“Trade-Offs der Real-Time Analyse großer Datenströme”
Von der Theorie zur Anwendung
Von der Theorie zur Anwendung

Die Anforderungen an eine Enterprise Search sind schnell spezifiziert: Wir wollen eine Suchmaske mit einem Eingabefeld, einer Vorschlagsfunktion während des Tippens und einer Ergebnisliste, in der das wichtigste Dokument zuoberst steht.
Wir sind verwöhnt von Google und Co. Die Messlatte für die Standards liegt hoch. Jahrzehntelange Forschung und Entwicklung stehen hinter diesen Suchsystemen.
Wer eine Enterprise Search aufbauen will, muss sich auf eine längere Entwicklungszeit einstellen.
Der Aufbau einer Unternehmensweiten Suche ist mehr als ein Integrationsprojekt. Dokumente liegen in unterschiedlichen Systemen und sollen mit wenigen Klicks in einer einfachen Suchmaske auffindbar sein. Natürlich steht das beste Dokument ganz oben in der Trefferliste und die Trefferliste ist maßgeschneidert auf den Suchenden.
Ein ehrgeiziges Projekt. Hier die wichtigsten Aspekte, die es zu beachten gilt:
Qualität des Suchsystems
Erwartungen der Zielgruppen
Vertrauliche Daten in der Enterprise Search
Datenquellen und Mengengerüst
Suchsystem Lizenzierung
Architektur der Enterprise Search Plattform
Aufbau der Enterprise Search und Tuning
Ranking
Infrastruktur und Aktualiserungen
Laufender Betrieb und Unterhalt
Fazit
Die Erwartungen sind einfach:
“Ein gutes Suchsystem liefert mir das, was ich suche”.
Im Umkehrschluss: Liefert ein Suchsystem keine brauchbaren Ergebnisse, dann ist das System unbrauchbar. Und das gilt für jeden User und für jede Suchfrage.
Bei der Entwicklung einer Enterprise Search Plattform lohnt es sich, von Anfang an die Erwartungen der Zielgruppen abzuholen.
Gerade in einem größeren Unternehmen gibt es mehr als eine Zielgruppe. Diese richten sich nach dem Aufgabengebiet der Mitarbeitenden und nach deren Informationsbedarf.
Idealerweise werden noch vor Projektstart ausgewählte Vertreterinnen und Vertreter der einzelnen Zielgruppen ihre Erwartungen aufschreiben.
Und idealerweise wird diese Gruppe während des Projekts nach jeder Iteration gezielt Feedback zum Suchsystem geben.
Mit der Cranfield-Methode wurde dieses Vorgehen formalisiert und wird gerne in erfolgreichen Projekten angewendet. Denn ein Suchsystem ist dann gut, wenn es die Fragen der Suchenden beantwortet. Wir müssen also verstehen, was und wie die Suchenden fragen und mit welchen Antworten sie zufrieden sind.
Der Aufbau eines Suchsystems ist keine exakte Wissenschaft.
Eine wichtige Frage, die zu Beginn klar sein muss:
Gibt es Dokumente mit eingeschränkten Leserechten? Falls ja, dann ist diesem Merkmal besondere Beachtung zu schenken:
Ein solches Dokument darf nicht in der Trefferliste für alle sichtbar erscheinen.
Auch die Information, dass ein Dokument mit einem bestimmten Titel überhaupt existiert, ist eine Information.
Die Dokumente liegen oft verstreut auf vielen unterschiedlichen Systemen. Sharepoint, Confluent, Filesysteme, CMS-Systeme, Document Management Systeme, Archivsysteme – der Phantasie sind keine Grenzen gesetzt.
Es lohnt sich, zu Projektstart, eine Liste zu erstellen mit
Diese Liste wird helfen, ein passendes System zu evaluieren.
Im Verlauf des Projekts werden die Dokumente aus allen Systemen ausgelesen . Die Enterprise Search Plattform braucht Zugriff auf alle Systeme und muss mit einer Vielzahl von Authentifizierungsmechanismen zurechtkommen.
Auch erwarten wir, dass die Suchmaschine mit den Änderungen der Dokumente synchron ist.
Je nach Quellsystem wird diese Herausforderung anders zu lösen sein.
Make or Buy – diese Entscheidung muss gefällt werden.
Jeder Hersteller von Enterprise-Search Plattformen wird mit einem anderen Zauberkasten antreten und jeder Hersteller muss mit unserer Systemlandschaft zurechtkommen.
Entschließt man sich, die Suchplattform weitgehend selbst zu bauen, dann wird man dennoch nicht bei Null anfangen.
Man wird ein Suchsystem lizenzieren und in die eigene Systemlandschaft integrieren. Je nach Lizenzmodell wird die Datenmenge eine Rolle spielen.
