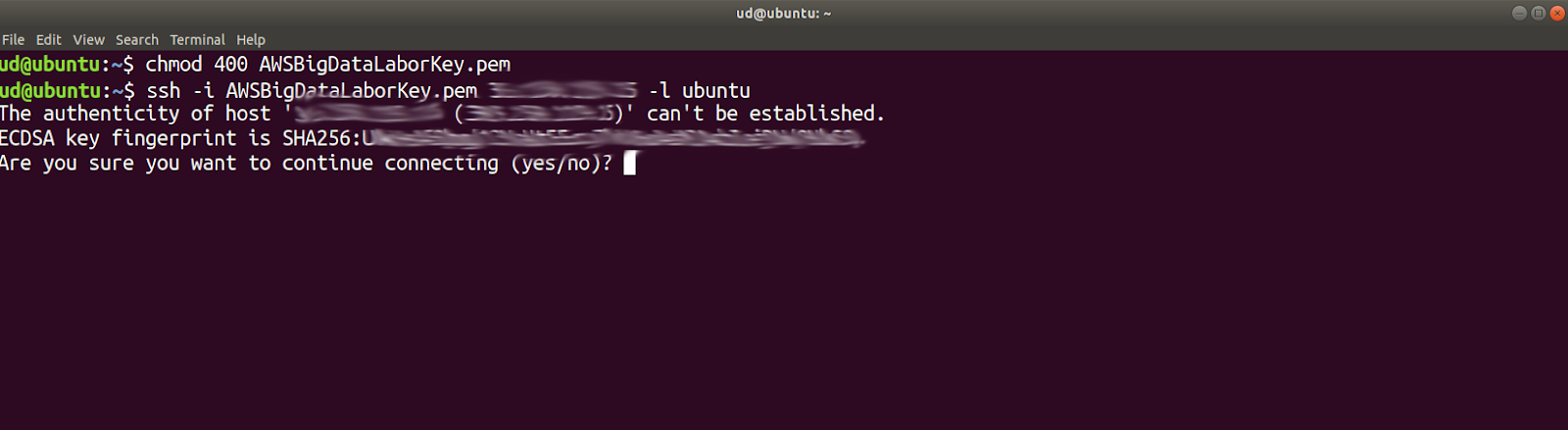
Auf unserem lokalen Rechner, öffnen wir ein Terminal (z.B. Rechtsklick auf den Ubuntu-Desktop). Mit cd verzweigen wir in das Verzeichnis, indem wir den Schlüssel AWSBigDataLaborKey.pem sicher aufbewahren. Wir haben die Datei ja während der Installation heruntergeladen. Falls wir sie noch nicht verschoben haben, werden wir sie im Download-Verzeichnis finden. Damit wir den Schlüssel verwenden können, müssen wir einmalig die Berechtigungen verändern:
chmod 400 AWSBigDataLaborKey.pem
Jetzt bauen wir eine ssh-Verbindung zu dieser Instanz auf. Dazu verwenden wir die öffentliche IP-Adresse und den folgenden Befehl
ssh -i (Pfad zum .pem-File} {öffentliche IP-Adresse} -l ubuntu
oder alternativ
ssh -i {Pfand zum .pem-File} ubuntu@{öffentliche IP-Adresse}
Wer nicht Ubuntu installiert hat, sondern eine andere Linux-Distribution vorgezogen hat, wird hier an Stelle von “ubuntu”, den Standard-Usernamen dieser Distribution eingeben.
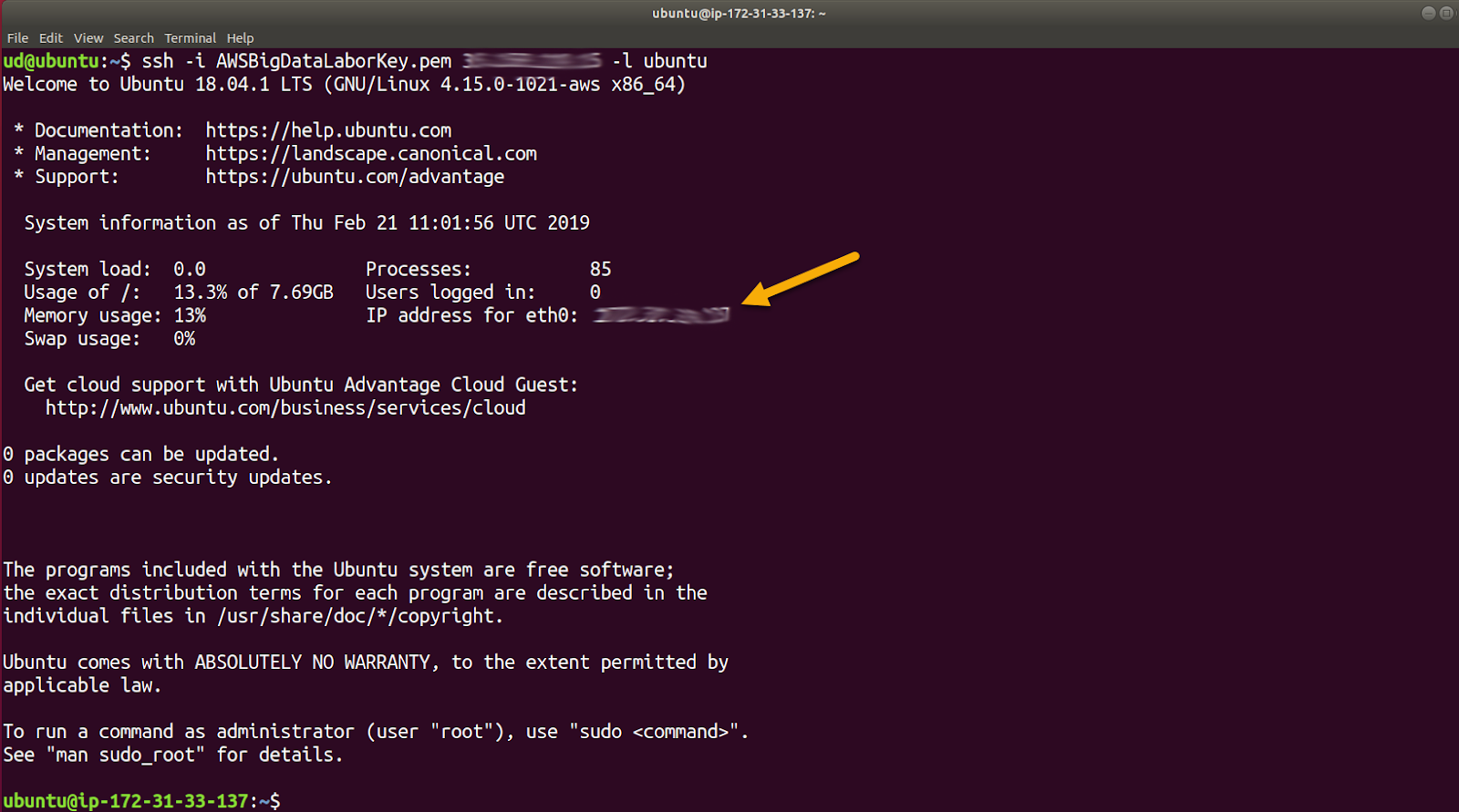
Wie gewohnt bestätigen wir die Frage nach dem Fingerprint mit yes.
