
Virtuelle Maschinen vernetzen (Tutorial)
Eine eigene Cloud auf dem Laptop – das ist praktisch, gerade wenn man Big-Data-Systeme kennen lernen will. Dazu vernetzen wir mehrere virtuelle Maschinen.
Das folgende Tutorial zeigt eine Schritt für Schritt Anleitung zum Aufsetzen und Klonen einer einzelnen virtuellen Maschine mit VirtualBox.
Danach erläutert es die Konzepte zum Vernetzen der virtuellen Maschinen.
Das Tutorial ist ein Auszug aus dem E-Book Cluster aus Virtuellen Maschinen. Dort zeige ich auch das Vorgehen mit Parallels, einer Virtualisierungssoftware für ARM-Chips, also die neuen Mac-Prozessoren. Für beide Virtualisierungen zeige ich ausführlich die notwendigen Ubuntu-Linux-Befehle, um die virtuellen Maschine auch auf Linux-Ebene zu vernetzen. Das E-Book findest du im Shop.
Doch jetzt starten wir mit VirtualBox:
Wir arbeiten mit einem Mini-Cluster aus drei virtuellen Maschinen. Die Limitierung besteht in den Ressourcen des Host-Rechners, also unseres Laptops. Je mehr virtuelle Maschinen wir aufsetzen können, umso besser können wir die Big-Data-Welt kennen lernen.
Wichtigste Eigenschaften Virtueller Maschinen
Dank Virtualisierungstechnologien können wir auf dem Laptop zusätzlich zu allen Apps eine Umgebung installieren, die die Hardware und das Betriebssystem des Laptops nutzen, sich jedoch verhalten wie ein eigenständiger Rechner mit einem separaten Betriebssystem.
Hier eine schematische Darstellung einer Laptop-Cloud mit fünf virtuellen Maschinen:

Der Laptop dient als Gastgeber, also Host. Und so ist die Rede vom Host-Betriebssystem.
Darauf installieren wir die Virtualisierungssoftware – genauer den Hypervisor. Innerhalb dieses Hypervisors installieren wir anschließend virtuelle Maschinen mit einem eigenen Betriebssystem. Man spricht vom “Gast”, englisch “Guest”. So kann man die beiden Betriebssysteme unterscheiden: Host und Gast. Ein Host kann mehrere Gäste haben. Vorausgesetzt, unser Laptop verfügt über genügend Rechenkapazität. Ein Beispiel: Der Host läuft mit Windows und der Gast läuft mit Linux.
Auf der schematischen Darstellung oben, sind drei virtuelle Maschinen, also “Gäste” dargestellt. Für den Trainings-Cluster werden wir für jede virtuellen Maschine eine eigene statische IP-Adresse konfigurieren.
Der Hypervisor virtualisiert auf Hardware-Ebene. Die virtuellen Maschinen sind vollständig voneinander isoliert und der Hypervisor enthält unter anderem als eine Art “Router”, weist den virtuellen Maschinen IP-Adressen zu und stellt die TCP-IP-Verbindung dazwischen her.
Jede virtuelle Maschine hat also ein eigenes Betriebssystem, ein eigenes Filesystem und eine eigene Installation der Tools und Apps, die wir kennenlernen wollen.
Wie jeder Computer, kann auch eine virtuelle Maschine gestartet und gestoppt werden. Es wird dann jeweils das betreffende Gast-Betriebssystem gestartet resp. gestoppt.
Images von virtuellen Maschinen können auch von einem Laptop auf einen anderen kopiert oder verschoben werden, mehrheitlich unabhängig vom Host-Betriebssystem der Laptops.
Wir werden mit Laptops arbeiten, um den Trainings-Cluster aufzubauen. Virtualisierung ist nicht auf Laptops beschränkt, sondern findet sehr viel Verbreitung bei Cloud-Providern. Dort werden virtuelle Server aufgebaut, verwaltet, vermietet.
Eine einzelne VirtualBox einrichten und klonen
Wer mit virtuellen Maschinen arbeiten will, kann unter verschiedenen Anbietern auswählen. Gerade im Ausbildungsbereich ist VirtualBox sehr beliebt, weil viele fürs Kennenlernen notwendige Funktionalitäten in der kostenlosen Version erhältlich sind. Wer in einem Produktionssystem virtualisieren möchte, wird nicht um eine Evaluation der verschiedenen Anbieter herumkommen. Für unser Big Data Training ist die Virtualisierung lediglich Mittel zum Zweck, so dass wir das Vorgehen mit VirtualBox zeigen.
Notwendige Vorkenntnisse
Für dieses Kapitel des Big Data Labors braucht man Administratorrechte auf dem eigenen Laptop (oder PC). Das Tutorial führt Schritt für Schritt durch den Installationsprozess, setzt jedoch voraus, dass der Leser mit Software-Installationen vertraut ist.
Grundlegende Kenntnisse mit Linux auf Ebene Kommandozeile werden für das Big Data Labor ebenfalls vorausgesetzt. Die Kommandos werden gezeigt und kurz erklärt.
Laptop-Ressourcen als Voraussetzung zum vernetzen virtueller Maschinen
Um mit dem Big-Data-Labor arbeiten können, brauchen wir einen Laptop (oder PC) mit genügend freien Kapazitäten. Hier eine Empfehlung:
- min 16 GB RAM
- min 100 GB freier Speicherplatz auf der Harddisk
- 64-bit Prozessor
- Internetverbindung.
Starker Prozessor um mehrere virtuelle Maschinen zuz vernetzen
Der Prozessor des Laptops muss Virtualisierung ermöglichen. Gerade in kostengünstigeren Laptops können Prozessoren verbaut sein, die Virtualisierung nicht unterstützen. Diese Seiten können weiter helfen, je nach Hersteller des Prozessors: Intel-Prozessoren oder AMD-Prozessoren.
Die neuen Mac mit M1 und M2 Prozessoren basieren auf der ARM-Prozessor-Architektur. Die neueste Version von VirtualBox unterstützt auch diese Architekturen.
Im Zweifelsfall geht Probieren über Studieren.
Voraussetzung für die Virtualisierung im BIOS
Auch wenn der Prozessor Virtualisierung ermöglicht, dann ist sie nicht unbedingt aktiviert.