Oder man basiert auf einem Open Source System – wie Apache Solr.
Dieses System wird seit 2006 von einer regen Community ständig weiterentwickelt. Es basiert auf der Open Source Library Apache Lucene.
Diese ist sehr bewährt und beliebt und wird gerne als Herzstück einer Suchmaschine verwendet.
Bleiben wir bei Apache Solr als Beispiel einer Suchmaschine, die wir als Herzstück unserer Enterprise Search Plattform einsetzen können.
Solr kommt mit einer Indexierungskomponente und mit einer Suchkomponente. Beide sind unglaublich flexibel konfigurierbar.
Es gibt Features für nahezu alle Anforderungen.
Reicht das nicht aus, dann können wir eigene Features dazu programmieren.
Die Lucene/Solr Community ist sehr aktiv und erweitert den Umfang laufend um die neuen Features, die dank KI möglich werden.
Die Indexierungskomponente baut den Invertierten Index und die Suchkomponente fragt diesen ab.
Je mehr Features wir konfigurieren und je mehr Dokumente wir Indexieren, umso größer wird der invertierte Index.
Früher als uns lieb ist, werden wir in die Big Data Welt, also in die Welt des verteilten Rechnens katapultiert, und war auch dann, wenn die Quelldokumente im Quellsystem bleiben und die User der Enterprise Search Plattform bei Klick auf einen Treffer das Dokument aus dem Quellsystem lesen.
Das folgende Diagramm zeigt die Architektur einer Enterprise Search.

Die Dokumente werden aus den einzelnen Quellsystemen abgeholt.
Sie werden in dasjenige Format transformiert, das Solr als Input verwendet. Das ist ein einfaches XML- oder JSON-Format. Pro Dokument definieren wir einzelne Suchfelder. Hier fängt das Index-Design schon an.
Je zielgenauer die Suchmaschine sein soll, desto raffinierter werden wir dieses Format strukturieren und desto aufwändiger wird diese Datenkonvertierung.
Die konvertierten Daten werden von Sorl zur Indexierung eingelesen. Wir konfigurieren, mit welchen Features indexiert und später gesucht wird.
Im Produktivbetrieb werden wir dafür sorgen, dass Änderungen an den Dokumenten in den Quellsystemen zeitnah indexiert werden.
Die Suchoberfläche sieht nur auf den ersten Blick einfach aus. Unter der Haube werden die User-Eingaben in Suchanfragen umgewandelt, die zum Index passen und die Features ausreizen.
Viel Aufmerksamkeit schenken wir dem Ranking: Wir sorgen also dafür, dass das relevanteste Dokument zuerst in der Trefferliste erscheint.
Heute gängig und erwartet: personalisierte Suchen – also ein Ranking, das sich nach dem Suchenden richtet.
Das ist viel Arbeit. Und mit jeder Datenquelle, die wir dazu nehmen, werden wir neue Erkenntnisse gewinnen.
Das Suchsystem wird schrittweise aufgebaut.
Jedes Quellsystem muss analysiert werden.
Die Struktur des Suchmaschinen Indexes wird ebenfalls schrittweise entwickelt. Zu Beginn wird man kaum die perfekten Entscheidungen treffen und muss das Design immer wieder überdenken.
Daten werden in den Quellsystemen abgeholt und konvertiert in ein Format, das von der Suchmaschine indexiert wird.
Vielleicht gibt es einen Konnektor, der das Suchsystem direkt mit dem Quellsystem verbindet und vielleicht funktioniert dieser sogar out-of-the-box und lässt sich nach unseren Anforderungen konfigurieren.
Falls nein, dann erstellt man diesen Prozess selbst. Python ist eine mächtige Sprache mit vielen guten Libraries, die uns die Arbeit erleichtern.
Das Tuning der Suche ist aufwändig und spannend. Immerhin soll die Suchmaschine nicht einfach ein Ergebnis liefern, sondern zielgenau den besten Treffer an erster Stelle zeigen.
Nicht nur das Index-Design selbst, sondern auch die Erschließung der Daten im Index wollen entwickelt werden.
Die grundlegendsten Schritte kommen in jedem Suchsystem standardmäßig mit:
Das ist der erste Schritt. Jetzt vergleichen wir die Erwartungen der Testuser mit den Ergebnissen.
Das Vorgehen können wir so standardisieren, dass wir nach jedem Optimierungsschritt aufgrund der von den User erwarteten Dokumente und vom Suchsystem gefundenen Treffer den F1-Score berechnen.
Dieser wird mit der out-of-the-box Konfiguration eher im niedrigen Bereich sein. Vielleicht bei 0,2 von 1,0.
Wobei wir 1,0 nicht erzielen wollen, weil wir damit das Suchsystem “overfitten”, also auf die Testuser und deren Fragen trimmen und alles andere außer Acht lassen.