Jetzt erhalten wir die Begrüßungsinformation, die auch nochmals die private IP-Adresse enthält. Wir befinden uns jetzt in einer gewohnten Ubuntu-Umgebung und können beginnen, den Cluster aufzubauen.
Instanz stoppen und neu starten
Auch wenn wir ein kostenloses Kontingent erhalten haben, sollten wir uns von Anfang an daran gewöhnen, nicht verwendete Instanzen zu stoppen. Laufzeit ist ein Kostenfaktor bei AWS.
Dazu gehen wir auf das EC2-Dashboard, wählen die Instanz aus, klicken auf “Action”, wählen den Menüpunkt “Instance State” und dann den Untermenüpunkt “Stop”.
Diese Instanz können wir später wieder starten. Wählen wir stattdessen “Terminate”, dann wird die Instanz heruntergefahren und später gelöscht.
Das Stoppen kann einige Sekunden dauern. Sobald die Aktion ausgeführt ist, wird der neue Zustand auf der Konsole angezeigt.
Mit “Start” können wir die Instanz wieder starten.
Public und Private IP Adressen
Quelle Bild: eigene Darstellung
Die Graphik veranschaulicht das Zusammenspiel der öffentlichen (public) und privaten IP-Adressen.
Rechts ist das LAN bei uns im Haus dargestellt, mit dem Laptop der wireless oder Kabelgebunden mit dem Router verbunden ist. Dieser stellt die Verbindung zum Internet her, vernetzt alle Rechner bei uns im Haus und schirmt mit der Firewall unerwünschten Besuch aus dem Internet ab.
Auch das Rechenzentrum bei AWS hat eine Firewall, um unerwünschten Traffic aus dem Internet abzuschirmen. Wir wollen aber auf unsere virtuelle Maschine zugreifen und dazu brauchen wir eine IP-Adresse. Mit der öffentlichen IP-Adresse finden wir den Weg zu unserer virtuellen Maschine. Im Bild beispielsweise mit PI-202 benannt.
Wir wollen unsere virtuellen Maschinen miteinander vernetzen. Es wäre sehr umständlich, dies mit den öffentlichen IP-Adressen zu tun, denn dazu müsste der gesamte Datenverkehr immer über das öffentliche Internet laufen.
Viel effizienter ist es, das LAN bei AWS selbst zu verwenden. Und in diesem LAN haben die virtuellen Maschinen eine private IP-Adresse.
Elastic IP Adresse zuordnen
Unternehmen wir nichts, dann erhält die Instanz mit jedem Start eine neue öffentliche und eine neue private IP-Adresse.
Und ein Einblick zum Zeitpunkt der Erstellung des Tutorials:
Eine Elastic-IP-Adresse ist pro Instanz also kostenlos.