Ob die Virtualisierung auf einem Windows-Laptop möglich ist, lässt sich einfach herausfinden: Wir öffnen den Task-Manager (Strg-Alt-Del) und verzweigen dort auf die Registerkarte “Leistung”. Hier können wir ablesen, ob Virtualisierung möglich ist.
Wir können es auch einfach drauf ankommen lassen, und die erste virtuelle Maschine erstellen. Zu einem gewissen Zeitpunkt während des Vorgangs, wird eine entsprechende Fehlermeldung angezeigt. Diese macht darauf aufmerksam, dass im BIOS die Virtualisierung aktiviert werden soll.

Wie man das BIOS aktiviert, hängt vom Hersteller des Laptops ab. Das Bild rechts zeigt als Beispiel die entsprechenden Einstellungen auf einem HP-Laptop.
Wenn wir dies mit unserem Laptop zum ersten Mal machen, dann wird nur eine Internetrecherche weiterhelfen. Wir suchen Beispielsweise nach Hersteller, Produktbezeichnung des Laptop, BIOS. In der Regel wird es darauf hinauslaufen, dass der Laptop neu gebootet werden muss und dass während des Bootvorgangs, noch bevor das Betriebssystem geladen wird, eine bestimmte, vom Hersteller definierte Tastenkombination gedrückt werden muss.
Wir sehen anschließend die BIOS Einstellungen. Diese Verändern wir nur sehr gezielt und mit größter Vorsicht. Normalerweise navigiert man in diesen Einstellungen mit den Pfeil- und Tab-Tasten. Wir suchen eine Einstellung, die beispielsweise den Begriff “Virtualisation Technology” enthält und wir sorgen dafür, dass diese eingeschaltet ist. Die Einstellungen müssen gespeichert werden und der Laptop muss neu gebootet werden.
Gast-Betriebssystem für die virtuelle Maschine herunterladen

Als vorbereitenden Schritt laden wir ein Image des Gast-Betriebssystem herunter. In diesem Tutorial verwenden wir Ubuntu Server. Eine kurze Google Suche lässt uns die Download-Seite finden.
Wir laden die Software herunter und speichern das File vorerst auf der Festplatte des Laptops. Wir werden in einem späteren Installationsschritt die Datei verwenden.
Server Namen der vernetzten virtuellen Maschinen
Die einzelnen virtuellen Server werden Server-Namen brauchen. In diesem Tutorial nennen wir sie “pi-200”, “pi-201”, etc. Die Namensgebung kann beliebig sein, sollte jedoch der Einfachheit halber eine Nummerierung enthalten.
Virtualisierungssoftware – ohne sie läuft nichts

Als erstes laden wir die Software für VirtualBox auf den Laptop herunter.
Auf dieser Seite erscheint immer sehr prominent die Download-Möglichkeit für die Software. Zum Zeitpunkt der Erstellung des Tutorials war gerade die Version 6.0 aktuell. Die Folgeversionen verhalten sich analog.
Wir klicken auf die grüne Schaltfläche – oder auf das Icon auf künftigen Seiten, das dieser Schaltfläche entspricht.