Das erste Tuning wird sich mit der Frage befassen, ob jeder dieser Schritte verbessert werden kann. Beispiele:
Nach dem Tuning bauen wir den Index neu und errechnen den F1-Score neu.
Dieser wird stetig wachsen. Sinkt er, dann haben wir einen guten Hinweis, dass der letzte Optimierungsschritt nicht die erwarteten Ergebnisse brachte.
Nach und nach werden wir weitere Features einbauen. Hier eine Liste gängiger Möglichkeiten:
Es ist geschafft – wir vertrauen unserem Suchsystem und wollen eine erste Version ausrollen und einem ausgewählten Benutzerkreis zur Verfügung stellen.
Suchmaschinen Indexe werden sehr groß. Wir werden sehr viel Platz benötigen, sowohl Festplatte als auch RAM.
Und sehr wahrscheinlich werden wir mit einem verteilten System arbeiten, weil die schiere Menge der Daten nicht auf einem Rechner Platz hat.
Wir sollten uns schon lange bei Projektstart mit dem Aspekt der Infrastruktur befassen und in einer sehr frühen Projektphase berechnen, ob die Größe des Suchmaschinenindexes ein verteiltes System benötigt.
Ob wir damit in die Cloud gehen wollen? Auch diese Frage muss abgewogen werden.
Vielleicht kommt gar ein Real-Time-Aspekt dazu – und wir wollen Änderungen an Dokumenten sofort im Index nachführen.
Unternehmensweite Suche – die Anforderungen sind schnell formuliert. Der Aufbau eines Suchsystems jedoch ist sehr anspruchsvoll und aufwändig und benötigt vielfältige Skills.
Jedes System muss gepflegt werden. Verteilte Systeme sind aufwendiger.
Die Daten müssen aktuell gehalten werden – vielleicht sogar in Echtzeit.
Die Texte und Dokumente werden von Menschenhand erstellt und der Kreativität sind keine Grenzen gesetzt.
Wir brauchen Qualitätssichrungsmechanismen die bemerken, wenn neue Formate erfunden wurden, die in der Datenkonvertierung noch nicht erkannt werden.






















[easy-social-share]
Da geh’ ich lieber in die Cloud, da ist alles schon vorhanden” – die Vorstellung ist verlockend:
Nie mehr installieren, deployen, upgraden, administrieren und sich ausschließlich aufs Wesentliche konzentrieren.
Einige kritische Gedanken zum Sog in die Cloud.
Cloud ist nicht gleich Cloud
Daten sammeln und analysieren
Herausforderung Infrastruktur
Cloud-RZ – eine Herkulesaufgabe
Netzwerk im Cloud-RZ
Server im Cloud-RZ – langfristig denken
Software in der Cloud
Cloud für Data Analytics
Eigene Server in der Cloud
Cloud-Plattform mieten
Software für Data Analytics in der Cloud
Die Cloud bringt neue Berufe
Fazit
Da gibt es Hyperscaler, wie Google, Amazon, Azure, Alibaba – habe ich einen ausgelassen?
Und so wie es am Himmel nicht nur große Wolken gibt, so gibt es in der Cloud auch kleine Anbieter. Das Angebot ist so vielfältig wie die Wolkenformationen am Himmel.
Oft wird unterschieden zwischen IaaS, PaaS und SaaS. Dabei bedeutet “aaS” so viel wie “as a Service” – gemeint ist der Service des Cloud-Anbieters.
Also Infrastruktur (I), Platform (P), Software (S) as a Service.
Und weil’s so schön tönt, sind ganz viele neue aaS dazu gekommen: DBaaS (Datenbank), DaaS (Desktop), FaaS (Function), RaaS (Robot) – der Fantasie sind keine Grenzen gesetzt.
Bleiben wir bei den Daten,schließlich geht’s hier um Data Engineering und Analytics.
Noch vor zehn Jahren hieß es: “Sammle jetzt Daten und werte sie später aus”.
Diese Sammelwut führte zu Datenfluten.
Jetzt gehen wir dazu über, gezielt Daten zu sammeln und auszuwerten. Wir hoffen, die Fluten so einzudämmen.
Mittlerweile haben wir ja auch bessere Tools und gereiftere Erkenntnisse über unsere Anforderungen und Möglichkeiten.
Doch ein Faktor ist oft eine Spaßbremse: Die Infrastruktur.
Wo lagern wir all die Daten? Und wie können wir aus diesen Daten innert nützlicher Frist Erkenntnisse gewinnen?
Wir denken an große Datenmengen und diese benötigen viel Speicherplatz und schnelle Maschinen. Verteiltes Rechnen ist angesagt und dazu benötigen wir Rechenzentren (RZ).