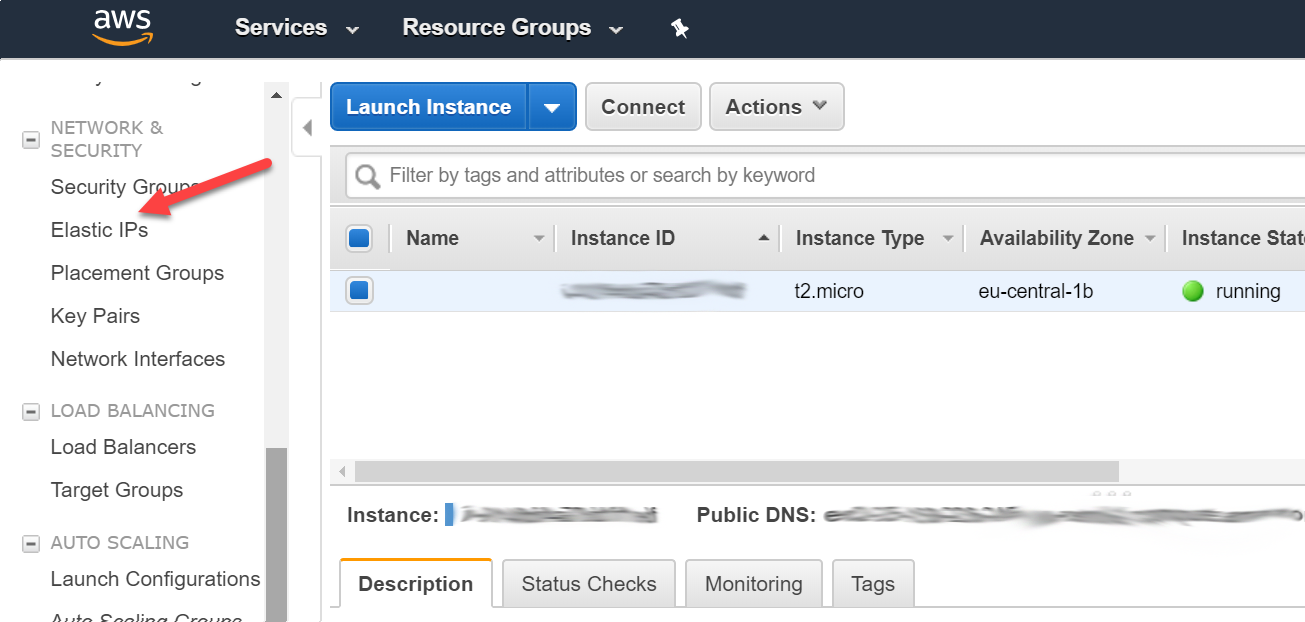
Wir erstellen also eine elastische IP-Adresse. Dazu scrollen wir links in der AWS Management Konsole etwas nach unten und klicken die Option “Elastic IPs”
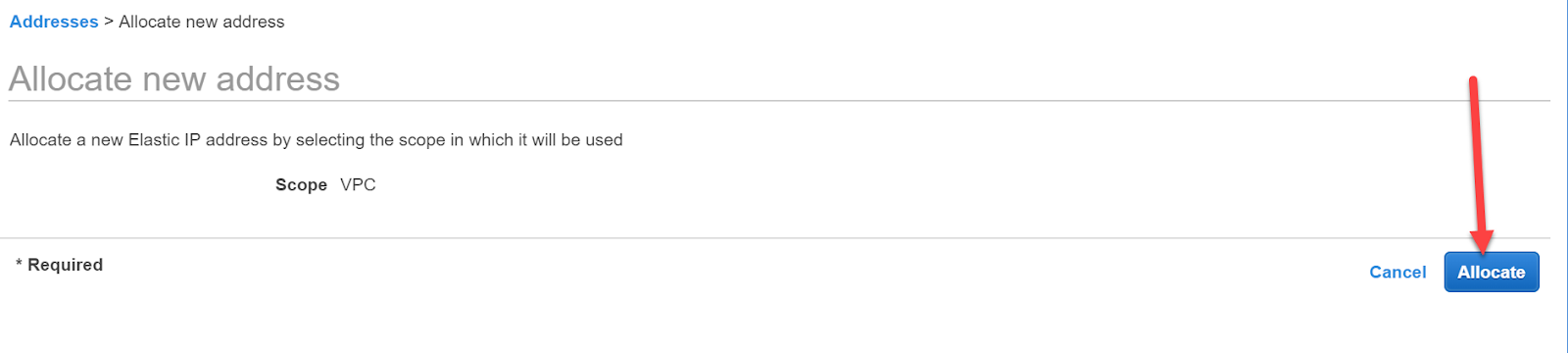
Wir erhalten die Information, dass wir für diese Region (also Frankfurt) keine Elastic IP-Adresse hätten. Wir klicken auf “Allocate new address”, um eine zu erstellen.
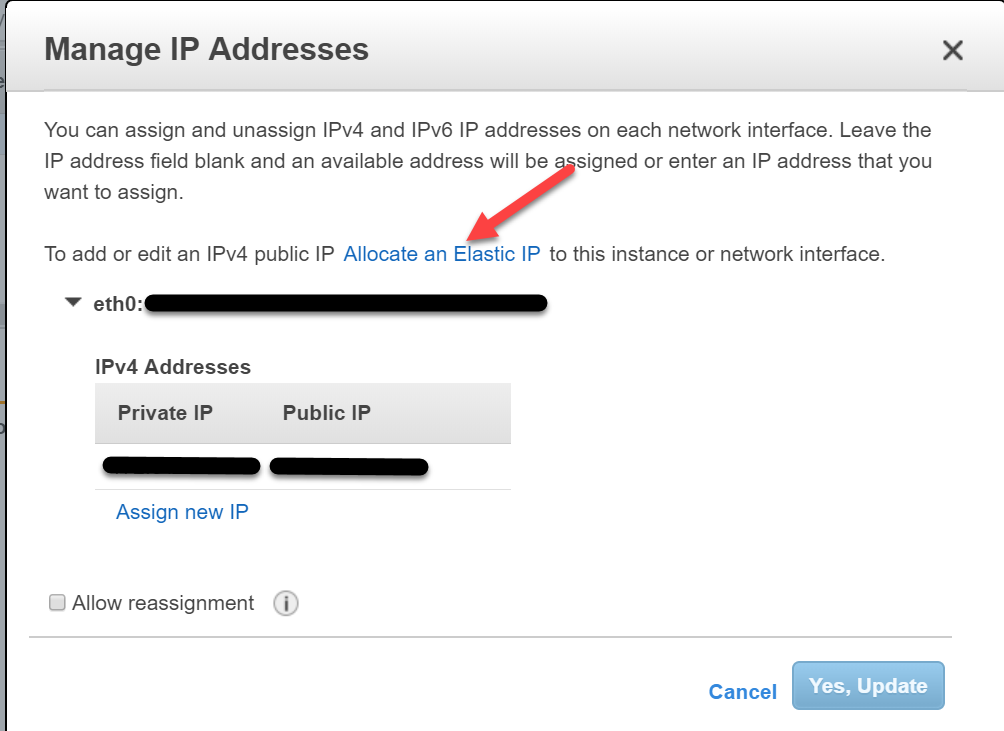
Oder alternativ: Im EC2-Dashboard, klicken wir auf unsere Instanz und im Actions-Menu auf Manage IP Addresses
Wir erhalten eine Übersicht über die IP-Adressen der Instanz und die Möglichkeit, eine elastische IP-Adresse zuzuordnen. Wir klicken auf diese Option:
Auf der folgenden Seite, klicken wir auf Allocate. Wir erhalten die neue IP-Adresse mitgeteilt und merken uns diese, bevor wir auf “Close” klicken.