Auf der nächsten Seite wird die Software für verschiedene Host-Betriebssysteme angeboten. Hier wählen wir das Betriebssystem aus, das auf unserem Laptop installiert ist.
Anschließend wird die Virtualisierungssoftware heruntergeladen. Wir speichern sie auf dem Laptop und installieren sie mit den Standardeinstellungen.
VirtualBox – eine erste virtuelle Maschine

Wir starten die VirtualBox-Software und verschaffen uns einen Überblick über die Menu Optionen.
Als nächstes konfigurieren wir eine virtuelle Maschine. Wir klicken dazu auf “Neu”. Dazu können wir die entsprechende Menüoption oder auch die große Schaltfläche auf der Übersichtsseite verwenden.
Wir werden jetzt durch den Installationsprozess geführt.

Als erstes braucht die virtuelle Maschine einen eigenen Namen. Dazu verwenden wir die im Kapitel “Vorbereitung Server Namen” bestimmten Namen. Für dieses Tutorial fangen wir an mit pi-200.
Als Betriebssystem wählen wir Linux, weil die Big-Data-Software unter Linux läuft.
Wir können anschliessend die gewünschte Linux-Version auswählen. Für dieses Tutorial nehmen wir Ubuntu 64-bit. Wir können auch eine andere Version nehmen. 64-bit sollte es schon sein, die neueren Laptops haben ja 64-bit-Prozessoren und auch die Big-Data-Software geht von 64-bit aus.