Ein RZ zu organisieren ist anspruchsvoll: Je nach Größe reicht ein Raum oder man benötigt ein ganzes Gebäude.
Zur Risikominimierung möchten wir vielleicht alles redundant halten – also zwei Gebäude, identisch ausgestattet, am besten an unterschiedlichen Standorten.
Eine Herkulesaufgabe – noch bevor wir den ersten Server aufstellen.
Server stapeln wir in Racks, diese sind verkabelt mit Strom und Internet. Das Rechnernetzwerk mit Swiches und Routern muss sorgfältig geplant und ausfallsicher konzipiert werden.
Ist es aufgestellt, dann können wir endlich Server aufstellen, verkabeln und in Betrieb nehmen.
Wie werden wir in ein paar Jahren vorgehen, wenn die Server veraltet sind und ausgetauscht werden sollen?
Ein Konzept dazu sollten wir in der Tasche haben und austesten, bevor wir produktiv gehen.
Jetzt können wir anfangen, an die Software zu denken:
Betriebssysteme, Cluster-Management und die eigentliche Software: Verteilte Filesysteme, Datenbanken, Analytics Engines. Je nachdem, was wir vorhaben.
Und wie gehen wir vor, um neue Releases der Software einzuspielen?
RZ herunterfahren, Release einspielen, Daten migrieren, austesten und RZ hochfahren?
Das war so im letzten Jahrhundert – heute ist 7×24 angesagt, unterbruchsfrei und selbstverständlich mit den neuen Releases.
Wir mieten beispielsweise nur die RZ-Infrastruktur und wir bringen eigene Server.
Dann sind wir auch selbst verantwortlich für den Unterhalt der Server. Das ist beruhigend, denn die Server gehören uns selbst: wenn wir Cloud-Anbieter wechseln wollen, dann ziehen wir um mit den Servern, bauen sie auf beim neuen Anbieter.
Ein gigantischer Akt – immerhin soll unsere Dienstleistung 7×24 zur Verfügung stehen.
Stoppen wir hier und denken wir wieder über die Cloud für Data Analytics nach.
Beim Hyperscaler gibt es alles einzukaufen:
Nur die Infrastruktur, oder die Plattform oder gar fix fertig konfigurierte Systeme.
Kleinere Player bieten einen Teil der Palette an und glänzen mit kundennahem Service.
Oder wir mieten die Plattform: Dazu können wir bei vielen Anbietern wählen, ob wir ganze Server oder einzelne virtuelle Maschinen haben wollen. Selbstverständlich mit dem Betriebssystem unserer Wahl und ans Internet angebunden. Auf der Plattform deployen wir unsere Software selbst und lagern unsere Daten.
Und wenn wir eines fernen Tages den Anbieter wechseln wollen? Dann mieten wir halt unsere Server beim neuen Anbieter, installieren dort unsere Software und transferieren unsere Daten.
Das können wahre Datenfluten sein.
Und den Transfer lassen sich die Anbieter zahlen, besonders gut, beim ausgehenden Transfer.
“Da geh’ ich lieber in die Cloud, da ist alles schon vorhanden” – bei näherem Hinschauen ein Trugschluss:
Ja, es ist vieles vorhanden, doch es entbindet uns nicht davon, die Zusammenhänge zu begreifen.
Ob Arbeit und Kosten tatsächlich weniger werden, muss sorgfältig evaluiert werden.
Die Preislandschaft und das Wording sind nicht normiert – ein genauer Vergleich ist schwierig.
Dennoch – der Trend in die Cloud wird zum Sog in die Cloud.
Die Cloud wird uns zunehmend beschäftigen.
Eine Komponente sind die Personalkosten – der Cloud-Anbieter nimmt uns Vieles ab und zahlt die Spezialisten selbst. Und wir zahlen den Cloud-Anbieter.
Nicht umsonst gibt es jetzt Cloud-Engineers, also Spezialistinnen und Spezialisten, die für ein Unternehmen die Cloud organisieren.
Eine wachsende Zahl von Zertifizierungslehrgängen bereichern die Wahlmöglichkeiten – Gerade bei den Hyperscalern, deren Cloud-Angebot so unüberschaubar vielfältig ist, dass man einen Lehrgang absolviert, um sich darin zurechtzufinden.
Oder wir mieten die Software, fix fertig konfiguriert, einsatzbereit, und mit Security-Groups abgesichert. Dabei denken wir an Umgebungen für Development, Integration und Produktion.
Die Daten lagern wir ebenfalls in der Cloud.
Auch in dem Szenario bedeutet ein Anbieterwechsel einen kostspieligen Datentransfer.
Und sämtliche unsere Programme müssen migriert und getestet werden. Es wäre ein Riesenzufall, wenn der neue Anbieter exakt dieselbe Software und dieselbe Konfiguration anbieten würde, mit der wir unsere Programme, Skripte und Auswertungen entwickelt haben.