Wir werden zurück auf die Übersicht der Elastic IP-Adressen geführt und sehen, dort diese IP-Adresse als erste in einer Liste.
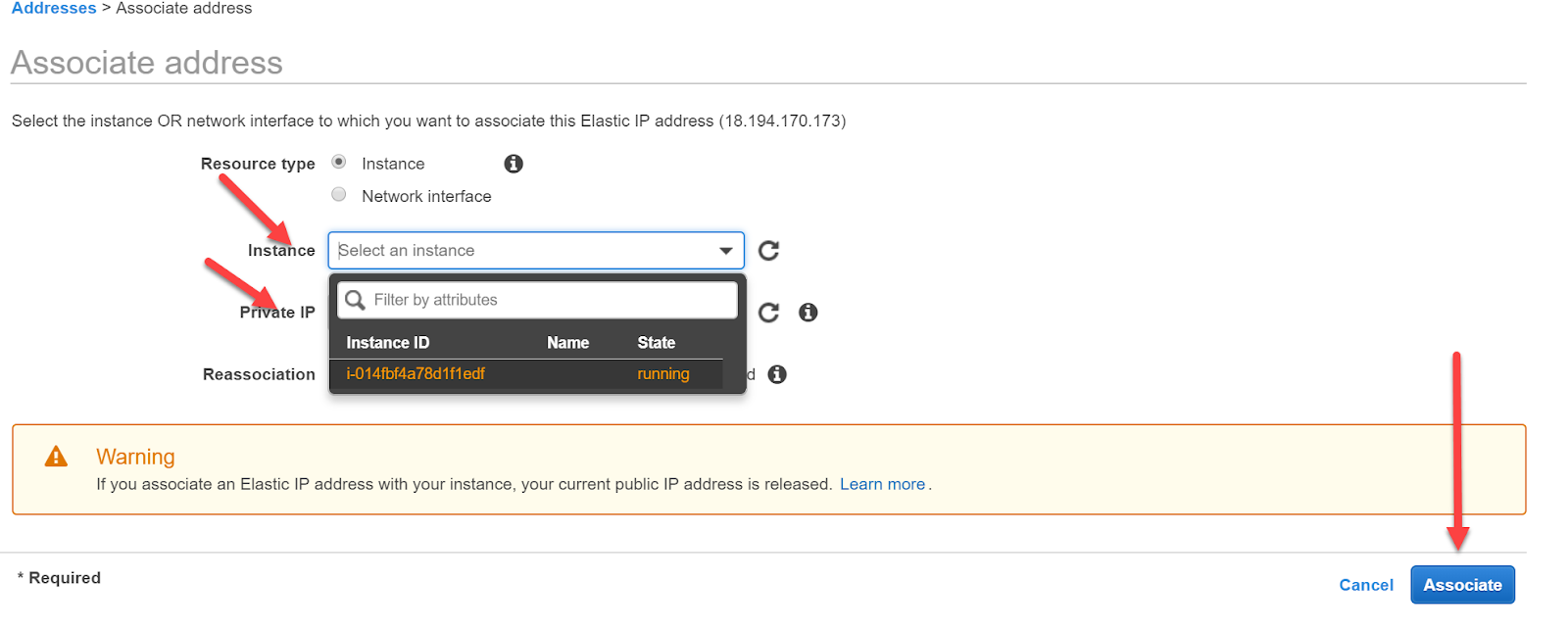
Wir selektieren die Adresse und klicken auf Action. Mit dem Menu-Punkt “Associate address” können wir diese IP-Adresse jetzt einer Instanz zuordnen.
Auf der folgenden Seite können wir die Instanz wählen und auch die private IP-Adresse. Wir treffen eine Auswahl für beides und klicken auf “Associate”.
Dann erhalten wir eine Bestätigung, die wir mit “Close” schließen.
Wir verzweigen zurück aufs EC2 Dashboard und sehen, dass die neue Elastic IP Adresse unserer Instanz zugeordnet wurde.
Jetzt können wir die Probe aufs Exempel machen und mit ssh einloggen und dabei die Elastic IP Adresse angeben.
Weitere Instanzen allozieren
Jetzt, wo wir die erste Instanz erstellt haben, können wir diese vervielfachen, um anschließend unseren Cluster aufzubauen.
Wir klicken auf Actions und wählen “Launch More Like This”.
Jetzt werden wir aufgefordert, uns um die Security zu kümmern und eine neue Security Group einzurichten.
Damit können wir steuern, welche Ports auf unseren Instanzen offen sind, und von welchen IP-Adressen aus darauf zugegriffen werden kann. Eine Regel ist bereits vorhanden: wir können mit ssh von allen IP-Adressen aus auf diese Instanz zugreifen. Wir haben ja den ssh-Zugang mit dem Schlüsselpaar gesichert. Falls wir sicher sind, immer mit derselben IP-Adresse ins Internet zu gehen, dann können wir hier eine zusätzliche Regel definieren und diese IP-Adresse angeben.