Größe des RAM auf dem Laptop spielt dabei eine wichtige Rolle.
Auf der folgenden Seite, legen wir fest, mit wie viel RAM die virtuelle Maschinen arbeiten darf.
Dabei spielt die Größe des RAM auf dem Laptop eine wichtige Rolle. Der virtuellen Maschine wird vom Laptop nicht mehr RAM zur Verfügung gestellt, als wir hier konfigurieren.
1GB, also 1024 MB sollten es mindestens sein. Diese Größe ist für einen Produktivbetrieb viel zu gering, für die ersten Kennenlernschritte jedoch mindestens ausreichen. Wir werden mindestens 3 virtuelle Maschinen benötigen und auch darauf achten, dass für das Host-System genügend RAM übrig bleibt.
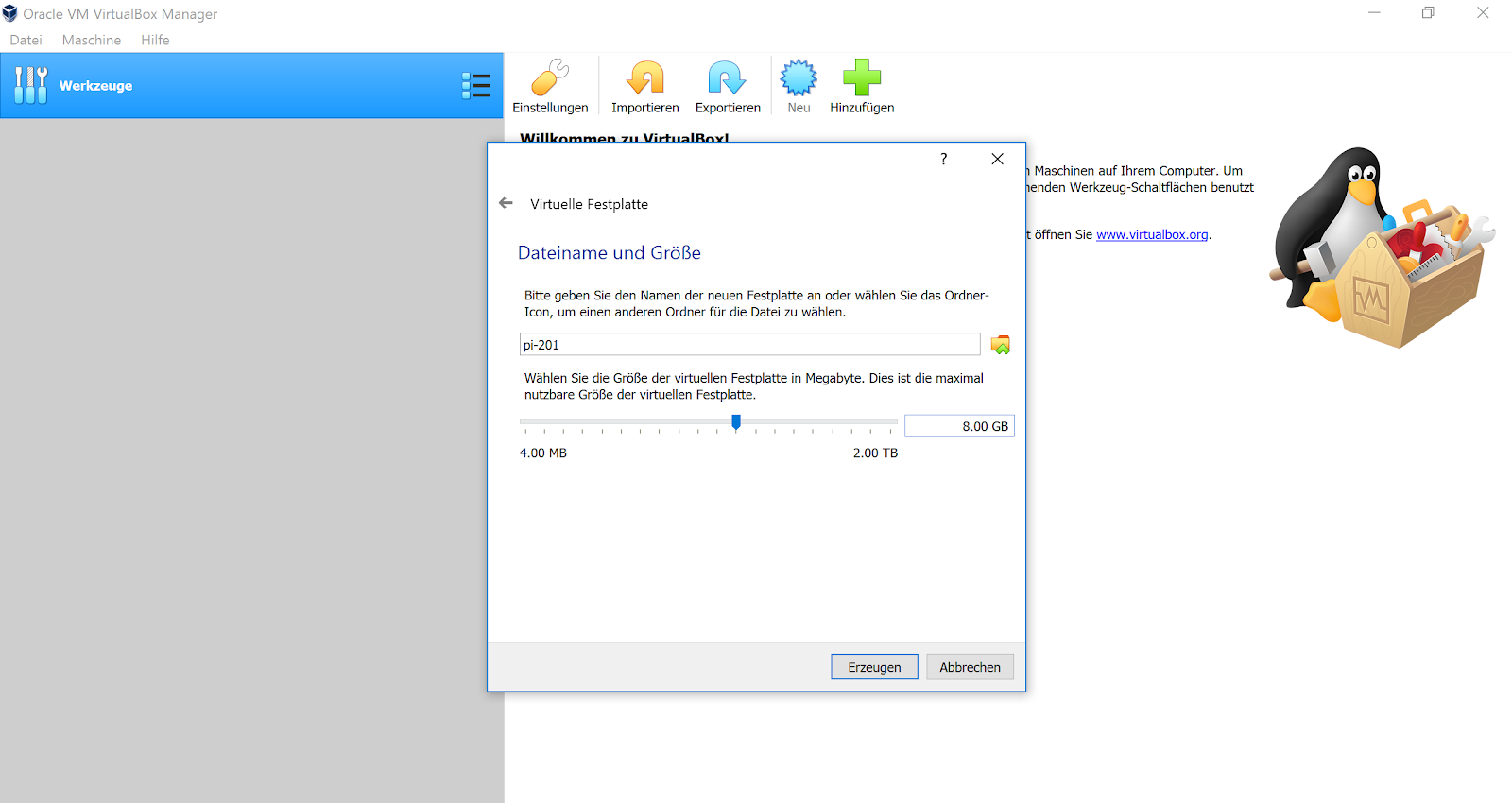

Für die weiteren Optionen wählen wir vorerst die Standardeinstellungen und schließen die Konfiguration mit “Erzeugen” ab.

Auf der nächsten Seite konfigurieren wir die Größe der Festplatte, sowie deren Name. Wir wollen ja nicht wirklich mit Big-Data arbeiten, also brauchen wir keine große Festplatte. Hier sollten wir aufpassen, dass genügend freier Festplattenplatz auf dem Laptop vorhanden ist. Wir werden ja mindestens 3 virtuelle Maschinen benötigen und alle werden auf dem Laptop diesen Platz verbrauchen.

Die neu konfigurierte virtuelle Maschine ist jetzt im linken Bereich zu sehen.
Internes Netzwerk
Bevor wir loslegen, versehen wir die virtuelle Maschine mit einer weiteren Netzwerkkarte, damit wir mehrere VMs untereinander vernetzen können.
Mit VirtualBox geht das am Einfachsten, indem wir ein internes Netzwerk bilden. Dazu definieren wir für jede virtuelle Maschine eine zweite (virtuelle) Netzwerkkarte. Diesmal öffnen wir die Registerkarte “Adapter 2”.

- Wir aktivieren den Adapter.
- Wählen aus, dass er an ein Internes Netzwerk angeschlossen sein soll.
- Und geben dem Netzwerk einen Namen – hier bigdata.
- Anschließend speichern wir mit OK.
Diesen Vorgang wiederholen wir für alle virtuellen Maschinen, die wir für das Cluster definieren und vergeben dabei immer denselben Netzwerknamen.
VirtualBox wird ein (virtuelles) Netzwerk mit diesem Namen zur Verfügung stellen.
Virtuelle Maschine starten und Gast-Betriebssystem installieren
Wir können sie starten, indem wir auf den grünen Pfeil klicken.
Die virtuelle Maschine ist erst in VirtualBox konfiguriert, doch das Gast-Betriebssystem ist noch nicht installiert. Beim ersten Starten wird diese Installation nun vorgenommen. Dies dauert eine Weile – wir nehmen uns also genug Zeit.