Cloud-Anbieter und Cloud-Strategie auswählen und Cloud-Lösung implementieren, das sind anspruchsvolle Aufgaben. Sie sind sorgfältig zu planen und zu evaluieren.
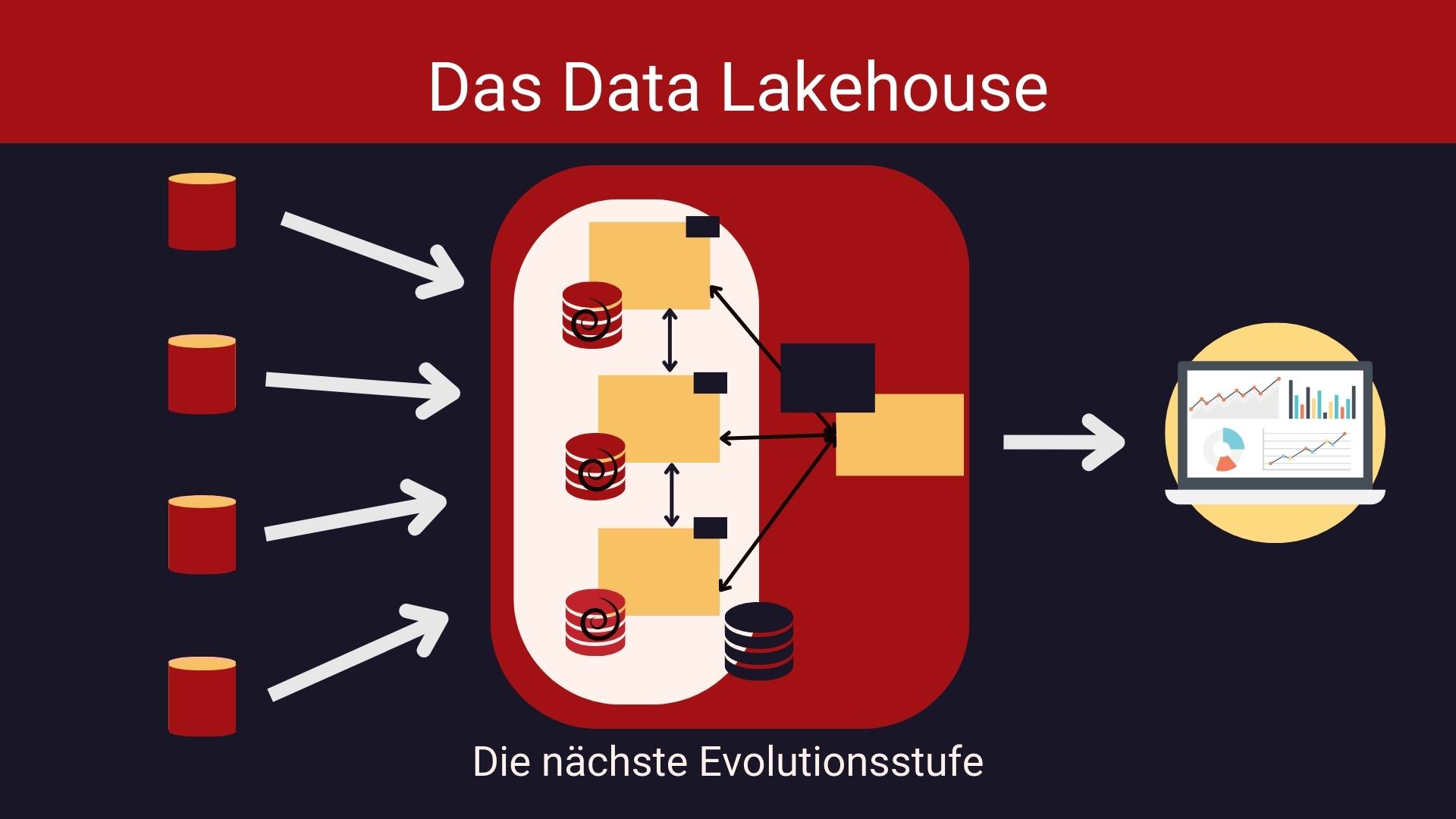
Data Lakehouse: Die Bezeichnung ist eine Zusammensetzung aus Data Warehouse und Data Lake, denn diese beiden Konzepte standen Pate. Date Lakehouses eröffnen ungeahnte Perspektiven.
Data Warehouses (DWH) sind ein wichtiges Werkzeug für der Data Analysts. Aus verschiedenen Systemen werden Daten extrahiert, in ein vordefiniertes Format transformiert und danach ins DWH geladen. ETL – so heißt diese Verarbeitungskette also extract-transform-load.
Data Warehouses wurden in den 90er Jahren modern. Ein Data Warehouse ist optimiert für die Analyse wohl-strukturierter Daten.