Anschließend klicken wir auf Launch Wir werden aufgefordert, ein Schlüsselpaar zu wählen und sollen bestätigen, dass wir das zugehörende .pem-File besitzen. Jetzt klicken wir auf Launch Instances
Diese Nachricht kennen wir schon und wir bestätigen sie mit “View Instances”
Wir sehen jetzt, dass eine weitere Instanz angelegt wird und bereiten gleich die passende Elastic IP Address dafür vor und ordnen sie auch gleich der neuen Instanz zu.
So erstellen wir vorerst insgesamt fünf Instanzen.
Hostnamen für das Big Data Labor vorbereiten
Im nächsten Schritt definieren wir die Hostnamen und “stellen” die einzelnen Server einander vor. Dazu erstellen wir die folgende Liste
Public IP Address
Private IP Address
Hostname
pi-201
pi-202
pi-203
pi-204
pi-205
In der Tabelle tragen wir die Paare von öffentlichen (public) und privaten IP-Adressen ein. Diese können wir in der EC2-Konsole ablesen und der Reihe nach in die Tabelle schreiben.
Wir loggen jetzt der Reihe nach in die virtuellen Maschinen auf AWS ein. Dazu verwenden wir die öffentliche IP-Adresse gemäss der ausgefüllten Liste. Auf jeder virtuellen Maschine verändern wir die beiden Files
/etc/hostname
/etc/hosts
Dazu verwenden wir unseren Lieblingseditor, beispielsweise vi oder nano.
sudo vi /etc/hostname
Auf der ersten Zeile steht der Hostname, den AWS vergeben hat. Wir löschen die Zeile und fügen den Hostnamen ein, den wir in der Liste oben ablesen. Also z.B.
pi-201
Und wir speichern das File.
Das Big-Data Labor wird sich auf diese Hostnamen beziehen. Wer andere Hostnamen haben möchte, fügt noch eine weitere Spalte in die Liste ein und erhält so eine Übersetzungsliste für das Big Data Labor.
Die erste Spalte in der Liste muss die privaten IP-Adressen enthalten. Diese werden anders lauten, also im Beispiel dargestellt.
Damit die Änderungen aktiv werden, starten wir die Instanz neu
sudo shutdown -r now
Der Prompt sollte jetzt sein:
ubuntu@pi-201:
Falls wir auf dem gewohnten Weg in pi-201 einloggen.
Schlussbemerkungen
Das freie AWS-Kontingent beinhaltet eine gewisse Stundenzahl pro Monat für T2.Micro-Instanzen. Wenn jetzt zwei Instanzen jeweils gleichzeitig eine Stunde lang laufen, dann zählt AWS dafür zwei Stunden. Wir können die Instanzen auch wie folgt herunterfahren:
sudo shutdown -h now
Zum Neustarten verwenden wir die EC2-Konsole, wie oben aufgeführt.
Damit haben wir dieselben Voraussetzungen für das Big Data Labor geschaffen, wie auch im Tutorial für VirtualBox und für Raspberry Pi beschrieben.
Im ersten Tutorial zum Big Data Labor werden wir Apache Hadoop kennen lernen.
Bildnachweis
Alle Bilder sind Screenshots von AWS / Amazon mit Ausnahme des Bildes im Kapitel Public und Private IP Adressen. Bei diesem handelt sich um eine eigene Darstellung.
In diesem Artikel vergleichen wir ein Cluster aus Virtuellen Maschinen mit einem Cluster aus Containern. Dabei legen wir einen besonderen Schwerpunkt auf die Eigenschaften, die wir für eine Trainingsumgebung für Big-Data-Technologien erwarten.
Dieser Artikel ist ein Auszug aus dem eBook Virtuelle Maschinen vernetzen, einem step-by-step Tutorial zum Aufbau eines VirtualBox-Clusters.
Wir starten mit einer Labor-Umgebung, die auf einem Laptop Platz findet und doch verteiltes Rechnen mit Big-Data-Technologien erlaubt. In diesem Artikel stellen wir die Unterschiede zwischen einem Big Data Cluster basierend auf virtuellen Maschinen und einem Big Data Cluster basierend auf Containern vor. In den nächsten Artikeln werden wir einen Big Data Cluster mit virtuellen Maschinen aufbauen.
Ein Blick auf die grundsätzliche Architektur von Big Data fähigen Systemen.
Grundlegende Darstellung eines Big Data Clusters mit drei Nodes
Die Stärke moderner Big Data Systemen liegt im kostengünstigen Scale-Out: Handelsübliche Server (oft als Commodity Hardware bezeichnet), werden zu einem Cluster (Verbund) zusammengeschlossen. Sie bilden dann ein Netzwerk von Servern. In diesem Fall spricht man von einem Node und meint einen Server innerhalb eines Clusters.
Große Big-Data-Installationen, wie etwa bei den Internet-Riesen anzutreffen, umfassen Tausende von Nodes. Auf unserem Bild illustrieren wir das Prinzip mit drei Nodes.
Die Nodes sind miteinander vernetzt – im Bild als Linien dargestellt. Jeder Node hat eine eigene IP Adresse.
Auf jedem Node ist ein Betriebssystem (OS) installiert. Normalerweise dasselbe OS auf allen Nodes, üblicherweise ein Linux-System. Damit einher geht ein Filesystem, in der Linux-Welt treffen wir oft Ext4 an.
Mit zu einem Big-Data-Cluster gehören jetzt die passenden Big-Data-Tools und Apps, die auf den Nodes installiert werden. Auf diese Tools und Apps werden wir in späteren Artikeln eingehen.