Als Erstes werden wir gefragt, wo sich das Image des Gast-Betriebssystem befindet.
Spätestens jetzt müssen wir das Betriebssystem herunterladen (siehe Abschnitt “Gast-Betriebssystem herunterladen“). Und wir wählen die heruntergeladene Datei aus und klicken auf “Starten”.
Jetzt wird in der virtuellen Maschine das Ubuntu-Betriebssystem installiert. Die Installationsschritte sind identisch mit einer Installation direkt auf einer Hardware, nur dass wir eine virtualisierte Umgebung verwenden. Die Navigation erfolgt mit den Pfeiltasten, den Tabulatortasten, mit Enter oder mit Esc.
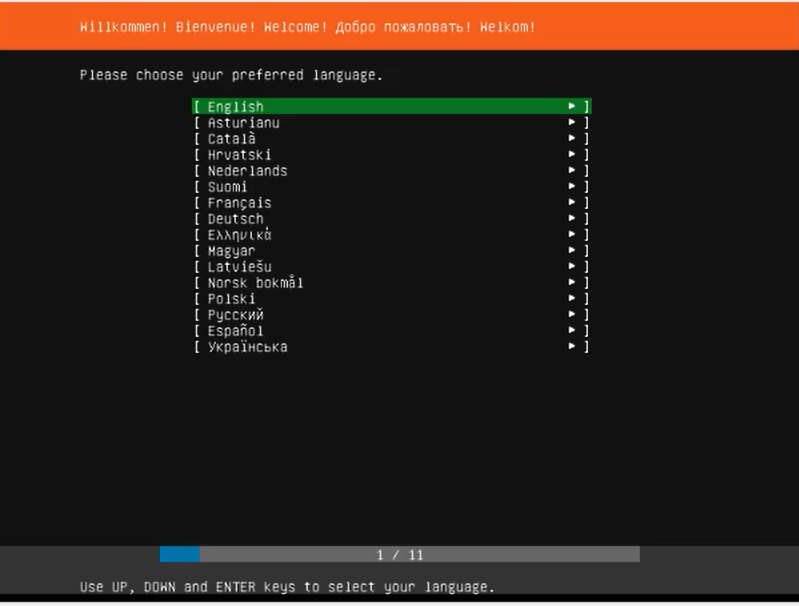
Wir werden nach der Sprache gefragt. Big-Data-Software ist oft so neu, dass es noch keine deutschen Beschreibungen gibt. Wählen wir hier “English” aus, dann wird das installierte Betriebssystem zu den Produktbeschreibungen sprachlich passen. Wählen wir eine andere Sprache aus, dann werden wir später immer wieder übersetzen müssen.

Anders verhält es sich in Bezug auf die Tastatur, also das Keyboard. Hier konfigurieren wir das Layout derjenigen Tastatur, die wir einsetzen. Die gängigsten Tastaturen stehen zur Auswahl. Verwenden wir jedoch ein anderes Tastaturlayout, z.B. German Switzerland, dann hilft die Option “Identify Keyboard” weiter. Diese führt durch einen Konfigurationsprozess, während dem man aufgefordert wird, verschiedene Tasten auf der Tastatur zu betätigen. Das Installationsprogramm ermittelt damit das passende Tastaturlayout. Wir kontrollieren noch und wenn alles in Ordnung ist, wählen wir anschließend “Done” aus.
Als nächstes konfigurieren wir die Netzwerkkarten. Für enp0s3 hat die automatische Konfiguration geklappt. Mit dieser Netzwerkkarte werden wir von der VM aus via Heimnetzwerk aus dem Internet Software herunterladen können.
Bei enp0s8 besteht Handlungsbedarf, die Konfiguration des internen Netzwerks muss manuell vorgenommen werden. Die folgende Abbildung zeigt die Abfolge der Auswahlen und Eingaben.