Ziel der Datentransformation ist das Star-Schema mit Fakten und Dimensionen. Sind die Daten sauber vereinheitlicht, dann gelingen die wertvollsten Datenanalysen.
Aus den 90ern stammen auch die Grenzen der DWHs: Sie skalieren vertikal. Die Festplatte wächst mit dem Datenvolumen. RAID-Systeme helfen, die Festplattenkapazität zu vergrößern.
Doch was tun, wenn selbst das RAID-System an seine Grenzen stößt?

Nicht zuletzt dank des WWW brachen Daten in Fluten über uns her und schwemmten neue Technologien zum Speichern und Analysieren an: verteilte Daten Systeme, wie beispielsweise HDFS, das Hadoop Distributed Filesystem.
Ein Data Lake – das ist die Bezeichnung für die Menge der Daten in einem verteilten Big-Data-Filesystem.
Vergleichbar mit allen Daten auf unserem Laptop, aber halt in Big-Data-Dimension.
Zu Beginn der 10er Jahre lautete das Credo: Zuerst sammeln, dann analysieren. Die Fluten fassen, was wir damit tun, finden wir später heraus.
Es entstanden neue Tools, um Daten in verteilten Systemen zu analysieren. Das Spezielle an den Tools:
Die Programme werden zu den Daten getragen – die Analyse wird verteilt auf die einzelnen Rechner des verteilten Systems. Grundlage ist MapReduce. Hochkomplexe Systeme – entwickelt von tragfähigen Open Source Communities.
Apache Spark ist ein gutes Beispiel:

Bei jeder Datenanalyse werden die Rohdaten zuerst transformiert und danach analysiert.
Es sind hochkomplexe Systeme und mittlerweile werden sie gerne dort eingesetzt, wo riesige Datenmengen schnell analysiert werden.
Es gibt eine ganze Reihe von Tools, die auf verteilten Systemen arbeiten. In den letzten 10 Jahren wurden sie laufend perfektioniert und die Reise ist noch nicht zu Ende.
Doch die Realität holt uns auch hier ein: zuverlässige Analyseergebnisse erzielen wir nur auf sauber bereinigten Daten. In einem Data Lake werden die Daten immer wieder transformiert – ein unnötiger Overhead.
Die Verarbeitungskette heißt jetzt ELT – extract-load-transform: Man hole die Daten aus dem Quellsystem, lade sie zuerst in den Data Lake und transformiere sie on demand für die jeweilige Analyse und das immer wieder für jede Analyse.
Der Bedarf ist erkannt: Data Lakes haben zu wenig Struktur, wir benötigen ähnliche Eigenschaften wie bei Data Warehouses:

Anders als ETL in klassischen Data Warehouses wird ELT in Data Lakes/Data Lakehouses gar in Echtzeit ermöglicht: Analyse Ergebnisse liegen also nahezu sofort vor. Und wir sind nicht beschränkt auf SQL sondern können Machine Learning Modelle nahtlos einbinden.
Data Lakehouses ist also nicht einfach alter Wein in neuen Schläuchen. Die Tabelle zeigt die markantesten Unterschiede:
| Klassisches Data Warehouse |
Data Lakehouse | |
|---|---|---|
| Skalierbarket | vertikal (RAID) | horizontal – verteilte Filesysteme |
| Datenvolumen | GB-TB | TB – PB – ZB |
| Datenformat | proprietär | offen |
| Analytics Engine | proprietär – auch SQL | Open Source – auch SQL |
| Machine Learning (KI) | nein | ja |
| Echtzeit ETL / ELT | nein | ja |
| Technologische Reife | hoch | jung – in Entwicklung |
Die Grenzen verwischen – das Wording ist unklar – was beispielsweise ist ein Cloud Data Warehouse? Die Marketing Abteilungen sind kreativ.
Die wichtigste Eigenschaft: Data Lakehouses arbeiten mit offenen Dateiformaten. Sind die Daten einmal transformiert, beispielsweise in ein Parquet-Format oder ein Delta Lake-Format, dann sind viele unterschiedliche Tools in der Lage, sie zu analysieren.
Offene Systeme sind gefragt. Und so entstehen neue Cloud Dienstleistungen mit den folgenden Eigenschaften.
Dem Data Lake werden also Data Warehouse Eigenschaften verpasst und so entsteht ein Data Lakehouse.
Ein neuer Schub an Entwicklungen steht uns bevor.
Und da alles Cloud basiert ist, soll es einfach werden, mit einem Klick und gezückter Kreditkarte den Service eines anderen cloudbasierten Providers auf den wohlpräparierten Daten im Lakehouse wirken zu lassen.
Beispielsweise das ultimativ gute Machine Learning Modell eines anderen Cloud Anbieters.