Ziel ist es ja, sehr große Mengen an Daten zu verwalten. Üblicherweise handelt es sich dabei um sehr große Files, im Terabyte-Bereich und größer. Auf unserem Bild ist das File F1 schematisch dargestellt.
In einer Big-Data-Installation wird dieses Riesenfile auf mehrere Nodes aufgeteilt. Auf einem Node liegt also nur ein Teil des Files. Aus Sicht des Ext4-Systems auf einem einzelnen Node ist jeder Teil von F1 ein in sich geschlossenes Ext4-File. Nur durch die Big-Data-Tools werden die verschiedenen File-Teile als ein logisches Ganzes erkannt und behandelt.
Das Big Data Labor soll diese Umgebung auf einem Laptop miniaturisieren:
Ein Miniatur-Cluster auf einem Laptop als Big Data Labor
Aktuell gibt es ja zwei Möglichkeiten, um einen Server auf einem Laptop zu “miniaturisieren”
Virtuelle Maschinen
Container
Im Folgenden widmen wir uns den Vor- und Nachteilen der beiden Möglichkeiten gerade in Bezug auf unser Laptop Big Data Labor. Dazu holen wir etwas aus und betrachten die grundlegenden Gemeinsamkeiten und Unterschiede der beiden Möglichkeiten.
Virtuelle Maschinen
Dank Virtualisierungstechnologien können wir auf dem Laptop zusätzlich zu allen Apps eine Umgebung installieren, die die Hardware und das Betriebssystem des Laptops nutzen, jedoch einsetzbar sind, wie ein eigenständiger Rechner mit einem separaten Betriebssystem.
Hier eine schematische Darstellung, die sich auf das Big-Data-Labor bezieht:
Ein Cluster basierend auf virtuellen Maschinen. Die drei mit F1 bezeichneten Blöcke sind drei Teile eines verteilten Big-Data-Files.
Der Laptop dient als Gastgeber, also also Host. Und so ist die Rede vom Host-Betriebssystem.
Darauf installieren wir die Virtualisierungssoftware – genauer den Hypervisor. Innerhalb dieses Hypervisors installieren wir anschließend virtuelle Maschinen mit einem eigenen Betriebssystem. Man spricht vom “Gast”, englisch “Guest”. So kann man die beiden Betriebssyste unterscheiden: Host und Gast. Ein Host kann mehrere Gäste haben. Vorausgesetzt, unser unser Laptop verfügt über genügend Rechenkapazität.
Auf der schematischen Darstellung oben, sind drei virtuelle Maschinen, also “Gäste” dargestellt. Für das Big-Data-Labor werden wir für jede virtuellen Maschine eine eigene statische IP-Adresse konfigurieren.
Der Hypervisor virtualisiert auf Hardware-Ebene. Die virtuellen Maschinen sind vollständig voneinander isoliert und der Hypervisor enthält unter anderem als eine Art “Router”, weist den virtuellen Maschinen IP-Adressen zu und stellt die TCP-IP-Verbindung dazwischen her.
Jede virtuelle Maschine hat also ein eigenes Betriebssystem, ein eigenes Filesystem und eine eigene Installation der Tools und Apps, die wir kennenlernen wollen.
Wie jeder Computer, kann auch eine virtuelle Maschine gestartet und gestoppt werden. Es wird dann jeweils das betreffende Gast-Betriebssystem gestartet resp. gestoppt.
Images von virtuellen Maschinen können auch von einem Laptop auf einen anderen kopiert oder verschoben werden, mehrheitlich unabhängig vom Host-Betriebssystem der Laptops.
Wir werden mit Laptops arbeiten, um das Big-Data-Labor aufzubauen. Virtualisierung ist nicht auf Laptops beschränkt, sondern findet sehr viel Verbreitung bei Cloud-Providern. Dort werden virtuelle Server aufgebaut, verwaltet, vermietet. P
Einige bekannte Hersteller von Technologien für virtuelle Maschinen:
Wir stellen hier die Eigenschaften in Bezug auf Docker dar. Andere Container Provider funktionieren ähnlich.
Hier eine schematische Darstellung, die sich auf das Big-Data-Labor bezieht:
Ein Cluster basierend auf Containern.
Gleich wie virtuelle Maschinen kann auch diese Variante auf verschiedenen Host Betriebssystemen auf Laptops und auf Servern installiert werden.
Docker (oder eine andere Container Technologie) übernimmt die Rolle des Hypervisors. Docker ist anders konzipiert. Anstatt wie bei der Virtualisierung für jeden Container das ganze Betriebssystem neu zu installieren, teilen sich die Container den Betriebssystem Kernel und oft auch die Binaries. Die Virtualisierung erfolgt also auf Betriebssystem-Ebene, wobei gemeinsame (shared) Komponenten read-only sind.
Das hat ist sehr platzsparend und ressourcensparend und hat auch zur Folge, dass ein Container sehr viel schneller gestartet werden kann, als eine virtuelle Maschine. Zudem können auf demselben Laptop mehr Container gleichzeitig laufen können, als gleichzeitige virtuelle Maschinen möglich wären.
Doch wo bleibt jetzt unser Big-Data-File? Hier eine schematische Darstellung in Bezug auf unser Big-Data-Labor:
Ein Cluster basierend auf Containern. Die drei mit F1 bezeichneten Blöcke sind drei Teile eines verteilten Big-Data-Files.
Eine weitere Eigenschaft der Container Technologie ist die, dass in einem Container wohl Daten im Filesystem gespeichert werden können, diese aber verloren gehen, wenn der Container gestoppt wird. Container sind dazu gedacht, bei Bedarf sehr schnell gestartet zu werden, ihre Aufgabe auszuführen, die Ergebnisse beispielsweise in eine Datenbank zu schreiben und wieder gestoppt zu werden, wenn sie nicht mehr benötigt werden. Files die in Container geschrieben werden, sind also temporärer Natur und nicht für Persistierung (also die dauerhafte Aufbewahrung) gedacht.