In den nächsten Schritten übernehmen wir die Default Einstellungen:
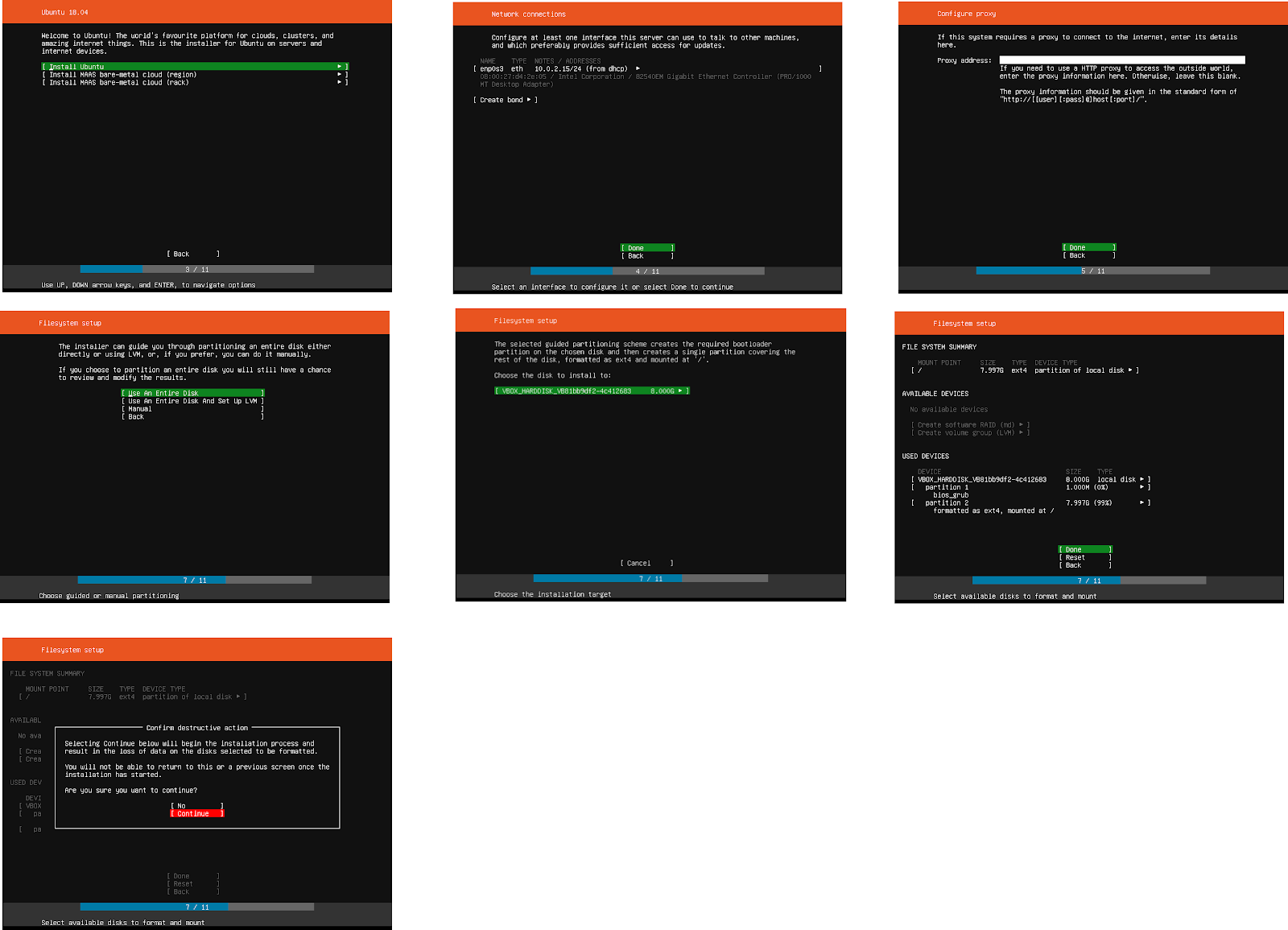
Bis wir schließlich nach Usernamen, Servernamen und Passwort gefragt werden.

Als Name und Username geben wir beispielsweise “pi” ein.
Als Server-Name empfiehlt es sich, denselben Namen zu verwenden, den wir auch für die virtuelle Maschine in VirtualBox vergeben haben – im Falle dieses Tutorials ist es pi-200.
Das Passwort muss wiederholt werden. Wir werden es bei jedem Login verwenden und behandeln es mit der gebührenden Sorgfalt.

Vorkonfigurierte Pakete verwenden wir nicht, wählen also gleich “Done” aus.
Die Installation wird anschließend ausgeführt. Das kann eine kleine Weile dauern.
Am Ende werden wir aufgefordert, das Installationsmedium zu entfernen. Diese Meldung ist im Falle der Installation in eine virtuelle Maschine nicht weiter zu beachten und wir beantworten sie mit “Enter”.