Funktionale Programmierung hat einen enormen Auftrieb erfahren. Der Grund: Datenanalyse auf verteilten Filesystemen, wie HDFS, basiert auf funktionaler Programmierung. Erst damit wurde Big-Data-Analyse überhaupt möglich.
Was macht funktionale Programmierung aus? Hier ein ganz einfaches Beispiel in Python.
Wer will, kann gleich abtippen im Online-Playground.
Die Kernidee: In der Parameterliste einer Funktion darf eine Funktion stehen.
Zur Erinnerung die Eigenschaften einer Funktion:
Die letzte Eigenschaft unterscheidet die Funktion von einer Prozedur in der prozeduralen Programmierung und von einer Methode in der objektorientierten Programmierung – diese brauchen nicht unbedingt einen Wert zurückzugeben.
Wir stehen also vor zwei Herausforderungen:
Python ist eine flexible Sprache – mit vielen Funktionen, aber auch mit objektorientierten Elementen. Und so sind viele praktischen Features als Methode eines Objekts implementiert und andere wiederum als Funktion. Den Unterschied merken wir beim Aufruf der bei einer Funktion anders erfolgt als bei einer Methode.
Das Beispiel zeigt es: Wir zählen die Wörter in einem String.
Dazu zerhacken wir zuerst den String in einzelne Wörter.
Die wunderbare Methode split() erfüllt die Aufgabe:
text = 'Hello World' text.split()
Ausgabe ist die Liste. Die Elemente einer Liste werden in Python ja von eckigen Klammern umschlossen.
['Hello', 'World']
Python ist ja interpretiert und nicht typsicher. Der Interpreter ist Weltmeister im Ausknobeln des passenden Datentyps. Das macht den Code schlank und erlaubt es auch, in einer Shell oder eben im Online Playground, den Code unmittelbar ausführen zu lassen.
Wollen wir jetzt zählen, wie viele Wörter unser Text hat, dann hilft die Funktion len().
Das geht so:
len(text.split())
Ausgabe ist 2.
Die Funktion len() wird also auf die Liste angewendet, die durch Aufruf der Methode split() auf dem String-Objekt text resultiert.
Diese Code-Zeile ist noch nicht geeignet für die funktionale Programmierung. Wir müssen die Bezeichnung der Variablen text noch loswerden, bezeichnet sie doch das Objekt, von dem die Methode split() abhängt. Bei der funktionalen Programmierung kommen wir damit nicht weitern, diese erlaubt nur Funktionen.
splitcount = lambda x: len(x.split())
So einfach definiert man in Python einen Lambda-Ausdruck.
Der Aufruf sieht so aus und kann unabhängig vom Objekt text für alle möglichen Strings erfolgen.
splitcount(text)
Ergebnis ist 2.
Jetzt sind wir bereit für funktionale Programmierung. Wir haben eine Funktion splitcount, die das gewünschte Verhalten aufweist: Wir haben eine Funktion, die wir auf beliebige Strings anwenden können.
Zur Vorbereitung: Wir wollen wiederum Wörter zählen, doch diesmal die Wörter mehrer Strings, die in einer Liste zusammengefasst sind.
textliste = ['Fischers Fritz', 'fischt frische Fische']
Python macht es uns einfach, die eckigen Klammern umschließen die Elemente der Liste – in diesem Beispiel sind es zwei Strings.
Und jetzt – Magie:
map(splitcount, textliste)
Die Python-Funktion map erwartet als ersten Parameter eine Funktion – zu dem Zweck haben wir ja splitcount vorbereitet.
Als zweiten Parameter erwartet sie eine Collection, also beispielsweise eine Liste.
Und map wendet jetzt die Funktion auf jedes Listenelement an.
Ergebnis ist die folgende Liste – sie enthält die Anzahl der Wörter der beiden Strings in der Liste textliste:
[2, 3]
Bemerkung am Rande für alle, die abtippen: das Ergebnis wird erzielt mit list(map(splitcount, textliste)) – ohne Cast auf eine Liste erhalten wir nur ein Iterable.
Wir können auch das Gesamtergebnis ermitteln und die Wörter insgesamt zählen.
Dazu benötigen wir eine Funktion, die zwei Elemente zusammenzählt.
Nichts leichter als das:
addiere = lambda x, y: x + y
Das Lambda erledigt den Job. Wir kontrollieren
addiere(1, 2)
Das Ergebnis ist 3.
Und jetzt wieder ein Trick aus der funktionalen Programmierung. Es versteckt sich in der Python3-Library functools, die wir zuerst importieren
import functools as f
Und jetzt können wir reduce anwenden. Diese Funktion erwartet als ersten Parameter eine Funktion, die zwei Parameter nimmt. Dazu haben wir den Lambda-Ausdruck addiere vorbereitet.