Wird jetzt ein Container gestoppt dann sind diese Daten verloren. Hier die schematische Darstellung:
Ein Cluster basierend auf Containern. Die drei mit F1 bezeichneten Blöcke sind drei Teile eines verteilten Big-Data-Files. Ein Block fehlt, sobald der zugehörende Container gestoppt und neu gestartet wird.
Es kann wohl ein neuer Container gestartet werden und ihm kann auch die vorherige statische IP-Adresse zugeordnet werden. Doch die Daten bleiben verloren. Hier eine schematische Darstellung in Bezug auf das Big-Data-Labor:
in Cluster basierend auf Containern. Die drei mit F1 bezeichneten Blöcke sind drei Teile eines verteilten Big-Data-Files. Ein Block fehlt, sobald der zugehörende Container gestoppt und neu gestartet wird.
Dass die Daten eines Nodes beim Shutdown verloren gehen, ist überhaupt nicht im Sinn eines Big-Data-Filesystems.
Es ist möglich, einen Container so zu konfigurieren, dass die Files außerhalb des Containers und zwar auf dem Filesystem des Hosts persistiert werden. Im Container mounted man ein logisches Volumen auf dem Host Filesystem.
Hier eine schematische Darstellung in Bezug auf das Big-Data-Labor:
Ein Cluster basierend auf Containern. Die drei mit F1 bezeichneten Blöcke sind drei Teile eines verteilten Big-Data-Files. Im Unterschied zu den vorherigen Darstellungen, befinden sich die Blöcke jetzt in speziell zugeordneten (mounted) Verzeichnissen auf dem Gast-System.
Für unsere Miniaturisierung bedeutet das jetzt, dass jedem Container ein eigenes Volumen auf dem Host-Filesystem zugewiesen wird.
Wird jetzt der Container gestoppt, dann gehen dessen lokale Daten verloren, die auf dem Host-Filesystem persistierten Daten bleiben jedoch vorhanden.
Wird jetzt ein Container gestoppt, dann bleiben die zugehörenden Daten vorhanden. Sie stehen dem Gesamtsystem jedoch nicht zur Verfügung.
Das Big-Data-Filesystem, beispielsweise Hadoop, verwaltet die File-Blöcke auf den einzelnen Nodes, weiss genau, auf welchem Node welche Blöcke sind. Die Nodes werden von Hadoop durch ihre IP-Adresse identifiziert. Das Big-Data-Filesystem wird auch dafür sorgen, dass die Blöcke geschickt über den Cluster verteilt sind.
Beim starten eines Containers muss dafür gesorgt werden, dass zum gemounteten Volumen ein Container mit der ursprünglichen statische IP-Adresse gestartet wird. Denn sonst wird das Big-Data-Filesystem das Riesenfile nicht mehr korrekt aus den Blöcken zusammensetzen können. Hier eine schematische Darstellung in Bezug auf das Big-Data-Labor.
Wird der Container korrekt neu gestartet, dann stehen die Daten dem Gesamtsystem wieder zur Verfügung.
Was bei Containers schlank ist und als Vorteil erscheint, wird für deren Einsatz im Big-Data-Labor jetzt plötzlich schwerfällig und fehleranfällig.
Wird ein Container heruntergefahren, was wir ja tun, spätestens wenn wir den Laptop ausschalten, dann verschwindet er, verliert seine Identität IP-Adresse und seine Daten. Als Big-Data-Filesystem jedoch verwaltet Hadoop die Files in Blöcken und geht davon aus, dass ein Node eine statische IP-Adresse hat. Startet man jetzt den Laptop wieder, dann muss man auch Docker wieder starten und die einzelnen Container hochfahren. Diese müssen dann so konfiguriert werden, dass sie eine statische IP-Adresse erhalten und genau dasjenige Volumen auf dem Host-OS gemounted wird, das zu dieser statischen IP-Adresse gehört.
Das ist alles machbar, jedoch ziemlich erklärungsbedürftig und für einen Kennenlernbetrieb unnötig fehleranfällig. Aus dem Grund, beginnen wir die Labor-Umgebung mit Hilfe von virtuellen Maschinen zu bauen. Wir werden uns schneller aufs Wesentliche konzentrieren können und in einem späteren Schritt die Docker-Variante vorstellen.
Wer sich mit Big Data Technologien auseinandersetzt, taucht ein in eine faszinierende und sich schnell verändernde Welt.
Es gibt natürlich verschiedenste Möglichkeiten, den Überblick über die Entwicklungen zu erhalten und zu behalten. Will man nicht nur einen High-Level theoretischen Einblick haben, sondern Hands-On-Erfahrungen sammeln, dann braucht man eine Arbeitsumgebung, um die verschiedenen Tools kennen zu lernen.
Mit Big Data Technologien kann man immense Datenmengen verarbeiten, viel größer, als der persönlichen Laptop fassen kann. Die Daten werden auf viele Rechner verteilt und die Berechnungen erfolgen parallel auf mehreren Rechnern. Um die Tools kennen zu lernen, beschafft man sich am besten eine verteilte Umgebung. Es ist auch möglich, die Tools auf nur einem Rechner zu installieren, doch dann verbaut man sich die Chance, wichtige Aspekte der Big Data Berechnungen kennen zu lernen.
Es gibt verschiedene Möglichkeiten, wie man eine Labor-Umgebung schaffen kann:
Man hat das Glück und kann die Software auf mehreren Servern installieren.
Man mietet eine Kennenlern-Umgebung bei einem Cloud-Anbieter.