Jetzt wird der Server gebootet und der Login-Prompt erscheint.
Es kann vorkommen, dass nach dem ersten Anzeigen des Login-Prompts mit etwas Verspätung noch weitere Meldungen angezeigt werden. Wird die Enter-Taste gedrückt, dann erscheint der Login-Prompt wieder.
Username ist pi (wie während der Installation vergeben) und auch das Passwort haben wir während der Installation vergeben.
Auf dem Prompt werden wir im Folgenden Kommandos zur Administration des Servers eingeben.
Tipps:
- Ist die Anzeige zu klein, dann hilft die Menu Option der Virtual Box weiter.
- Es empfiehlt sich, die Ubuntu Pakete gleich zu updaten. Folgende beiden Befehle tun dies:
sudo apt-get update sudo apt-get upgrade
Mit sudo können alle Befehle mit Root-Rechten ausgeführt werden. Beim ersten Mal wird man nach dem Passwort gefragt. Gemeint ist das Passwort für den aktuellen User, das wir während der Installation wählten und auch zum Einloggen verwenden.
Alle weiteren Prompts sind mit Y zu beantworten.
Wir fahren den virtuellen Server herunter mit:
sudo shutdown -h now
Klonen einer virtuellen Maschine
Wir stellen sicher dass die virtuelle Maschine heruntergefahren ist und können sie jetzt klonen. Das ist der einfachste Weg, eine Reihe identisch installierter virtueller Maschinen zu erstellen.
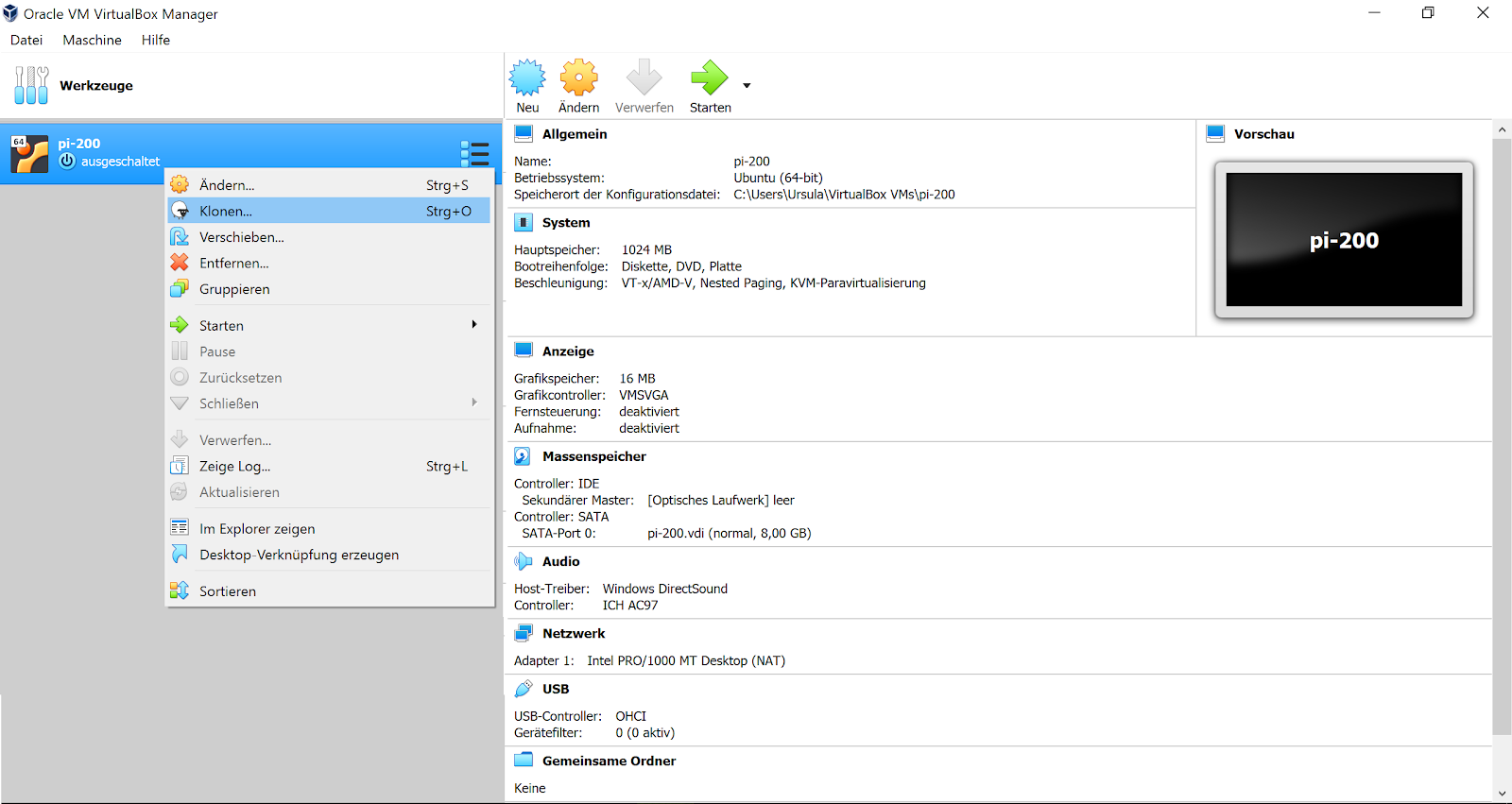
Dazu rechtsklicken wir auf den Namen der virtuellen Maschine in der linken Spalte im VirtualBox Manager. Im Kontext-Menu wählen wir “Klonen”.