Der zweite Parameter von reduce ist eine Collection – also das Ergebnis von map(splitcount(texte)).
f.reduce(addiere, map(splitcount, textliste))
Ergebnis ist 5.
Das MapReduce Programmierkonzept ist Kernstück der Datenanalyse auf verteilten Systemen.
MapReduce ist ein Programmierkonzept, das bei verteiltem Rechnen zum Zuge kommt. Es bedient sich des funktionalen Programmierparadigmas.
Das MapReduce-Programm im Bild zählt Wörter im Text. Dazu zerlegt der Split-Step den Text in Blöcke. Der Map-Schritt wird für jeden Block gleichzeitig ausgeführt und filtert Hinblick auf die Programmlogik die Input-Daten. Hier wird pro Wort ein Schlüssel-Wert-Paar ausgegeben. Der Wert ist 1, was sich aus dem Ziel der Analyse ergibt.

Sind alle Map-Schritte beendet, dann wird der Shuffle/Sort-Schritt ausgeführt. Sortiert sammelt die Zwischenergebnisse der Map-Steps zusammen und sortiert sie nach Schlüssel.
Danach werden neue Blöcke gebildet und zwar ein Block pro Schlüssel-Wert. Die Reducer-Logik kann für alle Blöcke wiederum zeitgleich erfolgen.
Im Bild werden die 1en addiert und damit die Wörter gezählt.
Danach wird das das Endergebnis zusammengestellt und ans aufrufende Programm zurückgegeben.
Google hat dieses MapReduce-Framework für verteilte Systeme patentieren lassen.
SQL wird uns als deklarative Abfragesprache noch lange erhalten bleiben. SQL ist hervorragend geeignet für die Datenanalyse – alle Informatikerinnen und Informatiker kennen SQL.
Bei der Datenanalyse mit SQL stehen Aggregatsfunktionen im Mittelpunkt. Hier ein Beispiel:
| ID | Kunde | Land | Umsatz |
|---|---|---|---|
| 1 | Meyer | CH | 20 |
| 2 | Müller | DE | 10 |
| 3 | Muster | CH | 40 |
| 4 | Berger | DE | 50 |
| 5 | Huber | AT | 60 |
Wir analysieren die Umsatztabelle und wollen den Umsatz pro Land ermitteln:
select land, sum(umsatz) from umsatztabelle group by land
Diese Abfrage können wir ein ein MapReduce-Programm umwandeln.
Die Daten in Blöcke aufspalten – der erste Schritt – kommt in einem verteilten Filesystem wie HDFS gratis. Die Daten liegen dort schon in Blöcke aufgespalten vor.
Input für den Map-Schritt sind einzelne Zeilen – das Framework ist entsprechend gebaut.
Pro Zeile berücksichtigen wir für unser Beispiel nur das Land und den Umsatz. Die anderen Felder tragen ja nicht bei zur Beantwortung der Analyseaufgabe.
Der Map-Schritt gibt also pro Zeile ein Schlüßel-Wert-Paar zurück:
Land -> Umsatz
Auch der Shuffle/Sort-Schritt braucht uns nicht zu kümmern. Das Framework über nimmt den Schritt und sammelt alle Schlüssel-Wert-Paare die alle Mapper errechnet haben, zusammen, sortiert sie, nach Schlüssel, bildet Pakete und zwar eines pro Schlüsselwert.
AT 60 CH 40 CH 20 DE 10 DE 50
Das Framework schickt jedes Paket so gebildete Paket zu einem Reducer. Gleich wie den Mapper, entwerfen wir auch den Reducer, so dass das Analyseziel erreicht wird.
In unserem Fall zählen wir alle Werte zusammen und geben je ein zur Aufgabenstellung passendes Schlüssel-Wert-Paar zurück.
AT 60 CH 60 DE 60
Das Framework sammelt diese Ergebnisse und stellt sie zu einem Endergebnis zusammen.
Für komplexere Analysen, beispielsweise mit Joins, werden wir mehrere Mapper und je nachdem auch mehrere Reducer programmieren und zu einer geeigneten Abfolge zusammenstellen.
Kein Datenanalyst wird produktiv sein, wenn er zuerst seine Logik in MapReduce übersetzen muss. Doch das ist auch gar nicht nötig.
Moderne Big-Data Tools übernehmen diese Übersetzung. Als Analysten überlegen wir SQL und das Framework generiert daraus die passenden Analyse-Jobs und führt sie über dem verteilten System aus.
Funktionale Programmierung einerseits und das MapReduce-Framework andrerseits legten das Fundament für die moderne Datenanalyse in verteilten Filesystemen. Die Entwicklungen sind noch nicht zu Ende und laufen in Richtung Echtzeitanalyse und praktische Tools zur Bedienung dieser hochkomplexen Systeme.