Für diese beiden Optionen benötigt man einen gewissen finanziellen Rahmen, den möglicherweise zu Beginn nicht aufbringen möchte.
Es gibt noch einfachere Varianten, um ein Big-Data-Labor aufzubauen
Man baut eine verteilte Umgebung mit virtuellen Maschinen auf
Nur limitiert interessant: man verwendet Docker Images
Man baut eine verteilte Umgebung mit Raspberry Pi auf
Diese drei Varianten sind deutlich kostengünstiger als die ersten beiden und sind ideal, um erste Experimente zu machen und die Tools kennen zu lernen. Sie bieten auch eine ideale Möglichkeit, den Produktionsbetrieb vorzubereiten. Die Einschränkungen: man hat natürlich keinen Platz für enorme Datenmengen und die Ausführungsgeschwindigkeit ist eher gemütlich.
Diese Artikel-Serie zeigt, wie eine verteilte Umgebung mit virtuellen Maschinen gebaut werden kann. Insbesondere wird auch erläutert, welches die Grenzen sind, die eine reine Docker-Umgebung in Bezug auf eine Labor-Umgebung mit sich bringt.
Die Serie wurde auch als E-Book und Print-On-Demand Buch veröffentlicht (mittlerweile in der zweiten, aktualisierten Auflage) und mit Anleitungen ergänzt, wie ein Raspberry-Pi-Cluster für den Aufbau einer Labor-Umgebung für Big Data Technologien aufgesetzt wird.
Wir verwenden Cookies auf unserer Webseite, um Ihnen ein optimales Surferlebnis zu bieten. Klicken Sie auf "Akzeptieren", um ALLEN unseren Cookies zuzustimmen oder besuchen Sie die Cookie-Einstellungen.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Advertisement".
cookielawinfo-checkbox-analytics
1 year
This cookies is set by GDPR Cookie Consent WordPress Plugin. The cookie is used to remember the user consent for the cookies under the category "Analytics".
cookielawinfo-checkbox-necessary
1 year
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-performance
1 year
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
ct_pointer_data
session
CleanTalk–Used to prevent spam on our comments and forms and acts as a complete anti-spam solution and firewall for this site.
ct_timezone
session
CleanTalk–Used to prevent spam on our comments and forms and acts as a complete anti-spam solution and firewall for this site.
PHPSESSID
session
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
viewed_cookie_policy
1 year
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Notwendige Cookies sind für das ordnungsgemäße Funktionieren der Website unbedingt erforderlich. Diese Cookies gewährleisten grundlegende Funktionalitäten und Sicherheitsmerkmale der Website, anonymisiert.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Advertisement".
cookielawinfo-checkbox-analytics
1 year
This cookies is set by GDPR Cookie Consent WordPress Plugin. The cookie is used to remember the user consent for the cookies under the category "Analytics".
cookielawinfo-checkbox-necessary
1 year
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-performance
1 year
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
ct_pointer_data
session
CleanTalk–Used to prevent spam on our comments and forms and acts as a complete anti-spam solution and firewall for this site.
ct_timezone
session
CleanTalk–Used to prevent spam on our comments and forms and acts as a complete anti-spam solution and firewall for this site.
PHPSESSID
session
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
viewed_cookie_policy
1 year
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Funktionale Cookies helfen dabei, bestimmte Funktionen auszuführen, wie z. B. das Teilen des Inhalts der Website auf Social-Media-Plattformen, das Sammeln von Feedbacks und andere Funktionen von Drittanbietern.
Leistungsbezogene Cookies werden verwendet, um die wichtigsten Leistungsindizes der Website zu verstehen und zu analysieren, was dazu beiträgt, den Besuchern ein besseres Benutzererlebnis zu bieten.
Cookie
Duration
Description
_gat
1 minute
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.
YSC
session
This cookies is set by Youtube and is used to track the views of embedded videos.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.
YSC
session
This cookies is set by Youtube and is used to track the views of embedded videos.
Analytische Cookies werden verwendet, um zu verstehen, wie Besucher mit der Website interagieren. Diese Cookies helfen dabei, Informationen über Metriken wie die Anzahl der Besucher, Absprungrate, Verkehrsquelle usw. zu liefern.
Cookie
Duration
Description
__gads
1 year 24 days
This cookie is set by Google and stored under the name dounleclick.com. This cookie is used to track how many times users see a particular advert which helps in measuring the success of the campaign and calculate the revenue generated by the campaign. These cookies can only be read from the domain that it is set on so it will not track any data while browsing through another sites.
_ga
2 years
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, campaign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assign a randomly generated number to identify unique visitors.
_gid
1 day
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
This cookie is set by Google and stored under the name dounleclick.com. This cookie is used to track how many times users see a particular advert which helps in measuring the success of the campaign and calculate the revenue generated by the campaign. These cookies can only be read from the domain that it is set on so it will not track any data while browsing through another sites.
_ga
2 years
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, campaign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assign a randomly generated number to identify unique visitors.
_gid
1 day
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
Werbe-Cookies werden verwendet, um Besuchern relevante Werbung und Marketing-Kampagnen anzubieten. Diese Cookies verfolgen Besucher über Websites hinweg und sammeln Informationen, um maßgeschneiderte Werbung bereitzustellen.
Cookie
Duration
Description
IDE
1 year 24 days
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
NID
6 months
This cookie is used to a profile based on user's interest and display personalized ads to the users.
test_cookie
15 minutes
This cookie is set by doubleclick.net. The purpose of the cookie is to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
NID
6 months
This cookie is used to a profile based on user's interest and display personalized ads to the users.
test_cookie
15 minutes
This cookie is set by doubleclick.net. The purpose of the cookie is to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.