Wir vergeben den Klonen passende Namen. Für das Big-Data-Labor benötigen wir mindestens 2 Klone erstellen. Wenn der Laptop es zulässt, können es auch mehr sein. Dieses Tutorial wird mit 5 virtuellen Maschinen arbeiten. Der Vorgang des Klonens wird entsprechend oft ausgeführt und die Nummerierung in der Namensgebung wird hochgezählt.
Der erste Klon erhält also den Namen: PI-201
Wir wählen die Option “verknüpfter” Klon und können dadurch Speicherplatz sparen.
Und wir lassen dem Klon neue (virtuelle) MAC-Adressen zuweisen.
Wir klicken auf Klonen und der Vorgang wird ausgeführt.
Das wird wie oben ausgeführt, mehrfach wiederholt. Dabei vergeben wir der Reihe nach die Namen, die wir im Kapitel “Vorbereitung: Server Namen” ausgewählt haben.

Um die Administration zu vereinfachen, fassen wir die virtuellen Maschine in eine Gruppe zusammen.
Dazu selektieren wir sie in der linken Spalte des VirtualBox Managers und rufen mit der rechten Maustaste das Kontext-Menu auf.
Hier wählen wir die Funktion “Gruppieren” aus.
Rechtsklick auf den Gruppennamen zeigt ein Kontextmenu. Hier erhalten wir die Möglichkeit, die Gruppe zu benennen. Beispielsweise “Big Data Labor”

Wir können eine Gruppe auswählen und auf Starten klicken. Der Virtual Box Manager startet dann alle virtuellen Maschinen der Gruppe.
Das Stoppen funktioniert analog.
Netzwerktopologie für das Cluster aus virtuellen Maschinen
Das folgende Bild visualisiert die Netzwerktopologie, die wir mit den virtuellen Maschinen errichten werden.

Netzwerktopologie des virtuellen Big-Data-Clusters
Üblicherweise liegt zwischen dem Internet und dem hausinternen LAN eine Router mit einer Firewall. Der Laptop verbindet sich mit dem hausinternen LAN und erhält üblicherweise eine dynamische IP Adresse.
Die VirtualBox errichtet auf dem Laptop auch eine virtuelle Firewall mit einem DHCP-Router. Die virtuellen Maschinen verbinden sich mit dieser NAT Schnittstelle.
Wie geht es weiter? Cluster aus virtuellen Maschinen
Klone die virtuelle Maschine, so dass du mindestens zwei Instanzen hast. Je mehr desto besser. Ein Laptop mit den genannten Ressourcen kann auch fünf oder mehr virtuelle Maschinen gleichzeitig starten.
Das Laptop wird dadurch ziemlich stark ausgelastet. Auch hier: Probieren geht über Studieren – letztendlich ist die Anzahl möglicher Instanzen eine Frage der freien Kapazitäten auf dem Laptop.
Das Tutorial dieser Seite ist ein Auszug aus dem ausführlichen Schritt-für-Schritt-Tutorial: Cluster aus Virtuellen Maschinen.

































